文本理解是腾讯 AI Lab 重点关注的研究方向,自然语言理解系统 TexSmart 就是腾讯 AI Lab 在该领域实现的一项重要应用。本届 ACL,腾讯 AI Lab 继续呈现了在这一领域的最新探索成果,其中包括对长文本阅读理解的新解决方案、从高资源语言向低资源语言的泛化研究、基于对话的关系抽取以及新型关键词生成技术。
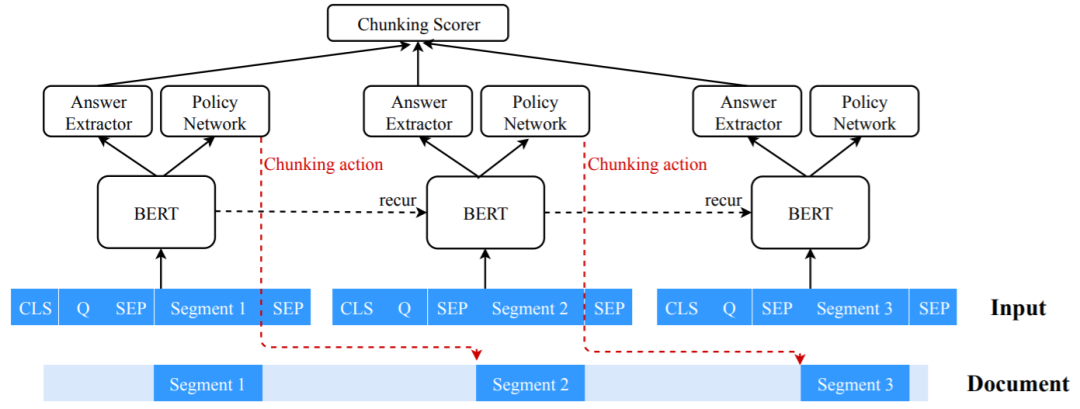
1. 长文阅读理解中的循环分块机制
Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension
论文:https://arxiv.org/abs/2005.08056
本文由腾讯 AI Lab 独立完成,提出了一种可用以提升长文本阅读理解任务的循环分块机制,并有可能为其它类型的长文本任务带来启发。
本文由腾讯 AI Lab 主导,与香港科技大学合作完成,提出了一种通过元学习实现低资源语言上下位预测。该方法可用于指导多语言、低资源的上下位预测的实现,并能给词汇级别的语义理解提供启发。
上下位预测是语义理解中重要的子任务,在问答系统和知识挖掘等任务中发挥着重要作用。但目前希腊语和荷兰语等低资源语言的上下位预测缺乏足够用于监督训练的标注数据。本文提出和探讨的问题是如何利用高资源语言(比如英语)的丰富数据帮助低资源语言的泛化学习。其中论文的基本假设是来自于人类对于概念认知的语言无关性,例如苹果和 apple 指的是同样的概念。文中设计实验分别比较了跨语言训练、多语言联合训练和元学习这三种不同的混合训练方式,结果表明简单的多语言联合训练并不会帮助低资源语言的学习,但论文中首次提出的元学习的方式可以通过学到一个适用于多种语言的模型初始化来有效地避免模型过拟合小数据,从而可实现在低资源语言上下位预测任务上的性能提升。
3. 基于对话的关系抽取
Dialogue-Based Relation Extraction
论文:https://arxiv.org/abs/2004.08056
代码:https://github.com/nlpdata/dialogre
数据集:https://dataset.org/dialogre
本文由腾讯 AI Lab 主导,与康奈尔大学合作完成,本文首次定义了基于对话的关系抽取任务并填补了对话型通用关系抽取数据资源的空白,在这一未被充分研究的领域走出了第一步。
本文提出了第一个标注的基于对话的关系抽取(RE)数据集DialogRE,旨在支持对出现在对话中的两个元素之间的关系进行预测。由于大多数事实跨越多个句子,我们进一步提供DialogRE作为研究跨句RE的平台。基于对对话型RE任务与传统RE任务之间的异同的仔细分析,我们提出说话者相关的信息在该任务中起着至关重要的作用。考虑到对话中交流的及时性,我们设计了一种新的指标来评估对话环境中 RE 方法的性能,并调研了 DialogRE 上几种具有代表性的RE方法的性能。实验结果表明,在表现最佳的基线模型上显示识别说话人元素在两种评价指标上都能带来性能提高。
DialogRE 数据集中的一段对话和相关实例
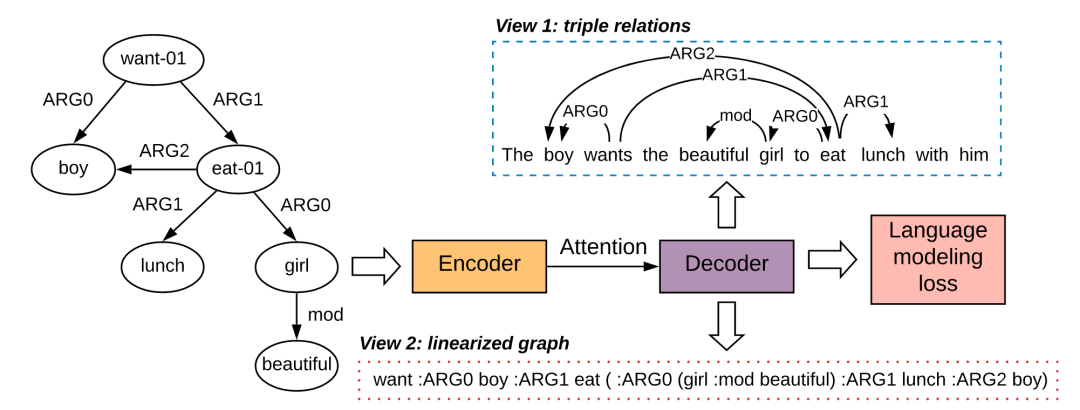
4. 图到文本生成中的结构化信息保留
Structural Information Preserving for Graph-to-Text Generation
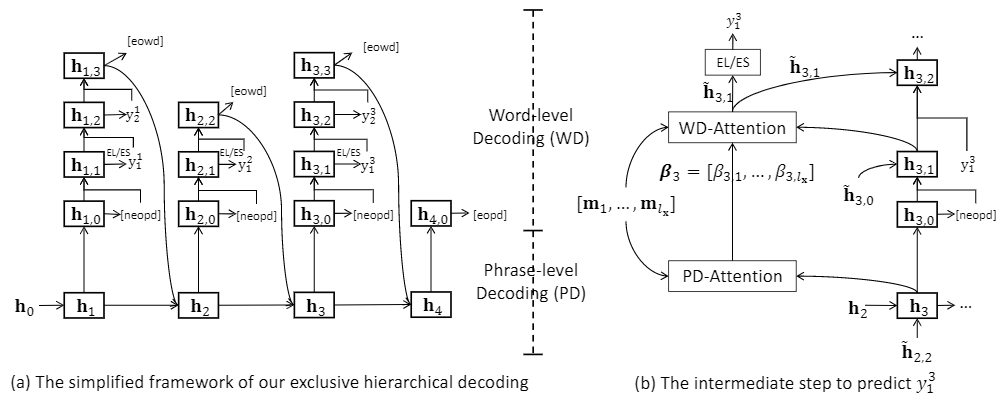
Exclusive Hierarchical Decoding for Deep Keyphrase Generation
论文:https://arxiv.org/abs/2004.08511
本文由腾讯 AI Lab 与香港中文大学合作完成,提出了一个简单有效的层次解码策略,可以一次性生成多样且准确的关键词。
关键词生成(KG)的目的是将文档的主要思想概括成一组关键词。最近在这个问题中引入了一种新的设置:给定一个文档,模型需要预测一组关键词,并同时确定要生成的关键词的适当数量。此前的工作在此设置中采用了一种顺序解码过程来生成关键词。然而,这样的解码方法忽略了文档中的关键词中存在的内在层次性。此外,以前的工作往往会产生重复的关键词,进而造成时间和计算资源浪费。为了克服这些局限性,本文提出了一种互斥分层解码框架,该框架包括一个分层解码过程和软性或硬性互斥机制。分层解码过程是为了显式地建模一个关键词集合的分层构成性。软互斥机制和硬互斥机制都会在一定的窗口大小内保持对之前预测的关键词的跟踪,以增强生成的关键词的多样性。我们在多个 KG 基准数据集上进行了大量实验,结果证明新提出的方法可以有效生成更少重复和更准确的关键词。
新提出的互斥分层解码框架示意图。h_i 是第 i 个短语级解码步骤的隐藏状态,h_{i,j} 是对应的第 j 个词级解码隐藏状态