你的耳朵真的灵敏吗?Goodfellow等人提出不可察觉的鲁棒语音对抗样本
选自arxiv
作者:Yao Qin、Nicholas Carlini、Ian Goodfellow等
机器之心编译
参与:张倩、王淑婷、杜伟
图像领域的对抗样本对人类来说难以区分,但语音识别领域的对抗样本却往往是可以察觉的,而且听起来非常明显。在本文中,Ian Goodfellow 等人提出了用于自动语音识别体统的针对性对抗样本,这些样本不易被人类察觉,而且非常鲁棒。
对抗样本是由攻击方专门设计的输入,其目的是使机器学习算法产生错误分类。最初的对抗样本研究主要集中于图像分类领域。为了将神经网络中一般对抗样本的性质与仅适用于图像的对抗样本的性质区分开来,研究不同领域的对抗样本非常重要。
实际上,从强化学习到阅读理解再到语音识别领域都存在对抗样本。本文主要研究的是语音识别领域的对抗样本,表明任何给定的源音频样本都可能受到轻微扰动,因此自动语音识别系统(ASR)会把音频转录为任何不同的目标句子。
到目前为止,ASR 系统的对抗样本和图像领域的对抗样本主要有两个不同之处。
首先,图像领域的对抗样本对人类来说难以区分:在不改变 8 位亮度表征的情况下生成对抗样本是可能的。相反,ASR 系统的对抗样本通常是可以察觉的。虽然引入的扰动幅度通常很小,但听起来很明显,附加扰动是存在的。
其次,图像领域的对抗样本主要在物理世界发挥作用(例如在给它们拍照时)。相比之下,ASR 系统的对抗样本还不能在这种由扬声器播放并由麦克风录制的无线环境中发挥作用。
在本文中,研究人员改善了 ASR 系统中对抗样本的构造,开发了不可察觉的对抗样本,其能力可以媲美图像类对抗样本,朝着稳健的对抗样本迈出了一步。
为了生成不可察觉的对抗样本,研究人员没有选择对抗样本研究中广泛使用的常用 l_p 距离度量。相反,他们使用了听觉掩码(auditory masking)的心理声学原理,并且仅在人类听不到的音频区域添加了对抗扰动,即使这种扰动就绝对能量而言并不是「安静的」。
对语音识别领域的对抗样本性质进一步调查后发现,其性质似乎与图像领域对抗样本的性质不同。研究人员调查了攻击方构建物理世界对抗样本的能力。即使考虑了物理世界引入的扭曲,这些输入在分类时仍然是对抗的。通过设计经过随机空间环境模拟器处理后仍然具有对抗性的音频,研究人员朝着开发能够无线播放的音频迈近了一步。
最后,研究人员证明,其对抗能够攻击当前最先进的现代 Lingvo ASR 系统。
论文:Imperceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition

论文地址:https://arxiv.org/abs/1903.10346
对抗样本是由攻击方设计的机器学习模型输入,目的是导致错误输出。到目前为止,对抗样本在图像领域中的研究最为广泛。在图像领域中,对抗样本可以通过图像的细微修改来构建,进而导致误分类,并且对抗样本在现实世界很实用。
相比之下,目前应用于语音识别系统的针对性对抗样本不具有这两种特性:人类很容易识别对抗扰动,而且这些扰动在无线播放下就会失去作用。本论文在这两方面均取得了进展。
其一,研究人员利用听觉掩码(auditory masking)的心理声学原理开发出了不可察觉的音频对抗样本(已经人类研究证实),同时保持任意完整句 100% 的针对性成功率。其二,通过构建在应用真实模拟环境失真后依然有效的扰动,研究人员在物理世界无线音频对抗样本方面取得进展。
如何生成不可察觉的对抗样本
在图像领域,将图像和最近的分类样本之间的 l_p 失真最小化会生成肉眼无法区分的图像,但在语音领域并非如此。因此,本研究脱离了 l_p 失真度量,转而依赖于在声音空间中捕获人类音频感知的广泛工作。
如何生成鲁棒的对抗样本
为了提高对抗样本在无线播放时的鲁棒性,研究人员用一个声学空间模拟器来创建模拟无线播放的人工语音(带有混响的语音)。他们的目标是使用混响(而不是干净的音频)扰动语音欺骗 ASR 系统。同时,对抗扰动δ应该比较小,以使其不被人听见。
如何生成不可察觉的鲁棒样本
结合先前已开发的两项技术,研究人员现在提出了一种生成不可察觉和鲁棒的对抗样本的方法。将损失降至最低可以实现这一点。在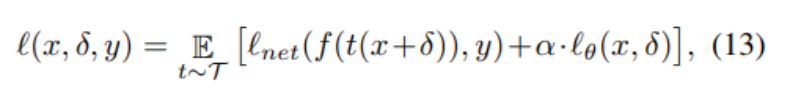
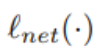
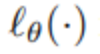
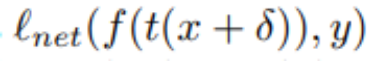
评估
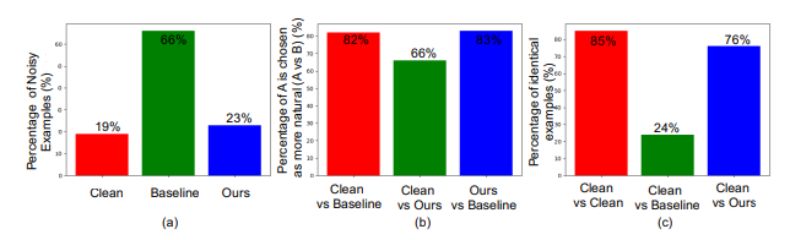
图 1:人们对不可察觉性的研究结果。图中的 baseline 表示由 Carlini & Wagner(2018 年)制作的对抗样本,「ours」表示根据章节 4 中的算法生成的不可察觉对抗样本。
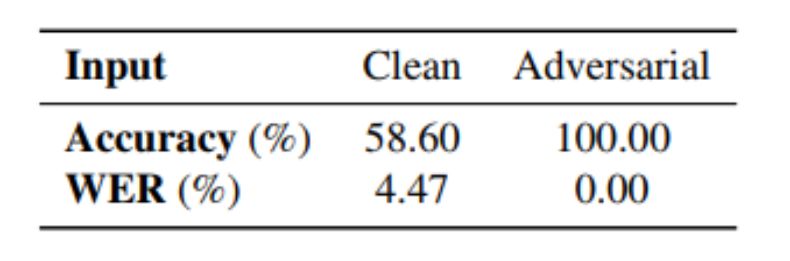
表 1:1000 个 clean 和(不可察觉)对抗性扰动样本的句子级准确率和词错率(WER),并且在没有无线模拟的情况下输入 Lingvo 模型。在「Clean」中,真实值为初始转录。在「Adversarial」中,ground truth 为针对性转录。

表 2:100 个 clean 和对抗性扰动样本的句子级准确率和 WER,并且在无线模拟的情况下输入 Lingvo 模型。「clean」输入的真实值为初始转录,而对抗性输入的真实值为针对性转录。扰动以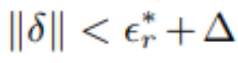

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



