车票?工作?对象?Python 教你优雅解决年关三大难题!


作者 | 数据不吹牛
-
合适的票买到了吗? -
你专业/工作到底是干啥的?工资多少? -
你对象呢?
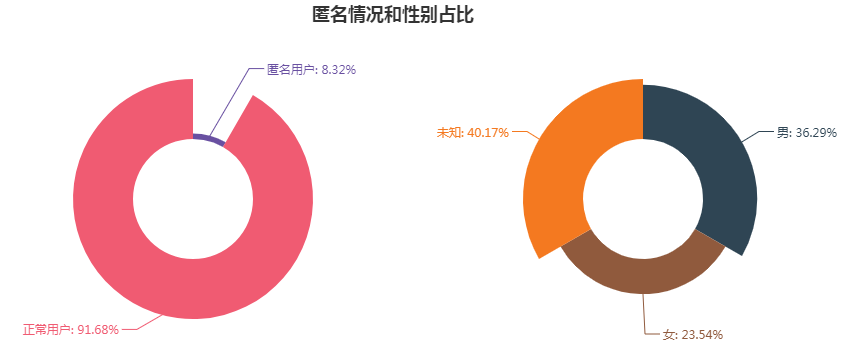
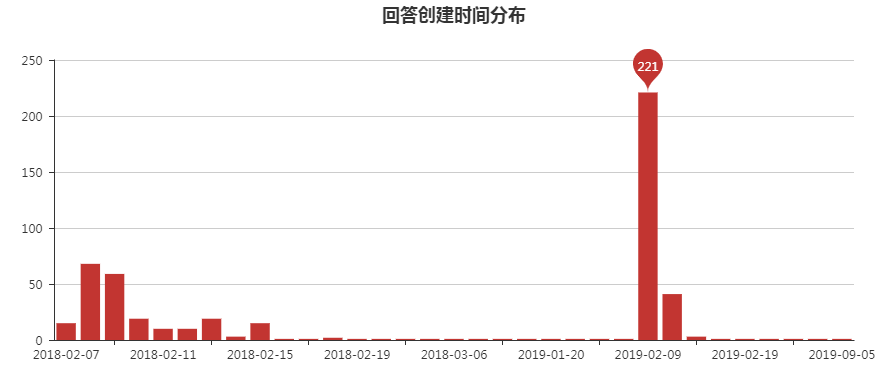
知乎的部分爬取代码如下,完整代码和数据附在文末,跳过丝毫不影响阅读。
import pandas as pd
import numpy as np
import os
import json
import requests
def parse_page(url,headers):
html = requests.get(url,headers = headers)
bs = json.loads(html.text)
result = pd.DataFrame()
for i in bs['data']:
headline = i['author']['headline'] #签名
gender = i['author']['gender'] #性别
user_type = i['author']['user_type']
user_id = i['author']['id']
user_token = i['author']['url_token']
follwer_count = i['author']['follower_count'] #关注人数
name = i['author']['name'] #用户昵称
vote_up = i['voteup_count'] #点赞数
updated_time = i['updated_time'] #更新时间
title = i['question']['title'] #问题
created_time = i['created_time'] #创建时间
comment_count = i['comment_count'] #评论数
can_comment = i['can_comment']['status'] #是否可以评论
content = i['content'] #内容,还需要再清洗
cache = pd.DataFrame({'用户ID':[user_id],'用户名':[name],'性别':[gender],'token':[user_token],'用户类型':[user_type],'签名':[headline],
'被关注人数':[follwer_count],'创建时间':[created_time],'更新时间':[updated_time],'评论数':[comment_count],
'点赞数':[vote_up],'是否可以评论':[can_comment],'内容':[content],'问题':[title]})
result = pd.concat([result,cache])
return result


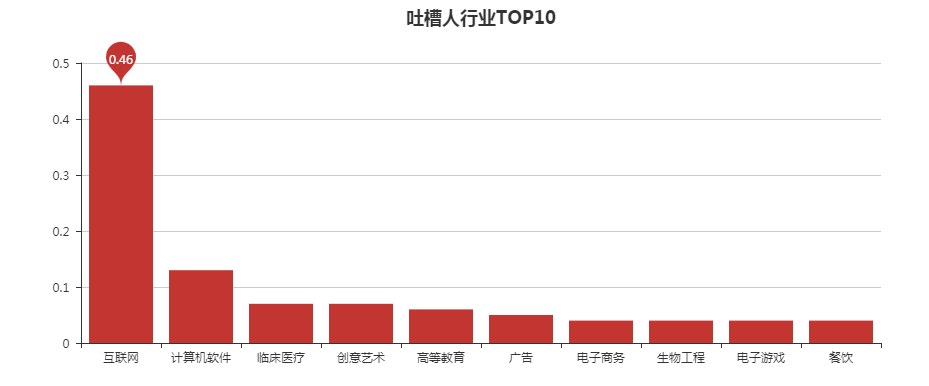


代码:
https://github.com/seizeeveryday/DA-cases/tree/master/Zhihu


热 文 推 荐
☞好扑科技技术副总裁戎朋:从海豚浏览器技术负责人到区块链,揭秘区块链技术之路






