深度学习面试100题(第46-50题)
46、你如何判断一个神经网络是记忆还是泛化?
解析:
具有许多参数的神经网络具有记忆大量训练样本的能力。那么,神经网络是仅仅记忆训练样本(然后简单地根据最相似的训练点对测试点进行分类),还是它们实际上是在提取模式并进行归纳?这有什么不同吗?
人们认为存在不同之处的一个原因是,神经网络学习随机分配标签不同于它学习重复标签的速度。这是 Arpit 等人在论文中使用的策略之一。让我们看看是否有所区别?
方法: 首先我们生成一个 6 维高斯混合,并随机分配它们的标签。我们测量训练数据的正确率,以增加数据集的大小,了解神经网络的记忆能力。然后,我们选择一个神经网络能力范围之内的数据集大小,来记忆并观察训练过程中神经网络与真实标签之间是否存在本质上的差异。特别是,我们观察每个轮数的正确率度,来确定神经网络是真正学到真正的标签,还是随机标签。
假设: 我们预计,对随机标签而言,训练应该耗费更长的时间。而真正标签则不然。

运行实验所需的时间: 432.275 s
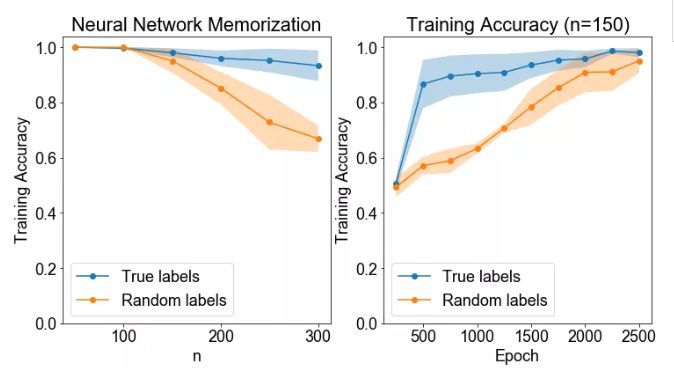
结论: 神经网络的记忆能力约为 150 个训练点。但即便如此,神经网络也需要更长的时间来学习随机标签,而不是真实值(ground truth)标签。
讨论: 这个结果并不令人感到意外。我们希望真正的标签能够更快的学到,如果一个神经网络学会正确地分类一个特定的数据点时,它也将学会分类其他类似的数据点——如果标签是有意义的,但前提它们不是随机的!
47、无监督降维提供的是帮助还是摧毁?
解析:
当处理非常高维的数据时,神经网络可能难以学习正确的分类边界。在这些情况下,可以考虑在将数据传递到神经网络之前进行无监督的降维。这做法提供的是帮助还是摧毁呢?
方法:我们生成两个10维高斯混合。高斯具有相同的协方差矩阵,但在每个维度上都有一个由 1 隔开的均值。然后,我们在数据中添加“虚拟维度”,这些特征对于两种类型的高斯都是非常低的随机值,因此对分类来说没有用处。
然后,我们将结果数据乘以一个随机旋转矩阵来混淆虚拟维度。小型数据集大小 (n=100) 使神经网络难以学习分类边界。因此,我们将数据 PCA 为更小的维数,并查看分类正确率是否提高。
假设:我们预计 PCA 将会有所帮助,因为变异最多的方向(可能)与最有利于分类的方向相一致。
运行实验所需的时间: 182.938 s

结论: 当维度非常大时,无监督的 PCA 步骤可以显著改善下游分类。
讨论: 我们观察到一个有趣的阈值行为。当维数超过 100 时(有趣的是,这数字是数据集中数据点的数量——这值得进一步探讨),分类的质量会有显著的下降。在这些情况下,5~10 维的 PCA 可显著地改善下游分类。
48、是否可以将任何非线性作为激活函数?
解析:
在通过具有超出典型 ReLU() 和 tanh() 的特殊激活函数的神经网络获得小幅提高的研究,已有多篇论文报道。我们并非试图开发专门的激活函数,而是简单地询问它是否可能在神经网络中使用任何旧的非线性函数?
方法:我们生成著名的二维卫星数据集,并训练一个具有两个隐藏层的神经网络来学习对数据集进行分类。我们尝试了六种不同的激活函数。
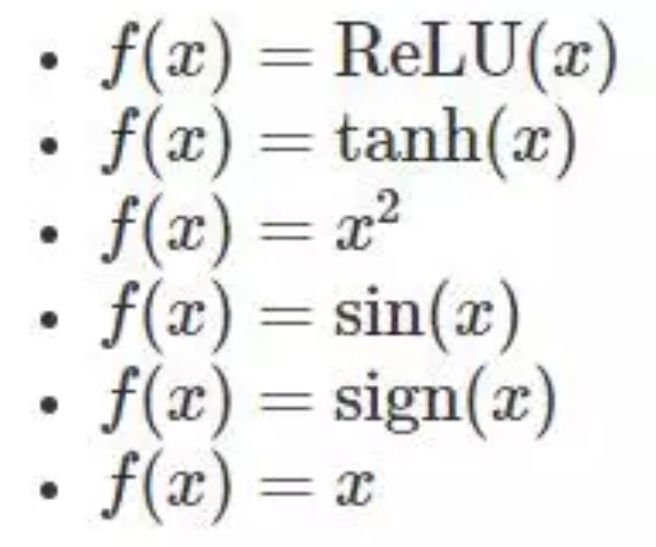
假设:我们预计恒等函数执行很差(因为直到最后一个 softmax 层,网络仍然保持相当的线性)。我们可能会进一步期望标准的激活函数能够发挥最好的效果。
运行实验所需的时间: 22.745 s

结论:除去 sign(x) 外,所有的非线性激活函数对分类任务都是非常有效的。
讨论:结果有些令人吃惊,因为所有函数都同样有效。事实上,像 x2 这样的对称激活函数表现得和 ReLUs 一样好!从这个实验中,我们应该谨慎地推断出太多的原因。
49、批大小如何影响测试正确率?
解析:
方法:我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但在每个维度上都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们在这个数据集上训练一个神经网络,使用不同的批大小,从 1 到 400。我们测量了之后的正确率。
假设:我们期望较大的批大小会增加正确率(较少的噪声梯度更新),在一定程度上,测试的正确率将会下降。我们预计随着批大小的增加,运行时间应有所下降。
运行实验所需的时间: 293.145 s
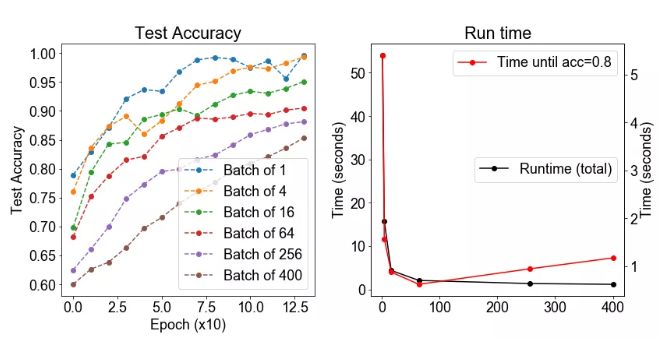
结论:正如我们预期那样,运行时间确实随着批大小的增加而下降。然而,这导致了测试正确率的妥协,因为测试正确率随着批大小的增加而单调递减。
讨论:这很有趣,但这与普遍的观点不一致,严格来说,即中等规模的批大小更适用于训练。这可能是由于我们没有调整不同批大小的学习率。因为更大的批大小运行速度更快。总体而言,对批大小的最佳折衷似乎是为 64 的批大小。
50、损失函数重要吗?
解析:
对于分类任务,通常使用交叉熵损失函数。如果我们像通常在回归任务中那样使用均方差,结果会怎么样?我们选择哪一个会很重要么?
方法: 我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但在每个维度上都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们使用几种不同的函数在这个数据集上训练一个神经网络,以确定最终正确率是否存在系统差异。作为阴性对照,包括一个不变的损失函数。
假设: 我们预计交叉熵损失函数作为分类任务的标准损失函数,表现最好,同时我们预计其他损失函数表现不佳。
运行实验所需的时间: 36.652 s

结论: 除去阴性对照外,所有的损失都有类似的表现。损失函数是标签与逻辑之间的区别,提升到四次幂,其性能要比其他差一些。
讨论: 损失函数的选择对最终结果没有实质影响,这也许不足为奇,因为这些损失函数非常相似。
题目来源:
七月在线官网(https://www.julyedu.com/)——面试题库——面试大题——深度学习 第46-50题。

深度学习是机器学习的一个分支。深度学习除了可以学习特征和任务之间的关联以外,还能自动从简单特征中提取更加复杂的特征。深度学习算法可以从数据中学习更加复杂的特征表达,使得最后一步权重学习变得更加简单且有效。
为了帮助大家系统地学习机器学习课程的相关知识,我们特意推出了机器学习集训营系列课程。迄今为止,「机器学习集训营」已经举办了四期,每一期都涌现出了不少优秀offer,特别是上一期很多同学从Java、Android、iOS等传统IT行业成功转行转型转岗AI拿到年薪三四十万,部分甚至超过四十万拿到五十万。
本第五期,在第四期的基础上,除了继续维持“入学测评、直播答疑、布置作业、阶段考试、毕业考核、一对一批改、线上线下结合、CPU&GPU双云平台、组织比赛、面试辅导、就业推荐”十一位一体的教学模式,本期特地推出机器学习工程师联合认证。且线下在北京、上海、深圳、广州、杭州、沈阳、济南、郑州、成都的基础上,新增武汉、西安两个线下点,十一城同步开营。
此外,本期依然沿用前四期线上线下相结合的授课方式,加强项目实训的同时引入线下BAT专家面对面、手把手的教学方式;突出BAT级工业项目实战辅导 + 一对一面试求职辅导,并提供一年GPU云实验平台免费使用,精讲面试考点。让每一位学员不用再为遇到问题没人解答,缺乏实战经验以及简历上没有项目经验,面试屡屡遭拒而发愁。
本期限150个名额,历时3个月,10多个BAT级工业项目,保障每一位学员所学更多、效率更高、收获更大。
机器学习集训营 第五期 课程详情可点击文末“阅读原文”进行查看,或者加微信客服:julyedukefu_02进行咨询。
扫码加客服微信





