加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
目标检测,简而言之就是检测出图像中所有感兴趣的物体,并确定它们的类别和位置,它在自动驾驶、图像理解、智慧城市等领域都有非常广泛的应用。
然而,现有的基于深度学习的目标检测方法成本甚高——需要标注每个图片/视频中的所有目标物体的类别和位置信息,这种方法也叫强监督目标检测方法。
商汤科技视频大数据研究团队提出了一种全新的基于物体实例挖掘(Object Instance Mining, OIM)的弱监督目标检测框架,只需要标注图像中出现的目标物体类别,通过算法“触类旁通”找出图像中的全部物体,并进一步确定全部目标物体的类别和位置信息。
与强监督目标检测所需的标注相比,该方法极大地降低了标注的成本,加快了算法的产品落地速度,该论文被AAAI 2020收录。
全新弱监督目标检测框架
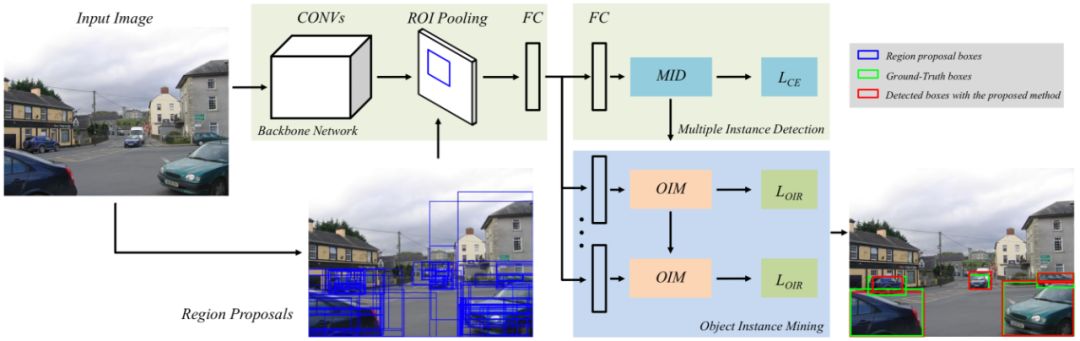
该目标检测框架主要由多实例检测(MID,Multiple Instance Detection)及目标实例挖掘(OIM,Object Instance Mining)两个部分构成,具体如下图1:
比如你输入一张图片,系统会预先提取出来潜在的物体候选框(Region Proposals,图中蓝色框),再和原图一起,送入到神经网络(Backbone Network)进行模型训练,将这些潜在的框进行分类,并分离出图中的物体和背景。
这个过程都是通过现有的MID方法实现,但这种方法的结果不够准确。
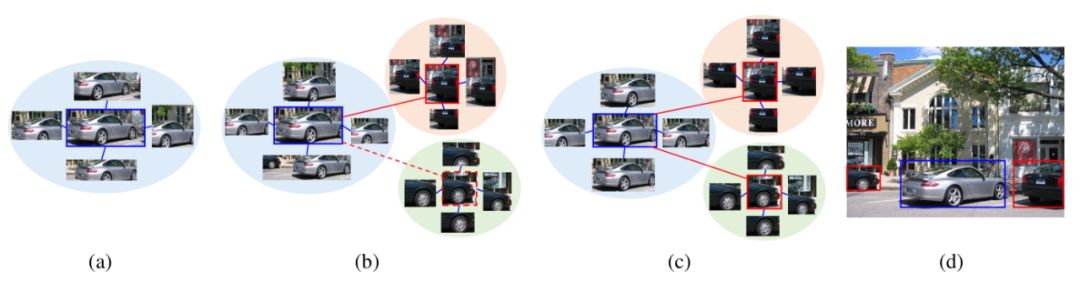
商汤研究团队在MID方法的基础上创新性地融入了OIM方法。基于候选区域的特征,OIM方法建了空间图(Spatial Graph)和外观图(Appearance Graph)。
空间图的官方解释是,基于特征最明显的候选框,通过IOU(Intersection over Union,即重叠部分)>0.5的条件,寻找与该候选框空间相似的其他候选框构成的空间图,并给这些候选框赋同样的类别信息,加入模型训练。
比如图2中的(a)就是空间图,这张图最先检测到一辆银色车,它的特征很容易被学到,对应的物体框精度也比较高,根据空间相似度,挖掘到其他含银色车的候选框。
基于外观相似度,可以计算它与其他候选框之间的外观相似度,挖掘图片中可能属于同一类别的物体实例,建立外观图,比如图b和c,通过外观相似度找到了另外两辆黑色车。
找到之后,再建立和图(a)类似的空间图——包含更多物体实例,进而不断循环,这个模型就可以识别不同类别的物体,识别越来越多的物体实例。
再把所有潜在的物体加入到网络学习过程中,就能学到更鲁棒的特征,最终输出的检测结果精度更高。
除此之外,本文还引入了物体实例权重调整损失函数(Reweighted loss),使网络可以同时学习到更完整的物体实例,从而让弱监督目标检测方法得到更加准确的检测框。
因为对于图像中的一些非刚性物体,比如人体、猫狗等,由于其局部区域非常具有辨识力(如猫脸),弱监督检测算法检测到的框可能是猫脸的框,但通过本文提出的损失函数可以学习到完整的猫,使检测结果更完整。
检测准确率行业领先
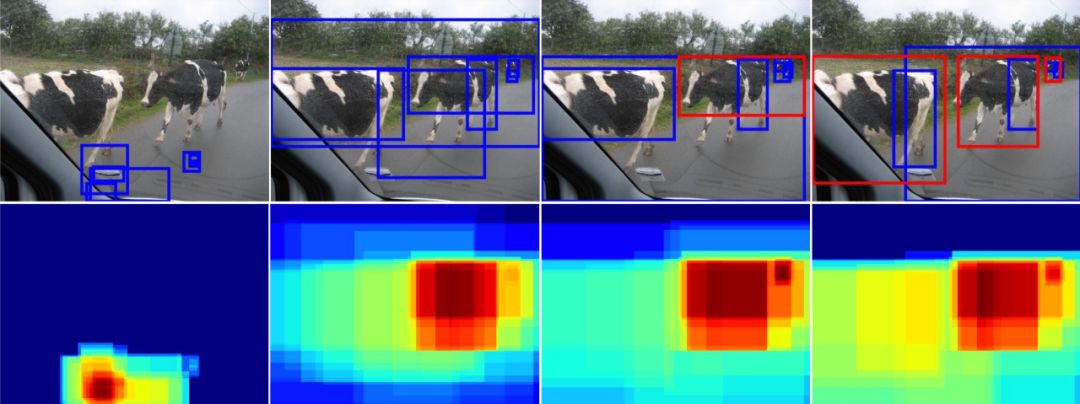
本文在PASCAL VOC 2007训练集上进行了弱监督物体实例挖掘过程的可视化,如下图3所示(从左到右),随着网络的迭代学习,更多更准确的物体实例可以被检测出来并加入训练中。
图3:目标实例挖掘过程,蓝色框是指检测不正确的框(overlap<=0.5),红色框是指正确检测到的框(overlap>0.5),下半部分是指候选框的响应及变化
图3是检测奶牛的过程,第一张第一列是随机初始化的结果,网络还没进行学习;第二列至第四列是网络迭代的不同阶段(第一个迭代, 第三个迭代,和最后的迭代),可以看出,训练到一定阶段,算法不仅能检测出所有的奶牛,而且奶牛的检测框也越来越精确。
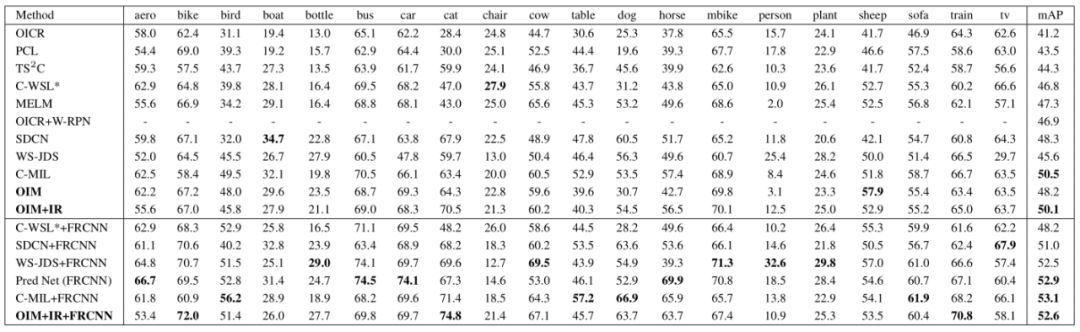
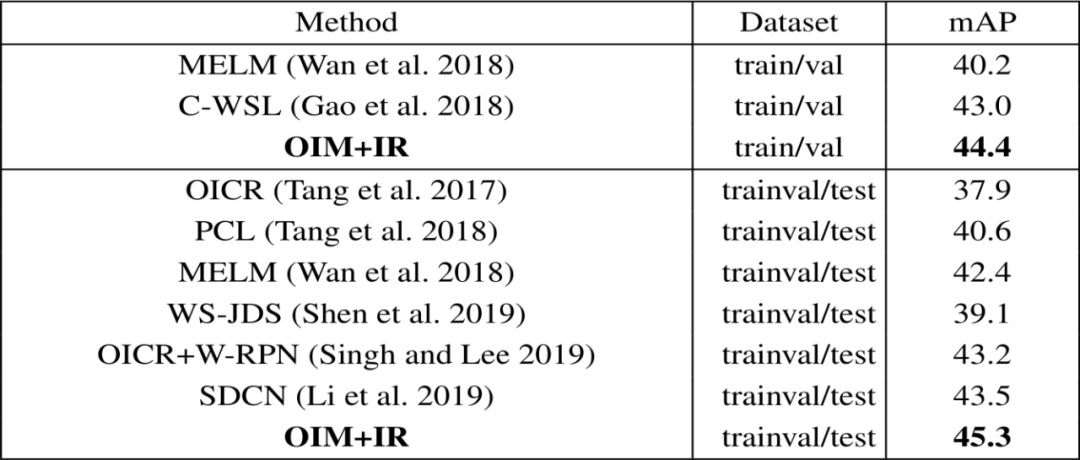
本文使用PASCAL VOC 2007及VOC 2012数据进行了测试,比较了物体实例挖掘(OIM)方法与其他弱监督检测方法的效果。
结果表明,本文提出的弱监督物体实例挖掘方法在定位精确率以及检测准确率均达到或超过目前最先进的方法。
表1:OIM与其他目前最先进的方法在PASCAL VOC 2007 测试集上检测精确度的比较(AP) (%),mAP是指平均检测精度
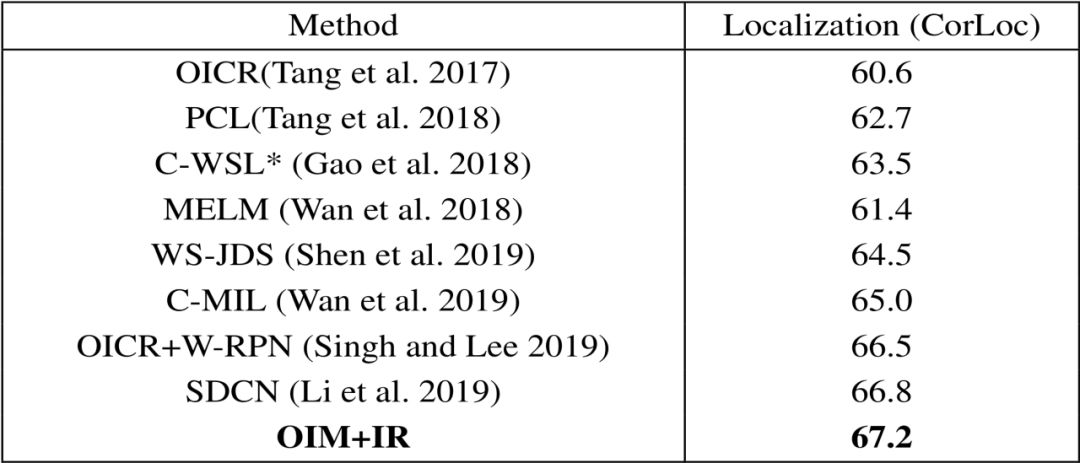
表2:OIM与其他目前最先进的方法在PASCAL VOC 2007训练验证集上定位精确度的比较(CorLoc) (%)
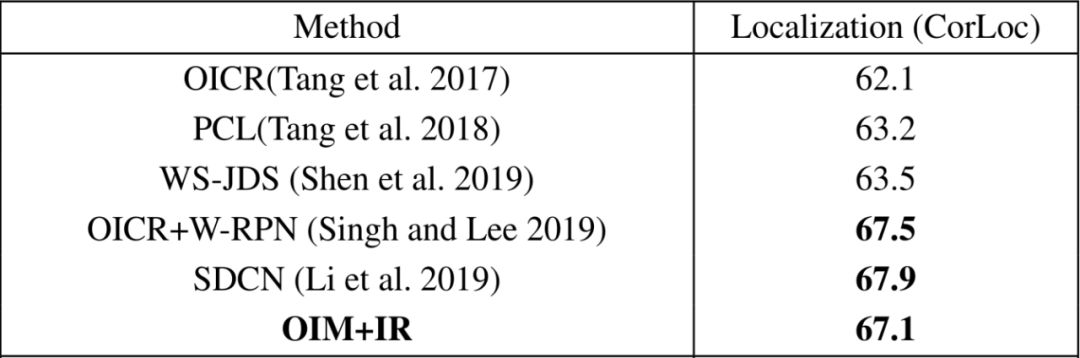
表3:OIM与其他目前最先进的方法在PASCAL VOC 2012 验证集/测试集上检测精确度的比较(AP) (%)
表4:OIM与其他目前最先进的方法在PASCAL VOC 2012训练验证集上定位精确度的比较(CorLoc) (%)
论文:Object Instance Mining for Weakly Supervised Object Detection
论文作者:Chenhao Lin, Siwen Wang, Dongqi Xu, Yu Lu,Wayne Zhang
论文地址:https://arxiv.org/pdf/2002.01087.pdf
-END-
点击 阅读原文,可跳转浏览本文内所有网址链接
*延伸阅读
添加极市小助手微信
(ID : cv-mart)
,备注:
研究方向-姓名-学校/公司-城市
(如:目标检测-小极-北大-深圳),即可申请加入
目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群
,更有每月
大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流
,
一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台
觉得有用麻烦给个在看啦~ ![]()