谷歌、MIT「迭代共同认证」视频问答模型:SOTA性能,算力少用80%

新智元报道
【新智元导读】谷歌、MIT联合研究,视频问答模型计算效率提升一倍。


该模型的主要目标是从视频和文本(即用户问题)中产生特征,共同允许它们的相应输入进行互动。
第二个目标是以有效的方式做到这一点,这对视频来说非常重要,因为它们包含几十到几百帧的输入。
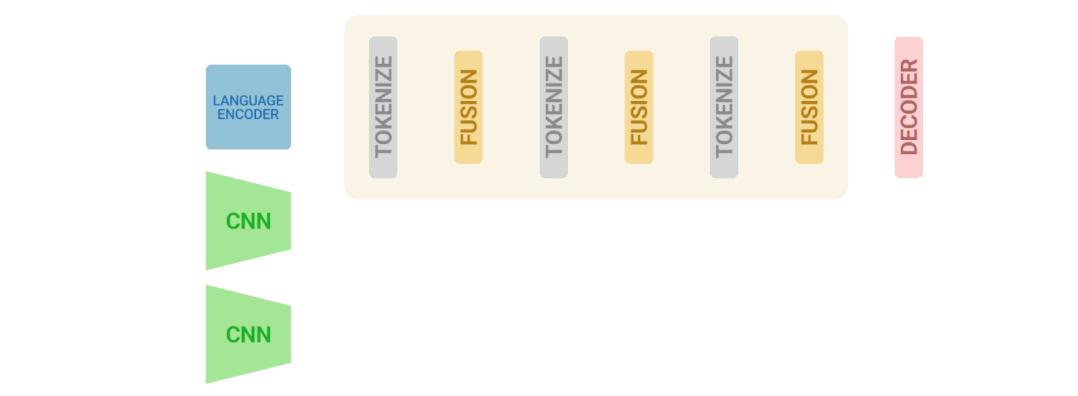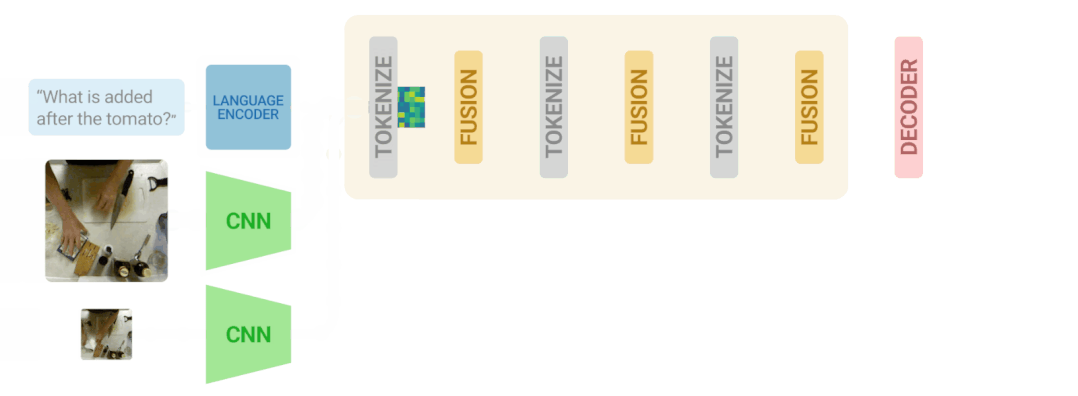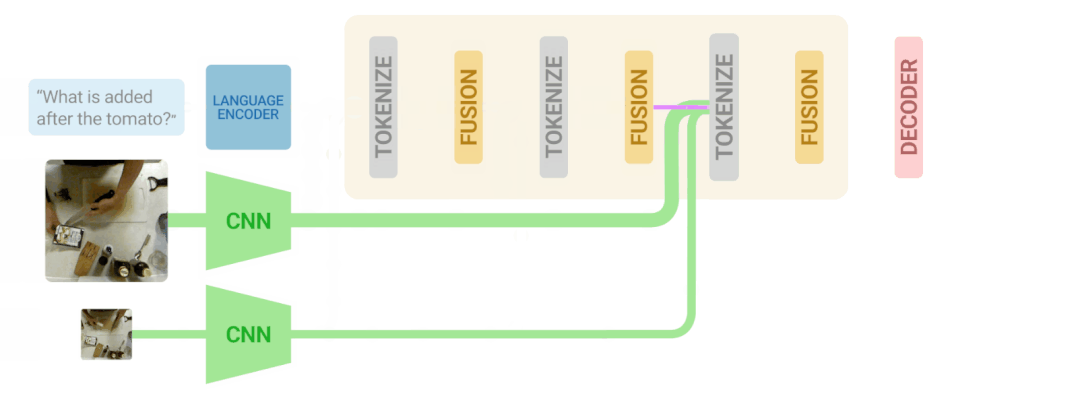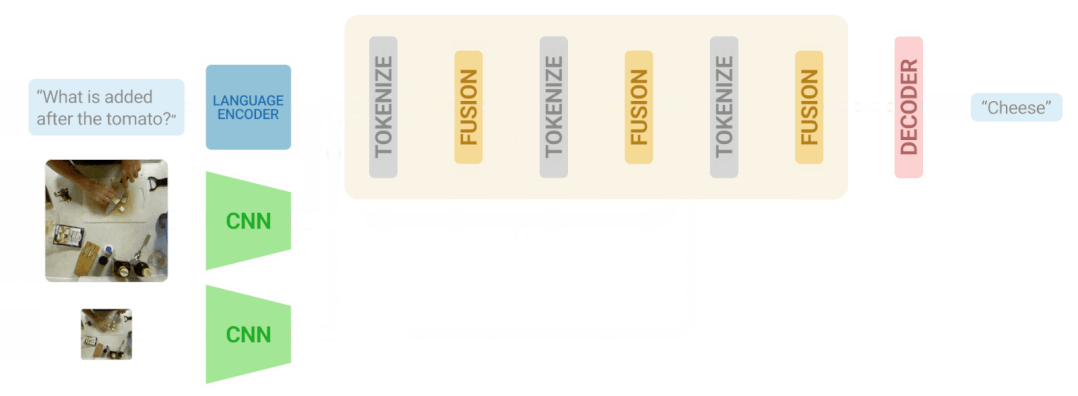
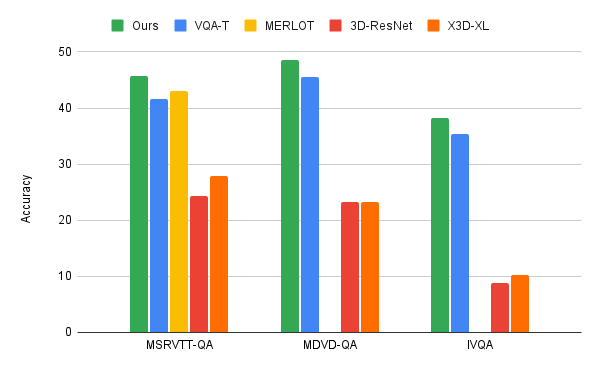
研究人员将视频语言迭代共同认证算法应用于三个主要的VideoQA基准,MSRVTT-QA、MSVD-QA和IVQA,并证明这种方法比其他最先进的模型取得了更好的结果,同时模型不至于过大。
另外,迭代式共同标记学习在视频-文本学习任务上对算力的需求也更低。
对
于VideoQA或其他一些涉及视频输入的任务,研
究人员发现,多流输入对于更准确地回答有关空间和时间关系的问题很重要。
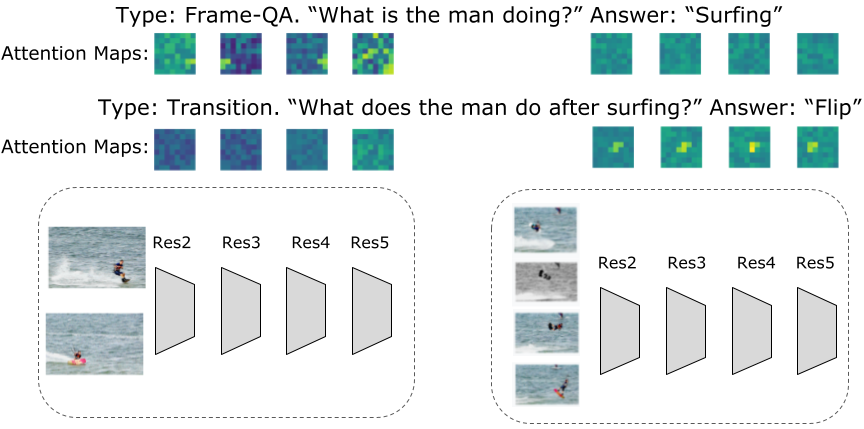
研究人员提出了一种新的视频语言学习方法,它侧重于跨视频-文本模式的联合学习。
研究人员解决了视频问题回答这一重要而具有挑战性的任务。
研究人员的方法既高效又准确,尽管效率更高,但却优于目前最先进的模型。


登录查看更多
相关内容

Real-time Model Predictive Control and System Identification Using Differentiable Physics Simulation
Arxiv
0+阅读 · 2022年11月23日


相关VIP内容
相关资讯
相关论文
Real-time Model Predictive Control and System Identification Using Differentiable Physics Simulation
Arxiv
0+阅读 · 2022年11月23日