LARS: 学习率层次自适应,超大批量32K

背景
在大批量SGD: 1小时训练ImageNet中,我们介绍了大批量训练模型的两个技巧,那就是线性增长学习率和warmup策略。虽然很有效,把模型的训练速度提升了很多,但是在批量超过8k以后,存在着效果的降低。
因而,在论文[1]出来之前,大家的结论是过度的增大batch会导致泛化能力的下降。因为当batch变的很大时,训练得到的train loss和test loss差距比较大。
调参
为了解决效果降低的问题,文献[1]在AlexNet上试了很多种方法,比如:
-
data shuffle -
data Scaling -
multi-step LR -
min LR tuning -
Batch Normalization
其中,只有Batch Normalization是有效的,它可以使得准确率提升,且训练时损失和测试时损失类似。
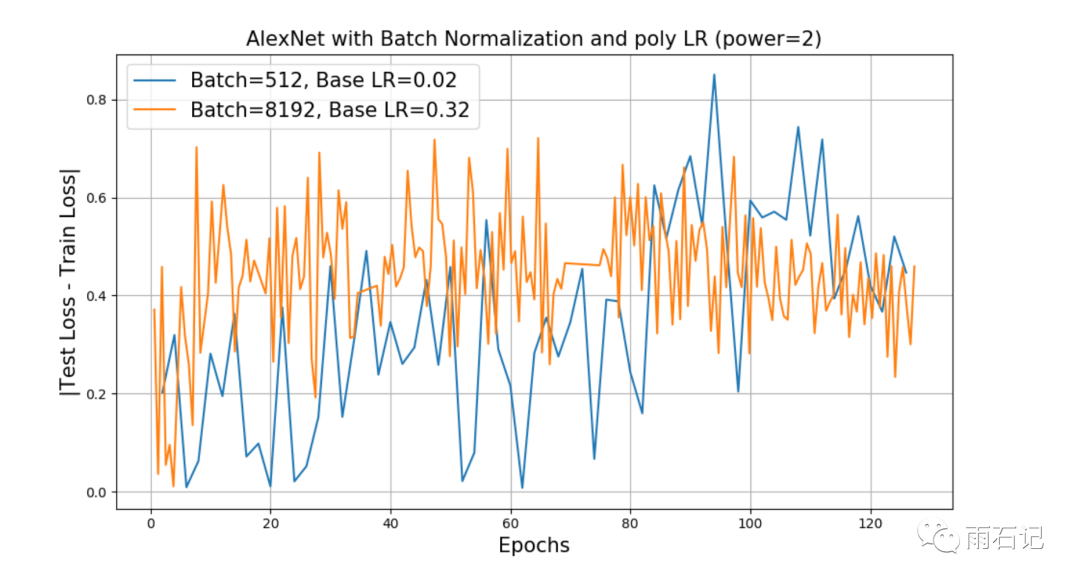
如上图所示,可以看到,Test Loss - Train Loss在Batch等于512和8192的时候都基本一致。
另外,图中的Poly LR是一种学习率衰减策略,其计算公式如下,这里采用power=2。
LearningRate = InitialLearningRate*(1 - iter/max_iter) ^ (power)
虽然有了Batch Normalization,但效果依然比小batch要差。但BN的结果说明了大batch效果差不是泛化的问题,而是训练的问题。
动机
在调参过程中,发现每一层的参数值和梯度值的差别是不一样的,有时候差距会非常大。
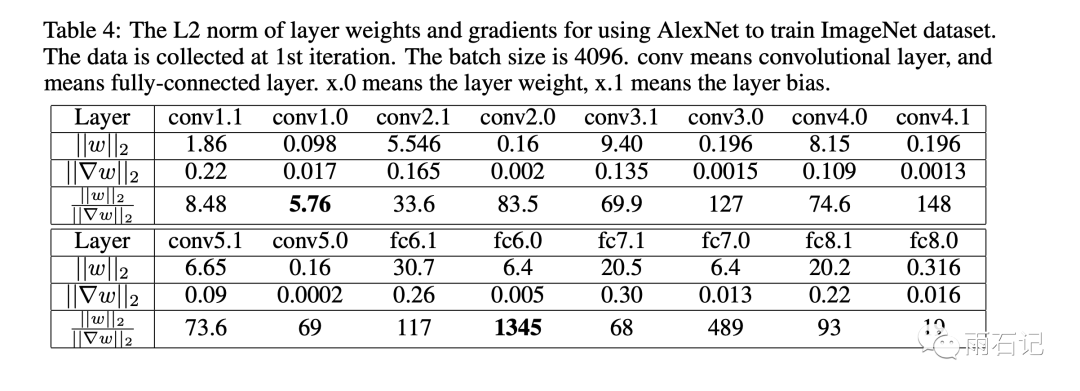
可以看到在较低的层次,这个比值一般很低,但在fc6.0这层及以后,这个比例会变动比较大。当比值大的时候,可以使用比较大的学习率,但是此时这样的学习率是不适合使用在比值较小的层次上的,会导致这些层次上学习好的权重发散掉。
LARS
LARS,是Layer-wise Adaptive Rate Scaling的缩写,即层次适应的学习率。
这个方法就是使用参数和梯度的比值来作为学习率的一个因子。如下图,γ是初始的学习率,一般设置一个1到50之间的数字;l是缩放因子,一般设为0.001,最后一项就是权重除以梯度,这里权重和梯度都是矩阵,所以使用了它们的L2-norm。
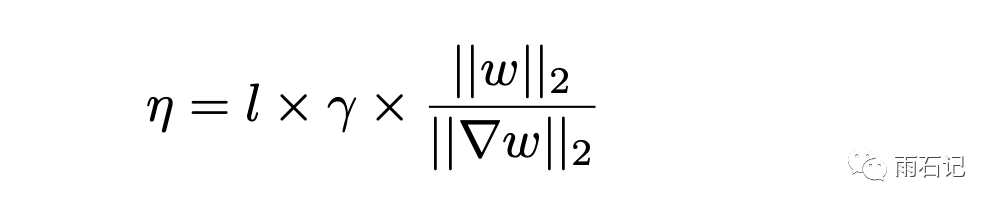
除了自适应学习率之外,还需要考虑把冲量也考虑进来,还需要考虑梯度衰减,梯度衰减是由二阶正则化项计算梯度得到的,需要引入一个新的系数β。
这样,LARS的计算过程如下:
-
对于每层的参数,获取对应的学习率系数。
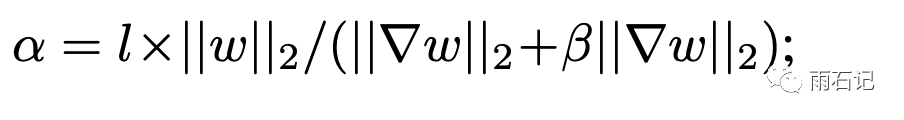
-
计算学习率 η = γ x α -
更新梯度 ∇w = ∇w + βw -
更新冲量 a = µa + η∇w -
更新参数 w = w − a
实验效果
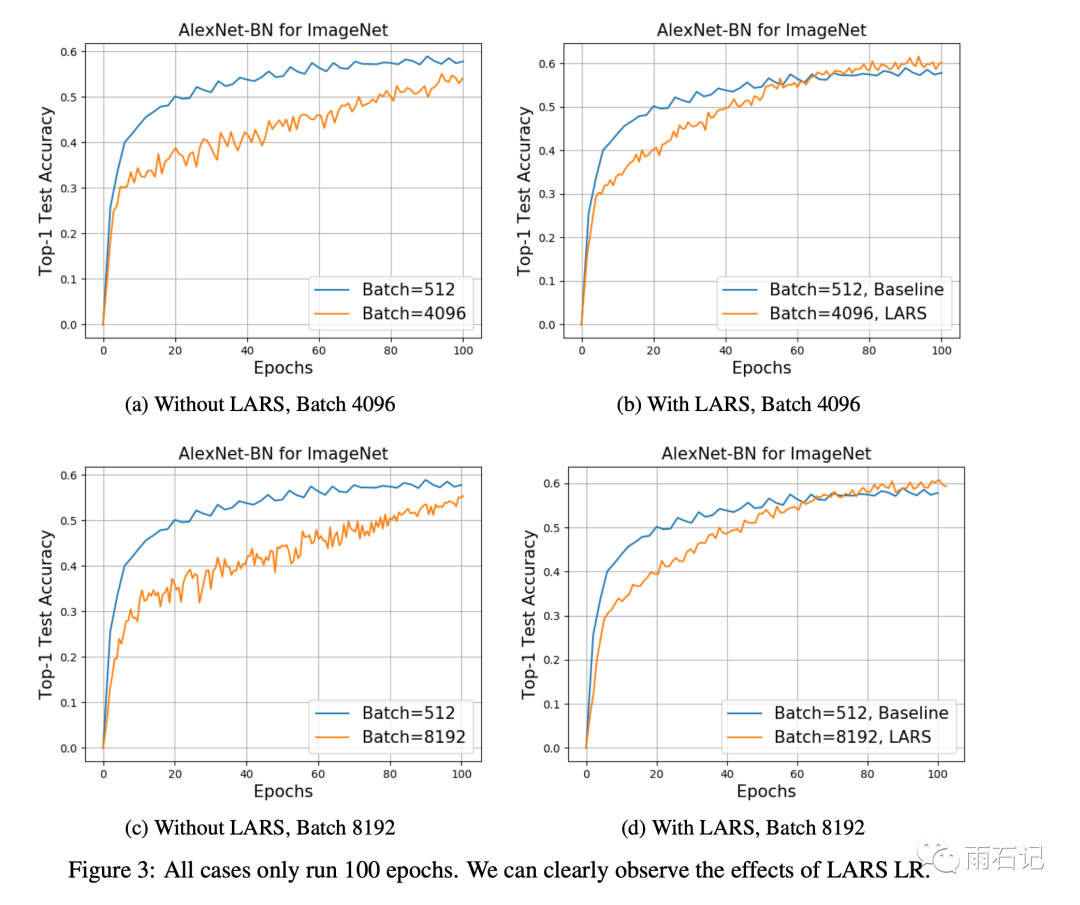
有了LARS之后,就可以在AlexNet上把批大小从1024提高的8192.
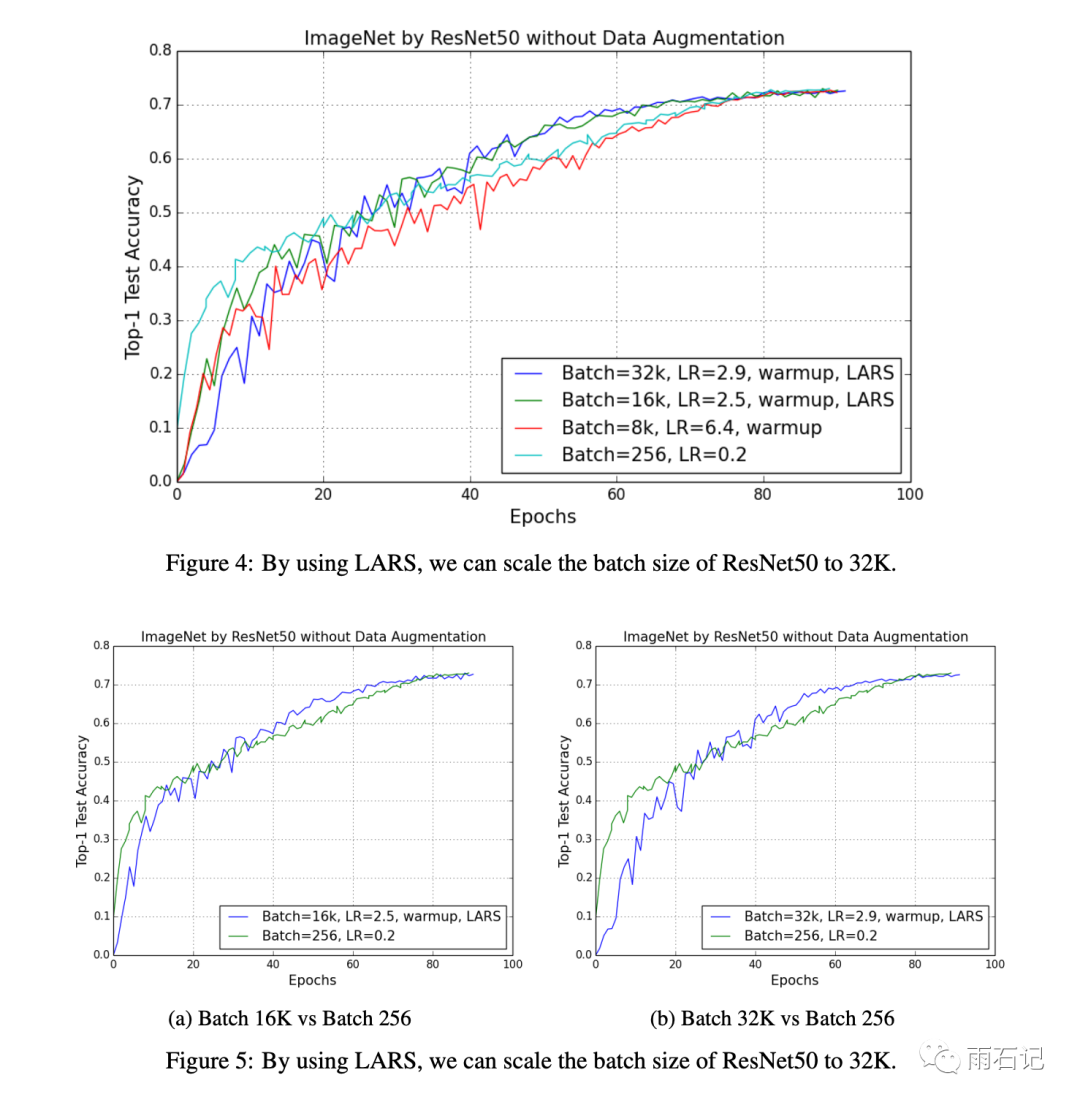
还可以在ResNet上把批大小扩展到32k而不会导致最后效果的变差。
思考
勤思考,多提问是Engineer的良好品德。
-
先来个基础题,试写出没有LARS时的SGD + momentum + weight decay的计算公式。 -
LARS是将Layer-wise learning rate和SGD + momentum去做混合的,那么Layer-wise learning rate能否和Adam去做混合呢?写出公式。
参考文献
-
[1]. You, Yang, Igor Gitman, and Boris Ginsburg. "Scaling sgd batch size to 32k for imagenet training." arXiv preprint arXiv:1708.03888 6 (2017).
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


