当GAN生成图像可以卡音效,这个Python包只需几行代码就能实现「音画同步」
机器之心报道
Lucid Sonic Dreams 包可以实现 GAN 生成图像的「音画同步」效果,且支持自定义。
GitHub 地址:https://github.com/mikaelalafriz/lucid-sonic-dreams
Colab 教程地址:https://colab.research.google.com/drive/1Y5i50xSFIuN3V4Md8TB30_GOAtts7RQD?usp=sharing
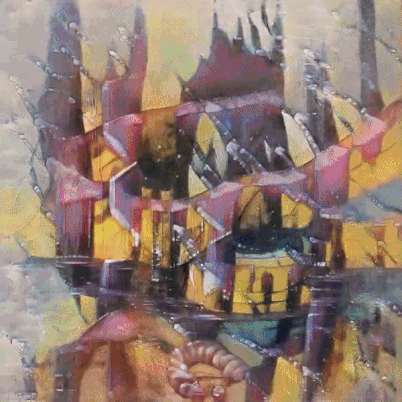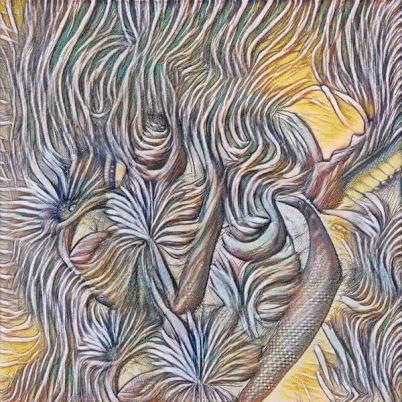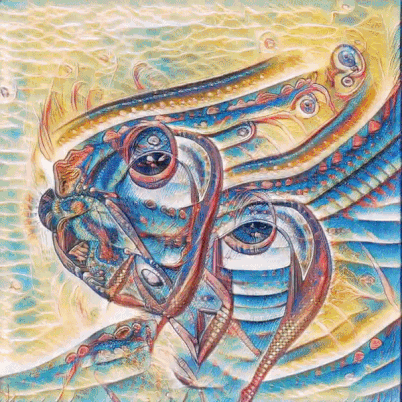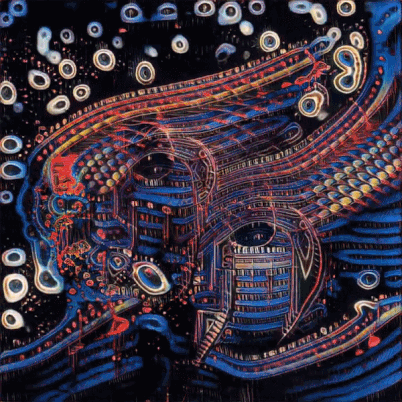
脉冲指视觉画面随着音乐的敲击性节奏而「跳动」。从数学角度来看,「脉冲」是向输入向量暂时添加声波振幅的结果(即在下一帧中该向量仍是初始向量);
运动指视觉画面变换的速度。从数学上看,它是向输入向量累积添加振幅(即添加的振幅后续不会被清零);
类别指生成图像中物体的标签,例如基于 WikiArt 图像训练的风格中就有 167 个类别(包括梵高、达芬奇、抽象派等)。而这些由音调进行控制,具体而言,12 个音高分别对应 12 个不同类别。这些音高的振幅对传输至第二个输入向量(类别向量)的数字造成影响,而这由模型生成的对象来决定。
from lucidsonicdreams import LucidSonicDreamL = LucidSonicDream(song = 'chemical_love.mp3', style = 'abstract photos')L.hallucinate(file_name = 'chemical_love.mp4')
from lucidsonicdreams import show_stylesshow_styles()
L = LucidSonicDream('pancake_feet.mp3', style = 'modern art')= 'pancake_feet.mp4',speed_fpm = 0,motion_react = 0.8,contrast_strength = 0.5,flash_strength = 0.7)
L = LucidSonicDream(song = 'raspberry.mp3', style = 'VisionaryArt.pkl')= 'raspberry.mp4',pulse_react = 1.2,motion_react = 0.7,contrast_strength = 0.5,flash_strength = 0.5)
L = LucidSonicDream(song = 'lucidsonicdreams_main.mp3',pulse_audio = 'lucidsonicdreams_pulse.mp3',class_audio = 'lucidsonicdreams_class.mp3',style = 'wikiart')pulse_react = 0.25,motion_react = 0,classes = [1,5,9,16,23,27,28,30,50,68,71,89],dominant_classes_first = True,class_shuffle_seconds = 8,class_smooth_seconds = 4,class_pitch_react = 0.2,contrast_strength = 0.3)
import numpy as npfrom skimage.transform import swirlfrom lucidsonicdreams import EffectsGeneratordef swirl_func(array, strength, amplitude):swirled_image = swirl(array,rotation = 0,strength = 100 * strength * amplitude,radius=650)return (swirled_image*255).astype(np.uint8)swirl_effect = EffectsGenerator(swirl_func,audio = 'unfaith.mp3',strength = 0.2,percussive = False)L = LucidSonicDream('unfaith.mp3',style = 'textures')L.hallucinate('unfaith.mp4',motion_react = 0.15,speed_fpm = 2,pulse_react = 1.5,contrast_strength = 1,flash_strength = 1,custom_effects = [swirl_effect])files.download("unfaith.mp4")
from pytorch_pretrained_biggan import BigGAN, convert_to_imagesimport torchbiggan = BigGAN.from_pretrained('biggan-deep-512'):0')def biggan_func(noise_batch, class_batch):noise_tensor = torch.from_numpy(noise_batch).cuda()class_tensor = torch.from_numpy(class_batch).cuda()with torch.no_grad():output_tensor = biggan(noise_tensor.float(), class_tensor.float(), truncation = 1)return convert_to_images(output_tensor.cpu())L = LucidSonicDream('sea_of_voices_inst.mp3',style = biggan_func,input_shape = 128,num_possible_classes = 1000)L.hallucinate('sea_of_voices.mp4',output_audio = 'sea_of_voices.mp3',speed_fpm = 3,classes = [13, 14, 22, 24, 301, 84, 99, 100, 134, 143, 393, 394],class_shuffle_seconds = 10,class_shuffle_strength = 0.1,class_complexity = 0.5,class_smooth_seconds = 4,motion_react = 0.35,flash_strength = 1,contrast_strength = 1)
亚马逊云科技白皮书《策略手册:数据、 分析与机器学习》
点击阅读原文,免费领取白皮书。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文