万字总结83篇文献:深度强化学习之炒作、反思、回归本源

1
深度强化学习的泡沫
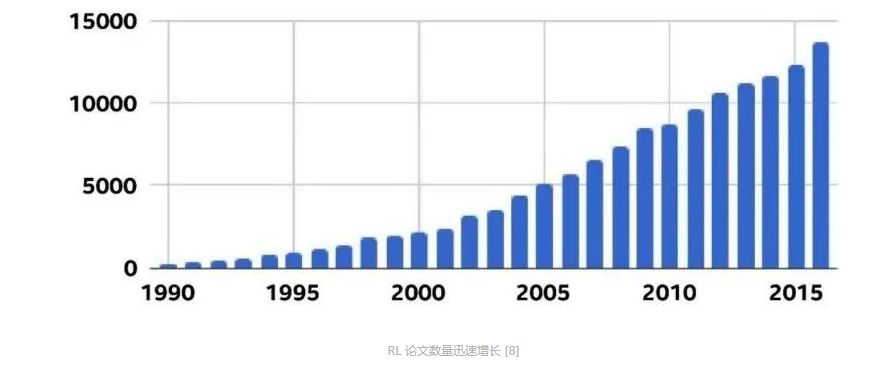
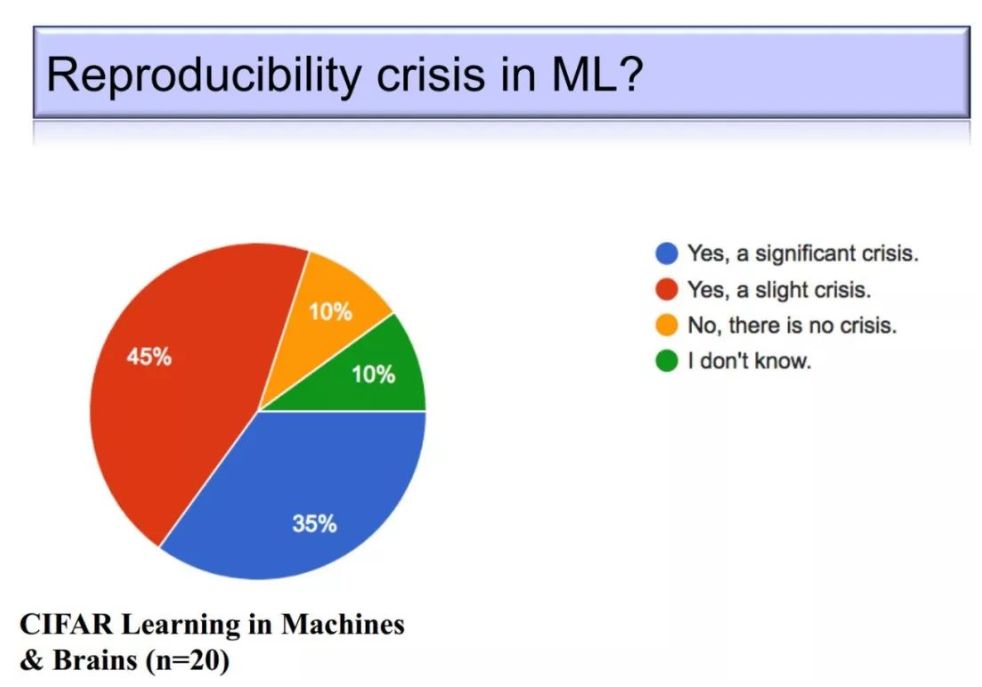

-
样本利用率非常低; -
最终表现不够好,经常比不过基于模型的方法; -
好的奖励函数难以设计; -
难以平衡“探索”和“利用”, 以致算法陷入局部极小; -
对环境的过拟合; -
灾难性的不稳定性…
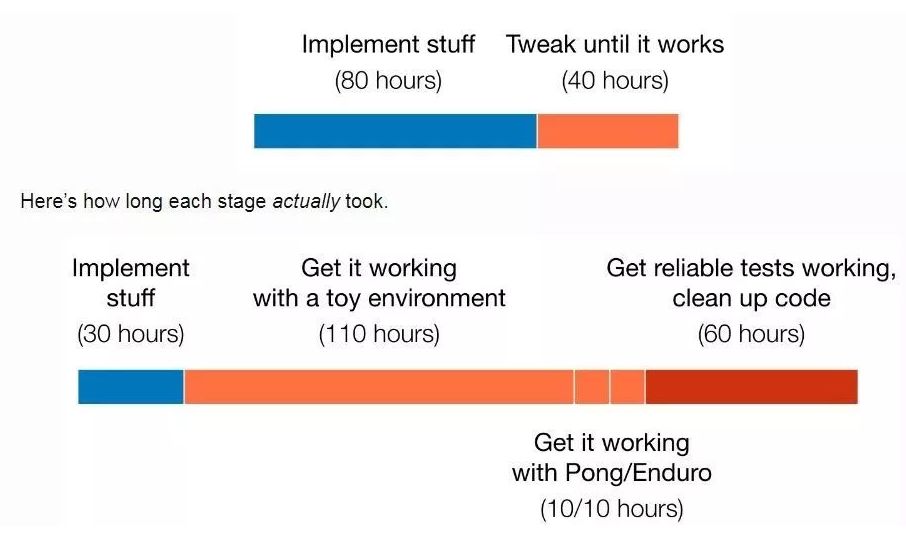
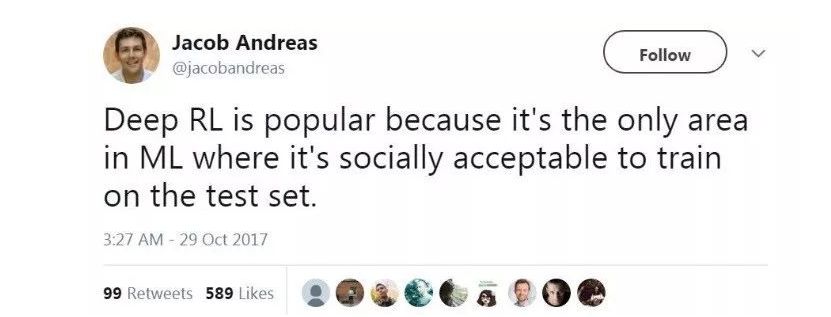
2
免模型强化学习的本质缺陷
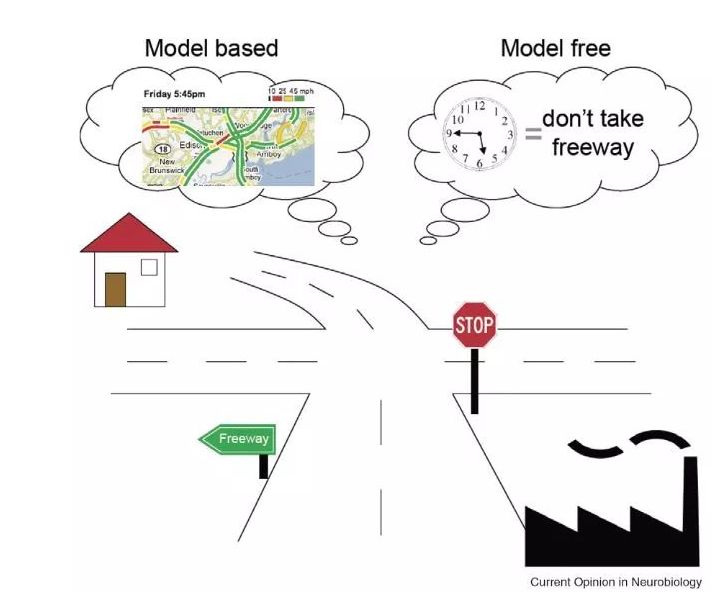
-
基于模型的方法针对问题建立动力学模型,这个模型具有解释性。而免模型方法因为没有模型,解释性不强,调试困难。 -
相比基于模型的方法,尤其是基于简单线性模型的方法,免模型方法不够稳定,在训练中极易发散。
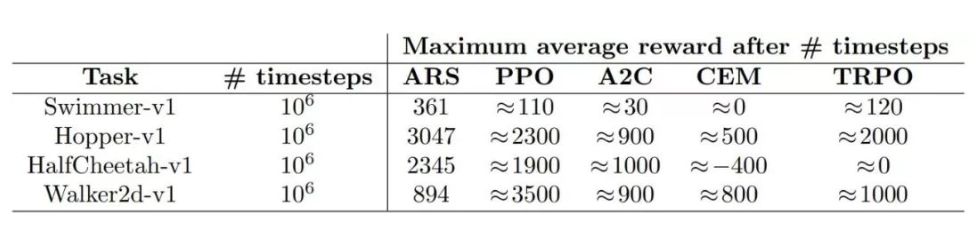
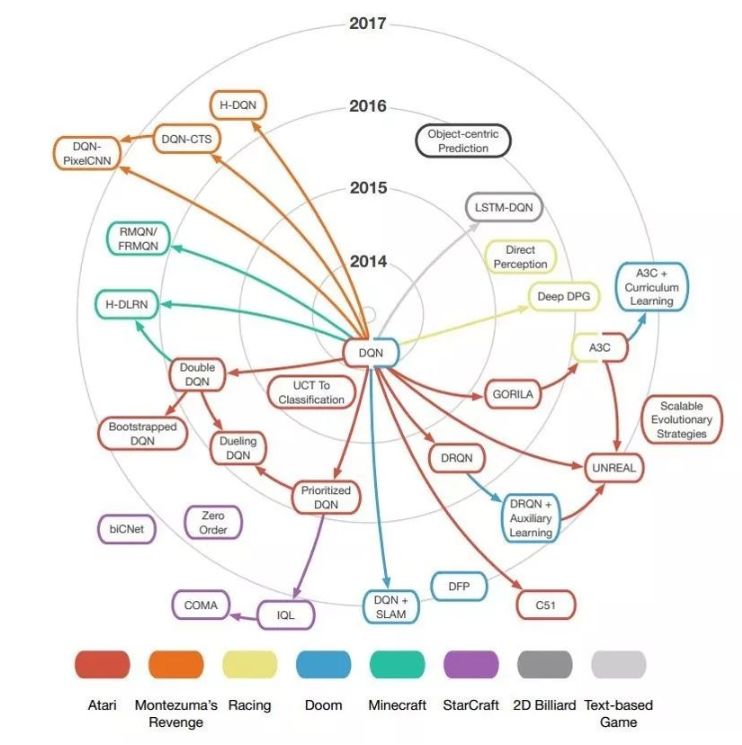
3
基于模型或免模型,问题没那么简单
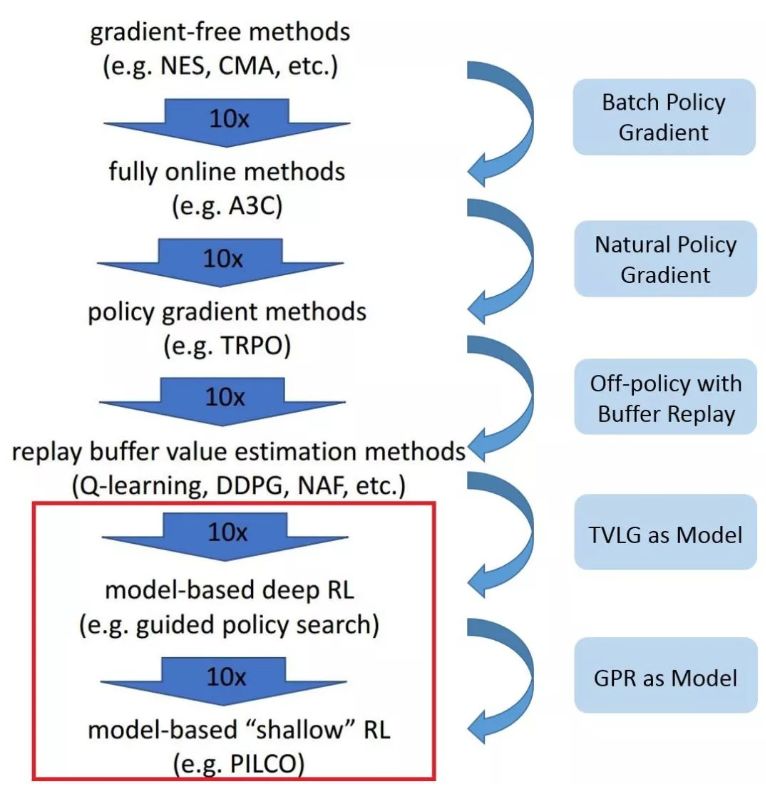
-
针对无法建模的问题束手无策。有些领域,比如 NLP,存在大量难以归纳成模型的任务。在这种场景下,只能通过诸如 R-max 算法这样的方法先与环境交互,计算出一个模型为后续使用。但是这种方法的复杂度一般很高。近期有一些工作结合预测学习建立模型,部分地解决了建模难的问题,这一思路逐渐成为了研究热点。 -
建模会带来误差,而且误差往往随着算法与环境的迭代交互越来越大,使得算法难以保证收敛到最优解。 -
模型缺乏通用性,每次换一个问题,就要重新建模。
4
重新审视强化学习
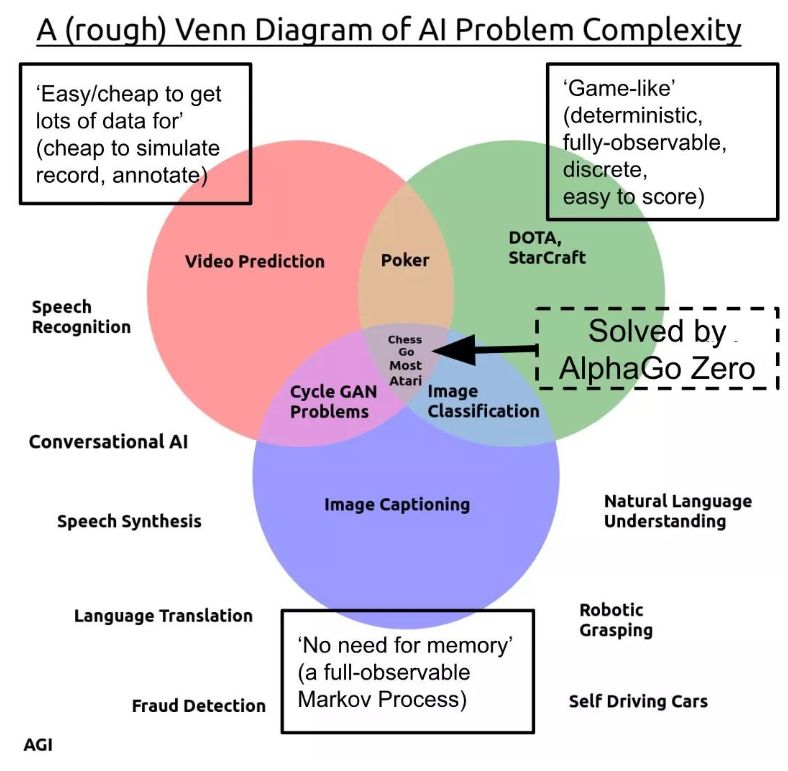
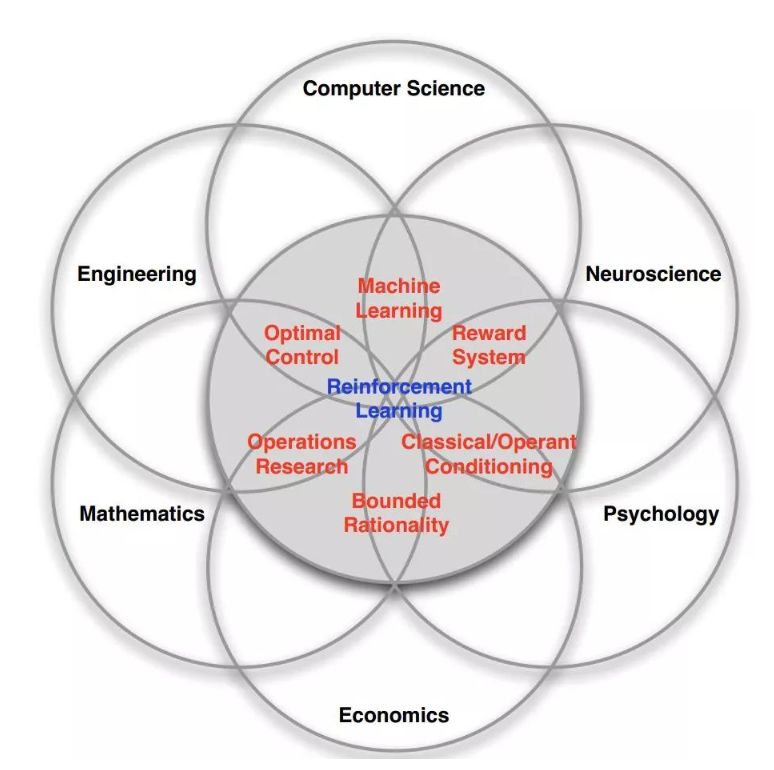
-
基于模型的方法。如上文所述,基于模型的方法不仅能大幅降低采样需求,还可以通过学习任务的动力学模型,为预测学习打下基础。 -
提高免模型方法的数据利用率和扩展性。这是免模型学习的两处硬伤,也是 Rich Sutton 的终极研究目标。这个领域很艰难,但是任何有意义的突破也将带来极大价值。 -
更高效的探索策略(Exploration Strategies)。平衡“探索”与“利用”是 RL 的本质问题,这需要我们设计更加高效的探索策略。除了若干经典的算法如 Softmax、ϵ-Greedy[1]、UCB[72] 和 Thompson Sampling[73] 等,近期学界陆续提出了大批新算法,如 Intrinsic Motivation [74]、Curiosity-driven Exploration[75]、Count-based Exploration [76] 等。其实这些“新”算法的思想不少早在 80 年代就已出现 [77],而与 DL 的有机结合使它们重新得到重视。此外,OpenAI 与 DeepMind 先后提出通过在策略参数 [78] 和神经网络权重 [79] 上引入噪声来提升探索策略, 开辟了一个新方向。 -
与模仿学习(Imitation Learning, IL)结合。机器学习与自动驾驶领域最早的成功案例 ALVINN[33] 就是基于 IL;当前 RL 领域最顶级的学者 Pieter Abbeel 在跟随 Andrew Ng 读博士时候, 设计的通过 IL 控制直升机的算法 [34] 成为 IL 领域的代表性工作。2016 年,英伟达提出的端到端自动驾驶系统也是通过 IL 进行学习 [68]。而 AlphaGo 的学习方式也是 IL。IL 介于 RL 与监督学习之间,兼具两者的优势,既能更快地得到反馈、更快地收敛,又有推理能力,很有研究价值。关于 IL 的介绍,可以参见 [35] 这篇综述。 -
奖赏塑形(Reward Shaping)。奖赏即反馈,其对 RL 算法性能的影响是巨大的。Alexirpan 的博文中已经展示了没有精心设计的反馈信号会让 RL 算法产生多么差的结果。设计好的反馈信号一直是 RL 领域的研究热点。近年来涌现出很多基于“好奇心”的 RL 算法和层级 RL 算法,这两类算法的思路都是在模型训练的过程中插入反馈信号,从而部分地克服了反馈过于稀疏的问题。另一种思路是学习反馈函数,这是逆强化学习(Inverse RL, IRL)的主要方式之一。近些年大火的 GAN 也是基于这个思路来解决生成建模问题, GAN 的提出者 Ian Goodfellow 也认为 GAN 就是 RL 的一种方式 [36]。而将 GAN 于传统 IRL 结合的 GAIL[37] 已经吸引了很多学者的注意。 -
RL 中的迁移学习与多任务学习。当前 RL 的采样效率极低,而且学到的知识不通用。迁移学习与多任务学习可以有效解决这些问题。通过将从原任务中学习的策略迁移至新任务中,避免了针对新任务从头开始学习,这样可以大大降低数据需求,同时也提升了算法的自适应能力。在真实环境中使用 RL 的一大困难在于 RL 的不稳定性,一个自然的思路是通过迁移学习将在模拟器中训练好的稳定策略迁移到真实环境中,策略在新环境中仅通过少量探索即可满足要求。然而,这一研究领域面临的一大问题就是现实鸿沟(Reality Gap),即模拟器的仿真环境与真实环境差异过大。好的模拟器不仅可以有效填补现实鸿沟,还同时满足 RL 算法大量采样的需求,因此可以极大促进 RL 的研究与开发,如上文提到的 Sim-to-Real[71]。同时,这也是 RL 与 VR 技术的一个结合点。近期学术界和工业界纷纷在这一领域发力。在自动驾驶领域,Gazebo、EuroTruck Simulator、TORCS、Unity、Apollo、Prescan、Panosim 和 Carsim 等模拟器各具特色,而英特尔研究院开发的 CARLA 模拟器 [38] 逐渐成为业界研究的标准。其他领域的模拟器开发也呈现百花齐放之势:在家庭环境模拟领域, MIT 和多伦多大学合力开发了功能丰富的 VirturalHome 模拟器;在无人机模拟训练领域,MIT 也开发了 Flight Goggles 模拟器。 -
提升 RL 的的泛化能力。机器学习最重要的目标就是泛化能力, 而现有的 RL 方法大多在这一指标上表现糟糕 [8],无怪乎 Jacob Andreas 会批评 RL 的成功是来自“train>
-
层级 RL(Hierarchical RL, HRL)。周志华教授总结 DL 成功的三个条件为:有逐层处理、有特征的内部变化和有足够的模型复杂度 [39]。而 HRL 不仅满足这三个条件,而且具备更强的推理能力,是一个非常潜力的研究领域。目前 HRL 已经在一些需要复杂推理的任务(如 Atari 平台上的《Montezuma's Revenge》游戏)中展示了强大的学习能力 [40]。 -
与序列预测(Sequence Prediction)结合。Sequence Prediction 与 RL、IL 解决的问题相似又不相同。三者间有很多思想可以互相借鉴。当前已有一些基于 RL 和 IL 的方法在 Sequence Prediction 任务上取得了很好的结果 [41,42,43]。这一方向的突破对 Video Prediction 和 NLP 中的很多任务都会产生广泛影响。 -
(免模型)方法探索行为的安全性(Safe RL)。相比于基于模型的方法,免模型方法缺乏预测能力,这使得其探索行为带有更多不稳定性。一种研究思路是结合贝叶斯方法为 RL 代理行为的不确定性建模,从而避免过于危险的探索行为。此外,为了安全地将 RL 应用于现实环境中,可以在模拟器中借助混合现实技术划定危险区域,通过限制代理的活动空间约束代理的行为。 -
关系 RL。近期学习客体间关系从而进行推理与预测的“关系学习”受到了学界的广泛关注。关系学习往往在训练中构建的状态链,而中间状态与最终的反馈是脱节的。RL 可以将最终的反馈回传给中间状态,实现有效学习,因而成为实现关系学习的最佳方式。2017 年 DeepMind 提出的 VIN[44] 和 Pridictron[23] 均是这方面的代表作。2018 年 6 月,DeepMind 又接连发表了多篇关系学习方向的工作如关系归纳偏置 [45]、关系 RL[46]、关系 RNN[47]、图网络 [48] 和已经在《科学》杂志发表的生成查询网络(Generative Query Network,GQN)[49]。这一系列引人注目的工作将引领关系 RL 的热潮。 -
对抗样本 RL。RL 被广泛应用于机械控制等领域,这些领域相比于图像识别语音识别等等,对鲁棒性和安全性的要求更高。因此针对 RL 的对抗攻击是一个非常重要的问题。近期有研究表明,会被对抗样本操控,很多经典模型如 DQN 等算法都经不住对抗攻击的扰动 [50,51]。 -
处理其他模态的输入。在 NLP 领域,学界已经将 RL 应用于处理很多模态的数据上,如句子、篇章、知识库等等。但是在计算机视觉领域,RL 算法主要还是通过神经网络提取图像和视频的特征,对其他模态的数据很少涉及。我们可以探索将 RL 应用于其他模态的数据的方法,比如处理 RGB-D 数据和激光雷达数据等。一旦某一种数据的特征提取难度大大降低,将其与 RL 有机结合后都可能取得 AlphaGo 级别的突破。英特尔研究院已经基于 CARLA 模拟器在这方面开展了一系列的工作。

-
控制领域。这是 RL 思想的发源地之一,也是 RL 技术应用最成熟的领域。控制领域和机器学习领域各自发展了相似的思想、概念与技术,可以互相借鉴。比如当前被广泛应用的 MPC 算法就是一种特殊的 RL。在机器人领域,相比于 DL 只能用于感知,RL 相比传统的法有自己的优势:传统方法如 LQR 等一般基于图搜索或概率搜索学习到一个轨迹层次的策略,复杂度较高,不适合用于做重规划;而 RL 方法学习到的则是状态 - 动作空间中的策略,具有更好的适应性。 -
自动驾驶领域。驾驶就是一个序列决策过程,因此天然适合用 RL 来处理。从 80 年代的 ALVINN、TORCS 到如今的 CARLA,业界一直在尝试用 RL 解决单车辆的自动驾驶问题以及多车辆的交通调度问题。类似的思想也广泛地应用在各种飞行器、水下无人机领域。 -
NLP 领域。相比于计算机视觉领域的任务,NLP 领域的很多任务是多轮的,即需通过多次迭代交互来寻求最优解(如对话系统);而且任务的反馈信号往往需要在一系列决策后才能获得(如机器写作)。这样的问题的特性自然适合用 RL 来解决,因而近年来 RL 被应用于 NLP 领域中的诸多任务中,如文本生成、文本摘要、序列标注、对话机器人(文字 / 语音)、机器翻译、关系抽取和知识图谱推理等等。成功的应用案例也有很多,如对话机器人领域中 Yoshua Bengio 研究组开发的 MILABOT 的模型 [54]、Facebook 聊天机器人 [55] 等;机器翻译领域 Microsoft Translator [56] 等。此外,在一系列跨越 NLP 与计算机视觉两种模态的任务如 VQA、Image/Video Caption、Image Grounding、Video Summarization 等中,RL 技术也都大显身手。 -
推荐系统与检索系统领域。RL 中的 Bandits 系列算法早已被广泛应用于商品推荐、新闻推荐和在线广告等领域。近年也有一系列的工作将 RL 应用于信息检索、排序的任务中 [57]。 -
金融领域。RL 强大的序列决策能力已经被金融系统所关注。无论是华尔街巨头摩根大通还是创业公司如 Kensho,都在其交易系统中引入了 RL 技术。 -
对数据的选择。在数据足够多的情况下,如何选择数据来实现“快、好、省”地学习,具有非常大的应用价值。近期在这方面也涌现出一系列的工作,如 UCSB 的 Jiawei Wu 提出的 Reinforced Co-Training [58] 等。 -
通讯、生产调度、规划和资源访问控制等运筹领域。这些领域的任务往往涉及“选择”动作的过程,而且带标签数据难以取得,因此广泛使用 RL 进行求解。
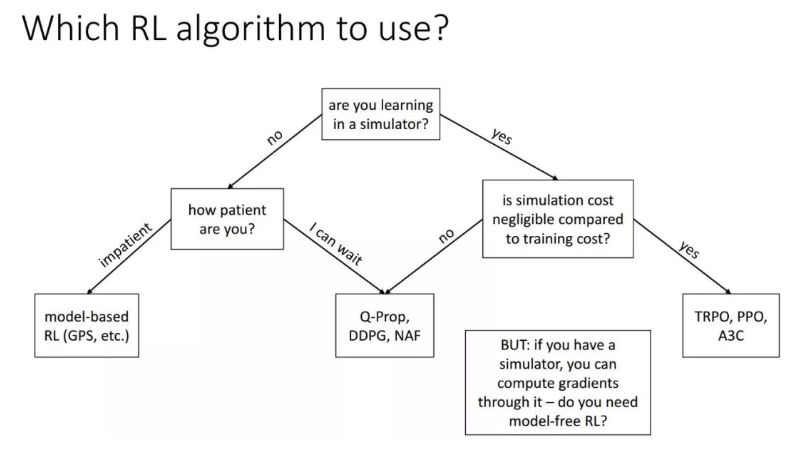
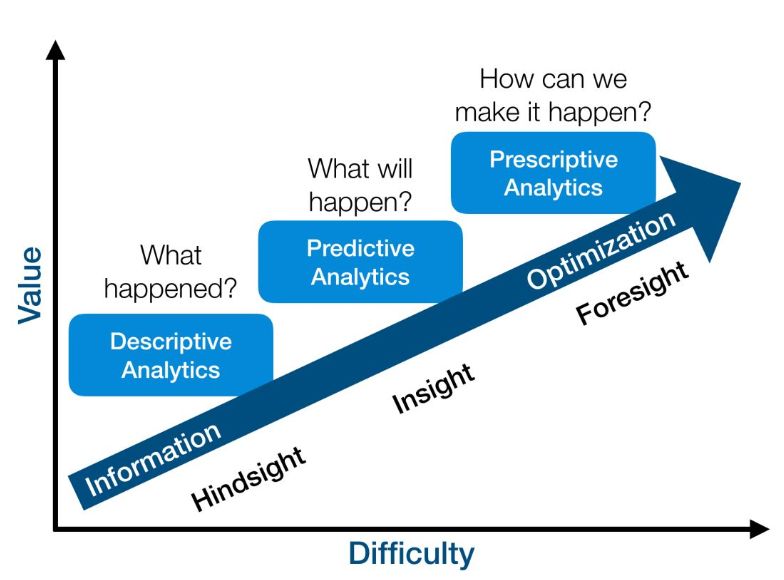
5
广义的RL——从反馈学习
-
在组织行为学领域,学者们探究“主动性人格”与“被动性人格”的不同以及对组织的影响; -
在企业管理学领域,企业的“探索式行为”和“利用式行为”一直是一个研究热点; -
……
6
结语

点击阅读原文,直达“CCF-NLP走进高校之郑州大学”直播页面!
登录查看更多
相关内容
Arxiv
0+阅读 · 2020年12月2日
Arxiv
1+阅读 · 2020年11月30日
Arxiv
3+阅读 · 2018年9月6日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2020年12月2日
Arxiv
1+阅读 · 2020年11月30日
Arxiv
3+阅读 · 2018年9月6日