轻量级卷积神经网络的设计
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:zhouyuangan
https://zhuanlan.zhihu.com/p/64400678
本文已授权,未经允许,不得二次转载
这篇文章将从一个证件检测网络(Retinanet)的轻量化谈起,简洁地介绍,我在实操中使用到的设计原则和idea,并贴出相关的参考资料和成果供读者参考。因此本文是一篇注重工程性、总结个人观点的文章,存在不恰当的地方,请读者在评论区指出,方便交流。
目前已有的轻量网络有:MobileNet V2和ShuffleNet v2为代表。在实际业务中,Retinanet仅需要检测证件,不涉及过多的类别物体的定位和分类,因此,我认为仅仅更换上述两个骨架网络来优化模型的性能是不够的,需要针对证件检测任务,专门设计一个更加轻量的卷积神经网络来提取、糅合特征。
设计原则:
1. 更多的数据
轻量的浅层网络特征提取能力不如深度网络,训练也更需要技巧。假设保证有足够多的训练的数据,轻量网络训练会更加容易。
Facebook研究院的一篇论文[1]提出了“数据蒸馏”的方法。实际上,标注数据相对未知数据较少,我使用已经训练好、效果达标的base resnet50的retinanet来进行自动标注,得到一批10万张机器标注的数据。这为后来的轻量网络设计奠定了数据基础。我认为这是构建一个轻量网络必要的条件之一,网络结构的有效性验证离不开大量的实验结果来评估。
接下来,这一部分我将简洁地介绍轻量CNN地设计的四个原则
2. 卷积层的输入、输出channels数目相同时,计算需要的MAC(memory access cost)最少
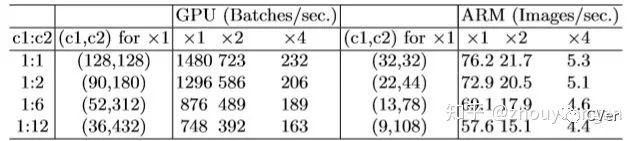
3. 过多的分组卷积会增加MAC
对于1x1的分组卷积(例如:MobileNetv2的深度可分离卷积采用了分组卷积),其MAC和FLOPS的关系为:
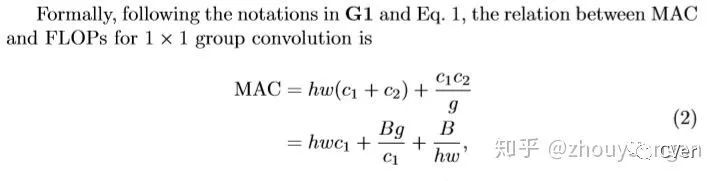
g代表分组卷积数量,很明显g越大,MAC越大。详细参考[2]
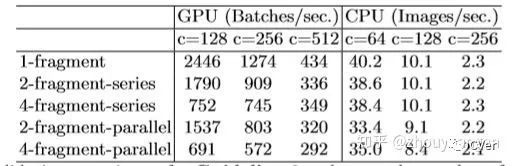
4. 网络结构的碎片化会减少可并行计算
这些碎片化更多是指网络中的多路径连接,类似于short-cut,bottle neck等不同层特征融合,还有如FPN。拖慢并行的一个很主要因素是,运算快的模块总是要等待运算慢的模块执行完毕。
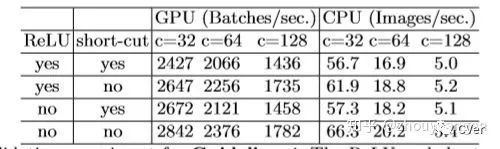
5. Element-wise操作会消耗较多的时间(也就是逐元素操作)
从表中第一行数据看出,当移除了ReLU和short-cut,大约提升了20%的速度。
以上是从此篇论文[2]中转译过来的设计原则,在实操中,这四条原则需要灵活使用。
根据以上几个原则进行网络的设计,可以将模型的参数量、访存量降低很大一部分。
接下来介绍一些自己总结的经验。
6. 网络的层数不宜过多
通常18层的网络属于深层网络,在设计时,应选择一个参考网络基线,我选择的是resnet18。由于Retinanet使用了FPN特征金字塔网络来融合各个不同尺度范围的特征,因此Retinanet仍然很“重”,需要尽可能压缩骨架网络的冗余,减少深度。
7. 首层卷积层用空洞卷积和深度可分离卷积替换
一个3x3,d=2的空洞卷积在感受野上,可以看作等效于5x5的卷积,提供比普通3x3的卷积更大的感受野,这在网络的浅层设计使用它有益。计算出网络各个层占有的MAC和参数量,将参数量和计算量“重”的卷积层替换成深度可分离卷积层,可以降低模型的参数量。
这里提供一个计算pytorch 模型的MAC和FLOPs的python packages[3]。
if __name__ == "__main__":
from ptflops import get_model_complexity_info
net = SNet(num_classes=1)
x = torch.Tensor(1, 3, 224, 224)
net.eval()
if torch.cuda.is_available():
net = net.cuda()
x = x.cuda()
with torch.cuda.device(0):
flops, params = get_model_complexity_info(net, (224, 224), print_per_layer_stat=True, as_strings=True, is_cuda=True)
print("FLOPS:", flops)
print("PARAMS:", params)
output:
(regressionModel): RegressionModel(
0.045 GMac, 27.305% MACs,
(conv1): Conv2d(0.009 GMac, 5.257% MACs, 128, 256, kernel_size=(1, 1), stride=(1, 1))
(act1): ReLU(0.0 GMac, 0.041% MACs, )
(conv2): Conv2d(0.017 GMac, 10.472% MACs, 256, 256, kernel_size=(1, 1), stride=(1, 1))
(act2): ReLU(0.0 GMac, 0.041% MACs, )
(conv3): Conv2d(0.017 GMac, 10.472% MACs, 256, 256, kernel_size=(1, 1), stride=(1, 1))
(act3): ReLU(0.0 GMac, 0.041% MACs, )
(output): Conv2d(0.002 GMac, 0.982% MACs, 256, 24, kernel_size=(1, 1), stride=(1, 1))
)
(classificationModel): ClassificationModel(
0.044 GMac, 26.569% MACs,
(conv1): Conv2d(0.009 GMac, 5.257% MACs, 128, 256, kernel_size=(1, 1), stride=(1, 1))
(act1): ReLU(0.0 GMac, 0.041% MACs, )
(conv2): Conv2d(0.017 GMac, 10.472% MACs, 256, 256, kernel_size=(1, 1), stride=(1, 1))
(act2): ReLU(0.0 GMac, 0.041% MACs, )
(conv3): Conv2d(0.017 GMac, 10.472% MACs, 256, 256, kernel_size=(1, 1), stride=(1, 1))
(act3): ReLU(0.0 GMac, 0.041% MACs, )
(output): Conv2d(0.0 GMac, 0.245% MACs, 256, 6, kernel_size=(1, 1), stride=(1, 1))
(output_act): Sigmoid(0.0 GMac, 0.000% MACs, )
)8. Group Normalization 替换 Batch Normalization
BN在诸多论文中已经被证明了一些缺陷,而训练目标检测网络耗费显存,开销巨大,通常冻结BN来训练,原因是小批次会让BN失效,影响训练的稳定性。建议一个BN的替代--GN,pytorch 0.4.1内置了GN的支持。
9. 减少不必要的shortcut连接和RELU层
网络不够深,没有必要使用shortcut连接,不必要的shortcut会增加计算量。RELU与shortcut一样都会增加计算量。同样RELU没有必要每一个卷积后连接(需要实际训练考虑删减RELU)。
10. 善用1x1卷积
1x1卷积可以改变通道数,而不改变特征图的空间分辨率,参数量低,计算效率也高。如使用kernel size=3,stride=1,padding=1,可以保证特征图的空间分辨率不变,1x1的卷积设置stride=1,padding=0达到相同的目的,而且1x1卷积运算的效率目前有很多底层算法支持,效率更高。[5x1] x [1x5] 两个卷积可以替换5x5卷积,同样可以减少模型参数。
11. 降低通道数
降低通道数可以减少特征图的输出大小,显存占用量下降明显。参考原则2
12. 设计一个新的骨架网络找对参考网络
一个好的骨架网络需要大量的实验来支撑它的验证,因此在工程上,参考一些实时网络结构设计自己的骨架网络,事半功倍。我在实践中,参考了这篇[4]paper的骨架来设计自己的轻量网络。
总结
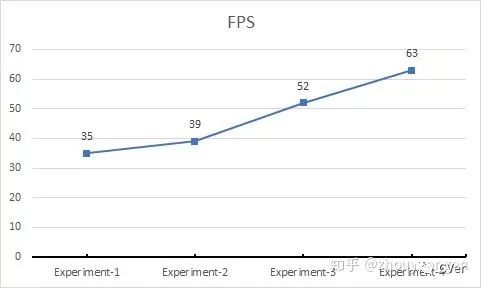
我根据以上的原则和经验对Retinanet进行瘦身,不仅局限于骨架的新设计,FPN支路瘦身,两个子网络(回归网络和分类网络)均进行了修改,期望性能指标FPS提升到63,增幅180%。
FPS
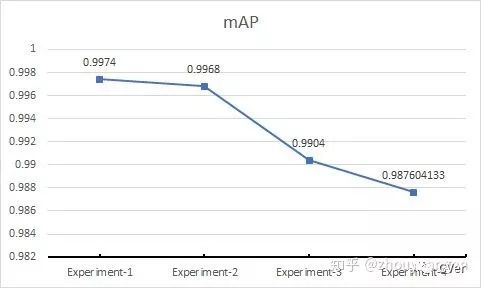
mAP
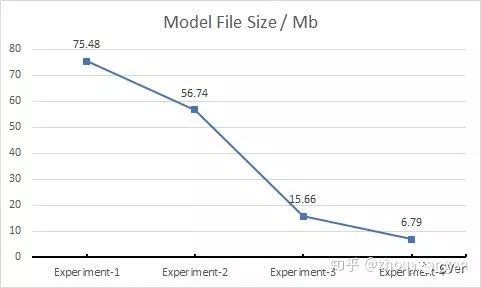
Model size
注:本文中部分观点参考来源
1 https://towardsdatascience.com/types-of-convolutions-in-deep-learning-717013397f4d
2 The Receptive Field, the Effective RF, and how it's hurting your results
https://www.linkedin.com/pulse/receptive-field-effective-rf-how-its-hurting-your-rosenberg/
3 https://arxiv.org/abs/1807.11164
4 mp.weixin.qq.com/s?
参考
Data Distillation Towards Omni-Supervised Learning
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
https://github.com/zhouyuangan/flops-counter.pytorch
ThunderNet: TowardsReal-timeGenericObjectDetection
CVer学术交流群
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、人群密度估计、姿态估计、强化学习和竞赛交流等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),不根据格式申请,一律不通过。

▲长按加群
这么硬的论文分享,麻烦给我一个在在看

▲长按关注我们
麻烦给我一个在看!

