每日论文 | SingleGAN:单一生成器进行图像转换;用深度网络实现机器人在线追踪;从RGBD图像进行目标密集重建
SingleGAN: Image-to-Image Translation by a Single-Generator Network using Multiple Generative Adversarial Learning
图像转化是CV领域的热门研究对象,它的目标就是学习输入图像和输出图像之间的映射。但是,最近提出的大多数方法在建模时都需要多个生成器,有时会很低效。这篇论文中,我们提出了一种新方法——SingleGAN,只用一个生成器来执行多域之间图像到图像的转换。
地址:https://arxiv.org/abs/1810.04991
Online Visual Robot Tracking and Identification using Deep LSTM Networks
能够完成很多通用任务的协作机器人在很多场景下都十分必要。为了让机器人实现协作,其中一个重要的挑战就是互相追踪和辨认。我们提出了一种新型在线视觉检测、追踪、定位机器人的方法,可以在有限的硬件上实时进行。

地址:https://arxiv.org/abs/1810.04941
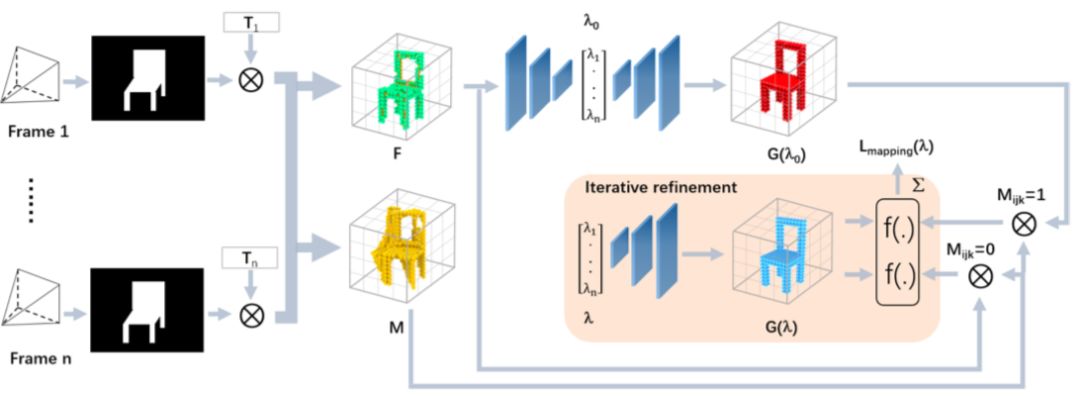
Dense Object Reconstruction from RGBD Images with Embedded Deep Shape Representations
为了得到更精确的测量模型并包含更高级的图像先验,CV领域最近将注意力转移到深度端到端的模型,已解决几何定位和映射问题。但是,在测试时,这些前馈模型忽略了更传统的集合或光度一致性规则,从而导致细节重建得不够好。在一项从RGBD图像中对图像密集建模的应用中,我们的工作通过将目前高级的目标对象形状鲜艳嵌入到经典迭代残差最小化中来得到最佳结果。最终在真实数据中成功应用。
地址:https://arxiv.org/abs/1810.04891