NLG任务评价指标BLEU与ROUGE

准确率、精确率、召回率和F1是在机器学习及NLP领域中常用的指标,但是如果没有涉及机器翻译、摘要抽取等seq2seq任务,一般不会使用BLEU和ROUGE作为评价指标,本文将会着重介绍两个指标基本意义及计算方法,为使用者提供参考。
BLEU
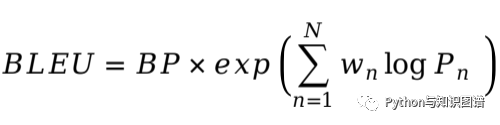
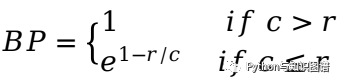
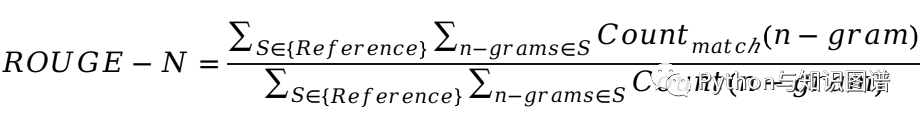
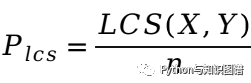
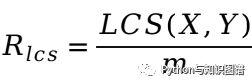
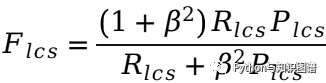
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

登录查看更多
相关内容

专知会员服务
31+阅读 · 2020年5月20日
专知会员服务
7+阅读 · 2019年12月19日
Arxiv
4+阅读 · 2018年5月18日


相关VIP内容
专知会员服务
31+阅读 · 2020年5月20日
专知会员服务
7+阅读 · 2019年12月19日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年5月18日