Sutton 强化学习, 21 点游戏的策略蒙特卡洛值预测


从这期开始我们进入 Sutton 强化学习第二版,第五章蒙特卡洛方法。蒙特卡洛方法是一种在工程各领域都存在的基本方法,在强化领域中,其特点是无需知道环境的 dynamics,只需不断模拟记录并分析数据即可逼近理论真实值。蒙特卡洛方法本篇将会用21点游戏作为示例来具体讲解其原理和代码实现。

-
已发的牌的无状态性:和一副牌的21点游戏不同的是,游戏环境简化为牌是可以无穷尽被补充的,一副牌的某一张被派发后,同样的牌会被补充进来,或者可以认为每次发放的牌都是从一副新牌中抽出的。统计学中的术语称为重复采样(sample with replacement)。这种规则下极端情况下,玩家可以拥有 5个A或者5个2。另外,这会导致玩家无法通过开局看到的3张牌的信息推断后续发牌的概率,如此就大规模减小了游戏状态数。 -
庄家和玩家独立游戏,无需按轮次要牌。开局给定4张牌后,玩家先行动,加牌直至超21点或者停止要牌,如果超21点,玩家输,否则,等待庄家行动,庄家加牌直至超21点或者停止要牌,如果超21点,庄家输,否则比较两者的总点数。这种方式可以认为当玩家和庄家看到初始的三张牌后独立做一系列决策,最后比较结果,避免了交互模式下因为能观察到每一轮后对方牌数变化产生额外的信息而导致的游戏状态数爆炸。
-
自己手中的点数和(12到21) -
庄家明牌的点数(A到10) -
庄家明牌是否有 A(True, False)。

21点游戏 OpenAI Gym环境
from gym.envs.toy_text import BlackjackEnvState = Tuple[int, int, bool]Action = boolReward = floatStateValue = Dict[State, float]DeterministicPolicy = Callable[[State], Action]
以下代码是 BlackjackEnv 核心代码,step 方法的输入为玩家的决策动作(叫牌还是结束),并输出 State, Reward, is_done。简单解释一下代码逻辑,当玩家继续加牌时,需要判断是否超21点,如果没有超过的话,返回下一状态,同时 reward 为0,等待下一 step 方法。若玩家停止叫牌,则按照庄家策略:小于17时叫牌。游戏终局时产生+1表示玩家获胜,-1表示庄家获胜。
class BlackjackEnv(gym.Env):def step(self, action):assert self.action_space.contains(action)if action: # hit: add a card to players hand and returnself.player.append(draw_card(self.np_random))if is_bust(self.player):done = Truereward = -1.else:done = Falsereward = 0.else: # stick: play out the dealers hand, and scoredone = Truewhile sum_hand(self.dealer) < 17:self.dealer.append(draw_card(self.np_random))reward = cmp(score(self.player), score(self.dealer))if self.natural and is_natural(self.player) and reward == 1.:reward = 1.5return self._get_obs(), reward, done, {}def _get_obs(self):return (sum_hand(self.player), self.dealer[0], usable_ace(self.player))
下面示例如何调用 step 方法生成一个 episode 的数据集。数据集的类型为 List[Tuple[State, Action, Reward]]。
def gen_episode_data(policy: DeterministicPolicy, env: BlackjackEnv) -> List[Tuple[State, Action, Reward]]:episode_history = []state = env.reset()done = Falsewhile not done:action = policy(state)next_state, reward, done, _ = env.step(action)episode_history.append((state, action, reward))state = next_statereturn episode_history

策略的蒙特卡洛值预测
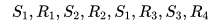
First-visit 对于状态 S1 的 Returns 计算为
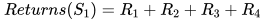
Every-visit 对于状态 S1 的 Returns 计算了两次,因为 S1 出现了两次。
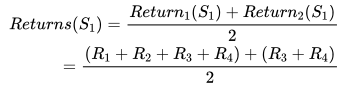
下面用 Monte Carlo 来模拟解得书中示例玩家固定策略的 V值,策略具体为:加牌直到手中点数>=20,代码为
def fixed_policy(observation):"""sticks if the player score is >= 20 and hits otherwise."""score, dealer_score, usable_ace = observationreturn 0 if score >= 20 else 1

First-visit MC Predicition
伪代码如下,注意考虑到实现上的高效性,在遍历 episode 序列数据时是从后向前扫的,这样可以边扫边更新 G。

对应的 python 实现
def mc_prediction_first_visit(policy: DeterministicPolicy, env: BlackjackEnv,num_episodes, discount_factor=1.0) -> StateValue:returns_sum = defaultdict(float)returns_count = defaultdict(float)for episode_i in range(1, num_episodes + 1):episode_history = gen_episode_data(policy, env)G = 0for t in range(len(episode_history) - 1, -1, -1):s, a, r = episode_history[t]G = discount_factor * G + rif not any(s_a_r[0] == s for s_a_r in episode_history[0: t]):returns_sum[s] += Greturns_count[s] += 1.0V = defaultdict(float)V.update({s: returns_sum[s] / returns_count[s] for s in returns_sum.keys()})return V

Every-visit MC Prediciton
Every-visit 代码实现相对更简单一些,t 从后往前遍历时更新对应 s 的状态变量。如下所示
def mc_prediction_every_visit(policy: DeterministicPolicy, env: BlackjackEnv,num_episodes, discount_factor=1.0) -> StateValue:returns_sum = defaultdict(float)returns_count = defaultdict(float)for episode_i in range(1, num_episodes + 1):episode_history = gen_episode_data(policy, env)G = 0for t in range(len(episode_history) - 1, -1, -1):s, a, r = episode_history[t]G = discount_factor * G + rreturns_sum[s] += Greturns_count[s] += 1.0V = defaultdict(float)V.update({s: returns_sum[s] / returns_count[s] for s in returns_sum.keys()})return V

策略 V值 3D 可视化
运行 first-visit 算法,模拟10000次 episode,fixed_policy 的 V值 的3D图为下面两张图,分别是不含 usable Ace 和包含 usable Ace 。总的说来,一旦玩家能到达20点或21点获胜概率极大,到达13-17获胜概率较小,在11-13时有一定获胜概率,比较符合经验直觉。
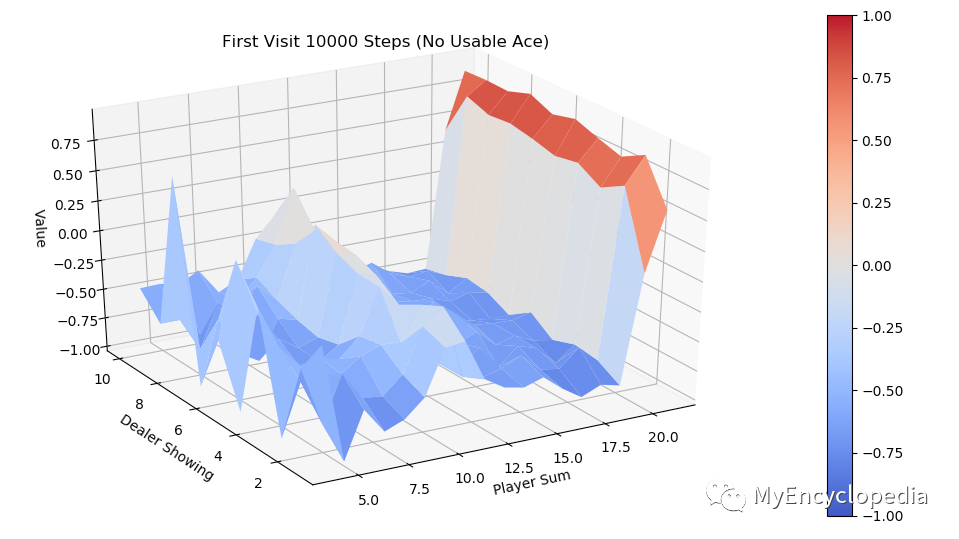
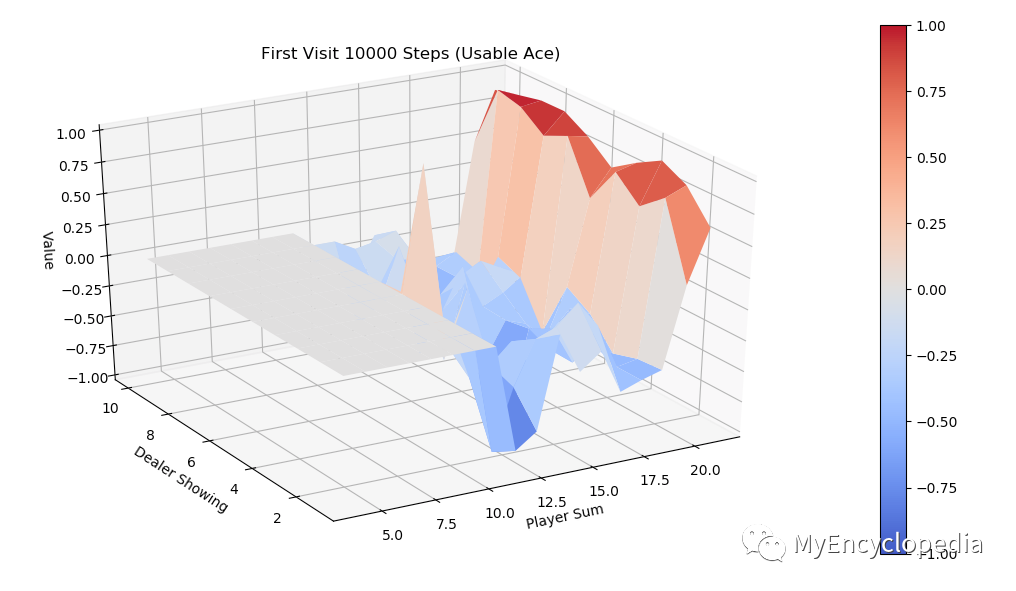
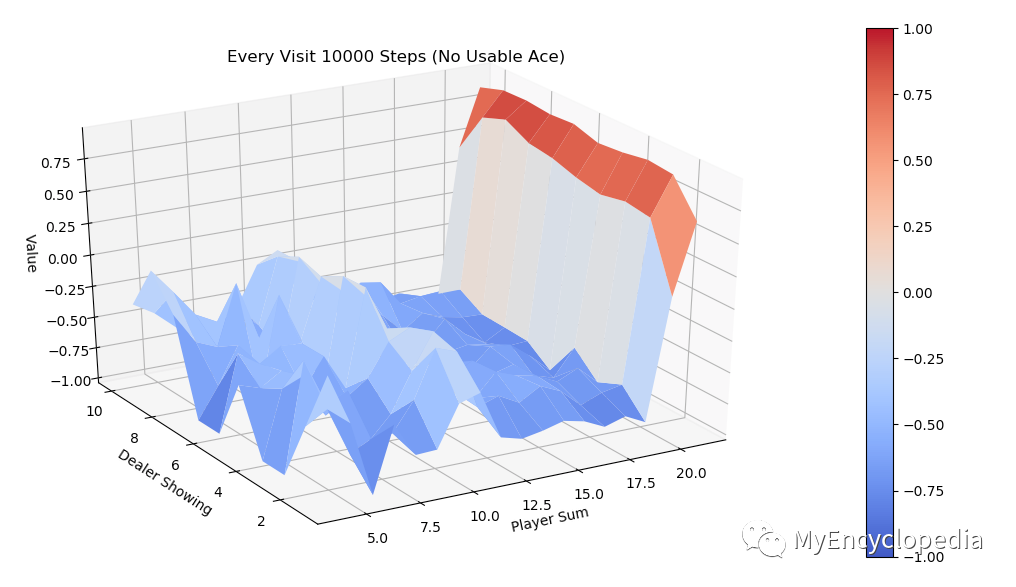
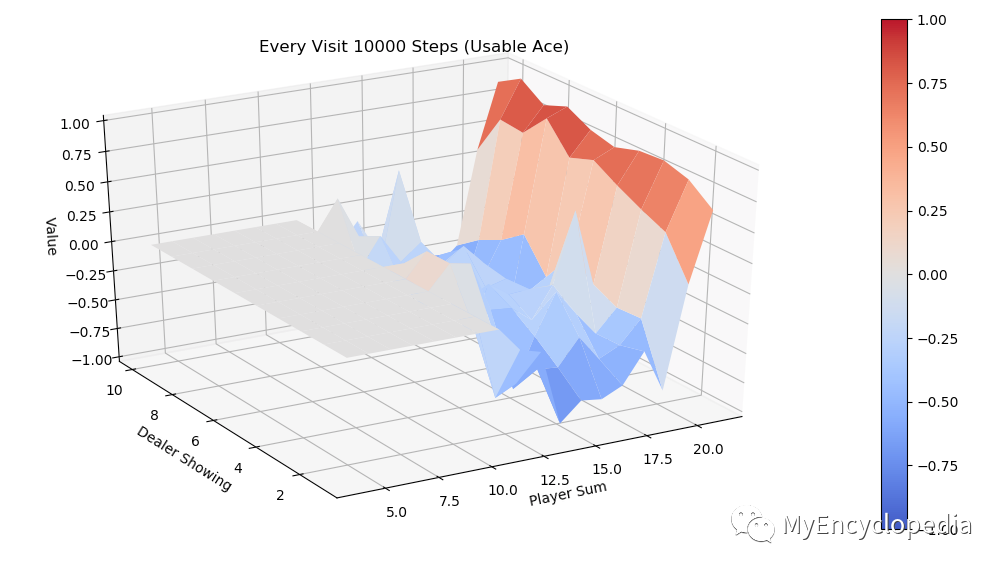
同样运行 every-visit 算法,模拟10000次的 V值 图。对比两种方法结果比较接近。


更多精彩推荐
☞“我们的边缘计算技术点,可能超前了业界一点”☞1024程序员节开源技术英雄会,参会“英雄榜”发榜☞区块链+生鲜:杜绝“偷梁换柱”和“以次充好”
![]()
点分享
![]()
点点赞
![]()
点在看








