用R语言实现汉语转拼音及英语
今天给大家分享一个有趣的问题,用R语言实现汉语转拼音及英语。文中给出的方法不仅适用于词汇,也适用于简单句子。在汉译英部分会教大家如何调用词霸翻译,但词霸只能翻译词语,为了进行单句翻译,我采用了调用百度翻译API的方法,不幸的是百度只给了200万字符限额,不过对个人的小项目应该足够。为了方便大家使用,拼音转汉语部分给出了大小写以及title三种输出方式。
加载R包
library(rvest)
library(stringr)
library(rjson)
library(digest)
library(jiebaR)
library(jiebaRD)
library(rlist)
抓取全部汉字及保存
网上大多方法算法过于复杂。如果有一个字库,具有所有中文对应拼音(常用汉字才1万多,所以速度方面不会有多大影响),那么就可以通过汉字返回所需要的拼音字母。在网上搜索的时候找到了一个字库,直接抓来用了。我们‘李’字以这个字库中汉字及拼音的表示方法,‘李li3'表示汉字‘李’,拼音为‘li',音调是3(这里只需要拼音)
url='https://github.com/haiwen/seahub/blob/master/seahub/convert-utf-8.txt'
web <- read_html(url)
text=web%>%html_nodes('td:nth-child(2)')%>%html_text()%>%str_trim()
saveRDS(text,'D://汉字.rds')
提取汉字
text=readRDS('D://汉字.rds')
onlytext=str_split(text,'')%>%unlist%>%str_match_all('[\u4e00-\u9fa5]')%>%unlist()
构造汉字-拼音|英语函数
下面代码块给出四个封装函数,fun实现汉语到英语的转换,funx调用百度API进行汉译英转换(需要申请百度翻译API),ciba使用词霸进行汉译英转换,funa是终极整句翻译函数,它有两个参数,x接受句子,y接受词语粘贴方式(如:以“/”粘贴)。
#使用jiebaR设置分词引擎
engine1 = worker()
#汉语——拼音
fun = function(x){
if(x %in% onlytext){
re=text[which(str_detect(text,x))]
lower=re%>%str_match('[a-z]{1,}')
title=re%>%str_match('[a-z]{1,}')%>%str_to_title()
upper=re%>%str_match('[a-z]{1,}')%>%str_to_upper()
}else{
lower=x%>%str_to_lower()
title=x%>%str_to_title()
upper=x%>%str_to_upper()
}
return(list(lower=lower,title=title,upper=upper))
}
#汉译英函数(百度API版)
funx=function(x,fromLang,toLang){
appid = '你的API'
secretKey = '你的API密码'
fromLang = 'zh'
toLang = 'en'
salt=sample(32768:65536,1)
myurl = 'http://api.fanyi.baidu.com/api/trans/vip/translate'
q = x
q=segment(q , engine1)%>%str_c(collapse = '')
sign = paste0(appid,q,salt,secretKey)
hash <- digest(sign, algo="md5", serialize=F)
url=paste0(myurl,'?appid=',appid,'&q=',q,'&from=',fromLang,'&to=',toLang,'&salt=',salt,
'&sign=', hash)
re=read_html(url)%>%html_text()%>%fromJSON()
lang_from=re$trans_result[[1]]$src
lang_to = re$trans_result[[1]]$dst
return(list(lang_from=lang_from,lang_to=lang_to))
}
#汉译英函数(词霸版)
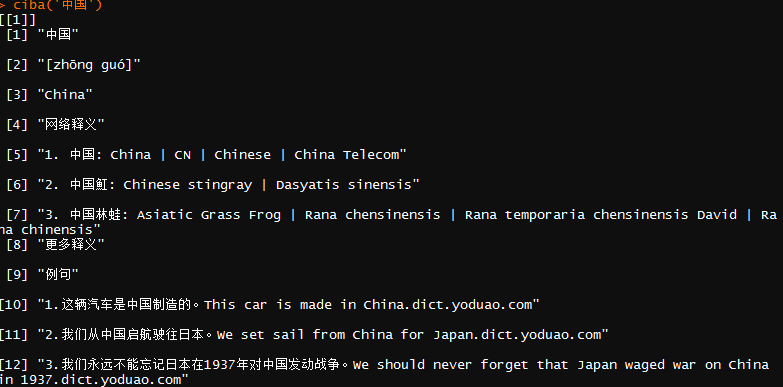
ciba<-function(x){
link=url(paste0('http://dict.youdao.com/m/search?keyfrom=dict.mindex&vendor=&q=',
iconv(x,to='UTF-8')),encoding='UTF-8')
readLines(link)->a
gsub('(<[^<>]*>)|(^ )|(\t)','',a)->a;gsub(' {2,}','',a)->a
head(a,-11)->a;tail(a,-35)->a;a[a!='']->a
paste(a,collapse='\n')->a
gsub('(\n *){2,}','\n',a)->a;gsub(' *\n *','\n',a)->a
print(str_split(a,pattern='\n'))
}
#整句转换
funa=function(x,y){
xt=lapply(x%>%str_extract_all('[\u4e00-\u9fa5]|\\w')%>%unlist,fun)
lower=list.map(xt,lower)%>%unlist%>%str_c(collapse = y)
upper=list.map(xt,upper)%>%unlist%>%str_c(collapse = y)
title=list.map(xt,title)%>%unlist%>%str_c(collapse = y)
re = funx(x)
return(list(lang_from=x,Eng=re$lang_to,lower=lower,title=title,upper=upper))
}
测试
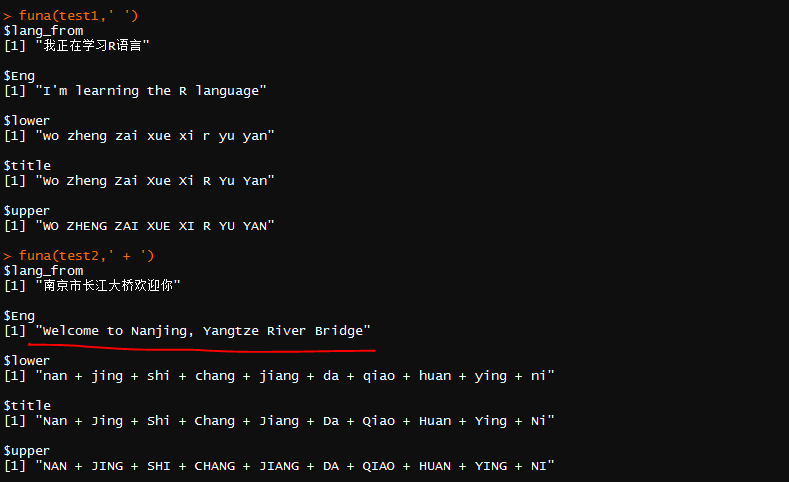
test1='我正在学习R语言'
test2='南京市长江大桥欢迎你'
funa(test1,' ')
funa(test2,' + ')
ciba('中国')
推荐阅读
Python微课:用Python验证你的策略吧!——Zipline回测
Python微课 | Seaborn——Python优雅绘图(上)
Python微课 | Seaborn——Python优雅绘图(下)
更多微课请关注【数萃大数据】公众号,点击学习园地—可视化


欢迎大家关注微信公众号:数萃大数据

网络爬虫与文本挖掘培训班【宁波站】
时间:2017年9月23日-25日
地点:维也纳国际酒店(机场店)
更多详情,请扫描下面二维码





