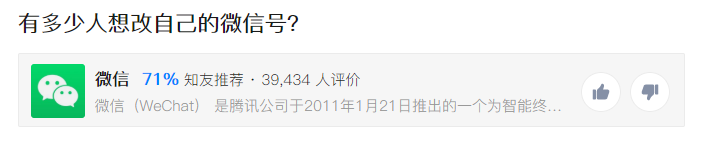
微信改号?我用 Python 发现了六大隐藏秘密......



def parse_page(url,headers):html = requests.get(url,headers = headers)bs = json.loads(html.text)result = pd.DataFrame()for i in bs['data']:headline = i['author']['headline'] #签名gender = i['author']['gender'] #性别user_type = i['author']['user_type']user_id = i['author']['id']user_token = i['author']['url_token']follwer_count = i['author']['follower_count'] #关注人数name = i['author']['name'] #用户昵称vote_up = i['voteup_count'] #点赞数updated_time = i['updated_time'] #更新时间title = i['question']['title'] #问题created_time = i['created_time'] #创建时间comment_count = i['comment_count'] #评论数can_comment = i['can_comment']['status'] #是否可以评论content = i['content'] #内容,还需要再清洗cache = pd.DataFrame({'用户ID':[user_id],'用户名':[name],'性别':[gender],'token':[user_token],'用户类型':[user_type],'签名':[headline],'被关注人数':[follwer_count],'创建时间':[created_time],'更新时间':[updated_time],'评论数':[comment_count],'点赞数':[vote_up],'是否可以评论':[can_comment],'内容':[content],'问题':[title]})result = pd.concat([result,cache])return resultdef run_all(url,headers,num = 5):final_result = pd.DataFrame()num = num * 5for i in range(0,num + 5,5):try:result = parse_page(url.format(5,i),headers)final_result = pd.concat([final_result,result])time.sleep(random.random())print('i had parsed:',i)except:try:time.sleep(5)result = parse_page(url.format(i,5),headers)final_result = pd.concat([final_result,result])time.sleep(random.random())print('i had parsed:',i)except:print(i,'is wrong~~~')return final_result

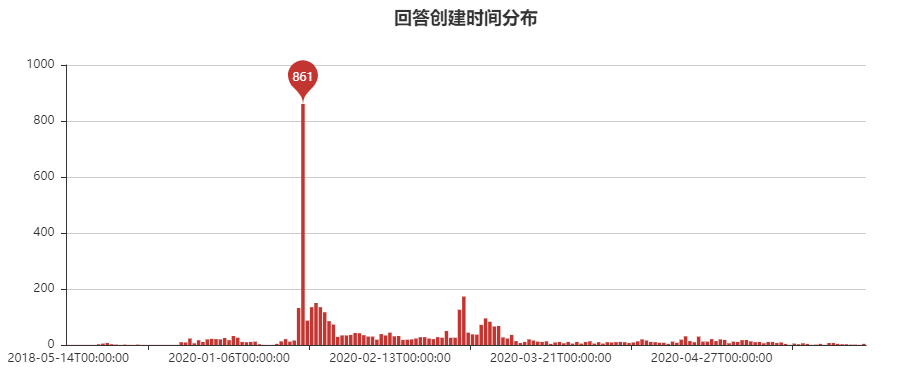
18年5月14日,该问题下第一个想改的人给出了首答。然时机未到,问题就此沉寂。
及至19年9月,新增了一些零零散散的抱怨和吐槽,但仍未成势。
时间来到了2020年1月,上旬日均15个人前来吐槽。1月24日是高光时刻,861个日新增回答彻底引爆了话题,顺势带了一波接下来话题的热度。
截至爬取,累计回答4277条,累计点赞超11万。刚看了一眼,回答数又在飙升......



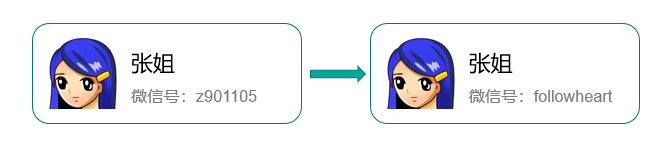
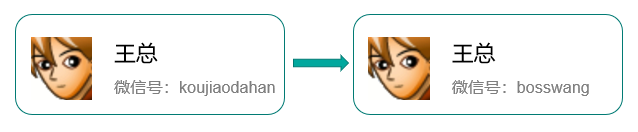
同学,你微信多少啊? “ooo000ooOOO-O” “哦?算了我加你吧” “那你微信多少啊?” “zZzzZZZzzzzZZZ" “咱们还是扫码吧!”


【END】
更多精彩推荐
☞加码 2000 亿新基建还不够,阿里云再放话:今年招 5000 人!
![]()
你点的每个“在看”,我都认真当成了喜欢

登录查看更多
相关内容

专知会员服务
35+阅读 · 2020年1月6日
Arxiv
5+阅读 · 2018年8月6日
Arxiv
13+阅读 · 2018年1月18日
Arxiv
3+阅读 · 2017年12月14日





相关VIP内容
专知会员服务
35+阅读 · 2020年1月6日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年8月6日
Arxiv
13+阅读 · 2018年1月18日
Arxiv
3+阅读 · 2017年12月14日