五角大楼已选择谷歌云“政府版Gemini”作为其新型GenAI.mil平台上的首个生成式人工智能模型,该平台是一个旨在将人工智能工具引入日常军事工作的安全环境。此举标志着美军正大力推动人工智能在全军范围的大规模应用,从参谋业务到作战决策支持。
2025年12月9日,五角大楼正式推出GenAI.mil,这是一个将商用级人工智能引入日常军事工作流程的专用环境,并选择谷歌云“政府版Gemini”作为该平台的首个模型。国防部长皮特·赫格塞斯将此次发布描述为一项审慎的工作,旨在将前沿人工智能工具直接交到全球军人、文职人员和承包商手中,其早期应用侧重于那些未分类但量大、拖慢全军行动效率的任务。

图:五角大楼已推出GenAI.mil,这是一个以谷歌“政府版Gemini”为首个模型的安全人工智能平台,旨在加速人工智能在美国军队中的应用。该系统旨在支持参谋工作、分析和决策制定,代表着将商用生成式人工智能工具整合到日常防务运营中的重大一步。
美国国防部将GenAI.mil描述为一个定制的AI环境,最终将承载多个商用模型,其中“政府版Gemini”作为首发能力提供服务。根据官方发布的消息,该平台旨在培养一支“人工智能优先”的劳动力队伍,其工具设计用于加速研究、参谋业务和作战决策支持,同时保持在政府安全飞地的范围内。访问权限仅限于拥有国防部凭证的人员,且这些工具经认证可处理“影响等级5”的受控非密信息,该安全等级允许在许多作战环境中使用。
“政府版Gemini”本身结合了自然语言交互、检索增强生成以及与谷歌搜索绑定的网络验证输出,国防部称这将提高可靠性并有助于限制“幻觉”现象。五角大楼官员表示,实际上,第一波用例将是非密但高度实用的:总结冗长的政策文件、生成合规检查清单、起草信函、分析图像和视频,以及自动化当前耗费数千人时的常规参谋流程。谷歌强调,只有非密数据会流经该系统,并且GenAI.mil的输入和输出不会用于训练其面向公众的模型,这一保证显然是针对此前对五角大楼人工智能项目的批评者。
对美国陆军而言,GenAI.mil建立在一个本已密集的人工智能现代化议程之上,该议程包括“关键项目”的人工智能流水线、“泰坦”情报地面站,以及在“联合全域指挥与控制”愿景下更广泛的数据架构。“关键项目”旨在提供可信的机器学习运维骨干,使传感器项目能够大规模部署和更新人工智能模型,而“泰坦”卡车正开始部署到作战部队,以融合多域情报实现更快速的目标锁定。在此背景下,Gemini很可能成为陆军人工智能的“前厅办公室”,处理参谋层级的分析、知识管理和规划支持,而其他项目则专注于战术边缘的部署和时效性强的作战行动。
指挥官和参谋军官可能会很快看到其吸引力。一个旅的S2情报部门可能使用GenAI.mil根据多个报告流自动生成情报评估更新,而一个炮兵火力单元可以要求该模型将目标锁定指导、交战规则和当前空域管制措施整合成一份简洁可读的简报。训练司令部可能会依赖Gemini来创建针对特定单位的想定注入、评估标准和反馈报告。这些都不会取代已部署的火力控制或作战管理系统,但可以压缩围绕这些系统的行政流程,使士兵能专注于决策而非制作幻灯片。
此次发布的时机具有战略考量:国防部明确将GenAI.mil与7月一项呼吁实现前所未有人工智能技术优势的总统指令联系起来,高层领导人认为,在军事人工智能的全球竞赛中没有亚军奖项。对于关注华盛顿下一步行动的欧洲和北约而言,这是另一个信号,表明美国正在推动商用生成式人工智能在国防领域的大规模常态化使用,与此同时北约自身也在推广源自“马文计划”、基于Palantir公司技术的人工智能系统。
尽管拥有“影响等级5”的安全认证和网络验证保障,GenAI.mil的使用仍将取决于用户层级的负责任使用:规范的输入、对敏感数据的正确处理,以及指挥官需将人工智能理解为会犯错(而非全知)的助手。五角大楼官员表示,为所有员工提供的免费培训课程旨在培养这种判断力,但在约300万潜在用户中实现文化变革需要数年而非数周时间。然而,对于已经在应对数据过载的陆军编队而言,发展方向是明确的。生成式人工智能已从实验阶段走向基础设施,GenAI.mil是美国意图将商用大语言模型直接编织到部队日常作战节奏中、用以打赢未来战争的最清晰意图。
参考来源:armyrecognition

人工智能的出现将如何塑造地缘政治竞争的逻辑,尤其是在大国之间?各国已经开始将复杂的人工智能系统纳入其军事态势、外交工具包和决策过程。在哈佛大学肯尼迪学院,一个由阿纳托利·列夫辛组织、隶属于贝尔弗中心"新兴技术、科学进步与全球政策"项目的研究小组,致力于通过探究人工智能在军事化讨价还价和危机外交中的替代性用途,来理解这些变革。本白皮书报告了他们的发现和政策建议。
将人工智能整合到国防和国家安全领域正成为全球优先事项。就本报告而言,将人工智能定义为能够执行通常需要人类智能(如感知、学习、推理和决策)的任务,并能在动态环境中以不同程度的自主性运行的数字或物理系统。据估计,全球人工智能军事支出在2022年至2023年间翻了一番。军队正在利用人工智能以实现更高的作战效率和准确性,从而获得对抗对手的战略优势。然而,这些努力并非新事物。在1966年至1972年间,斯坦福研究所开发了"摇摇晃晃"机器人,它使用计算机视觉和语言处理来感知和理解周围环境,并做出决策和执行任务。20世纪80年代末,美国开发了"动态分析与重计划工具"——一款旨在优化人员与物资运输的人工智能软件。与此同时,自主机器人和无人机等无人武器系统也处于研发中。
然而,在2017年之前,人工智能远非战略军事优先事项。2017年4月,美国国防部设立了"算法战跨职能小组",以加速国防部对大数据和机器学习的整合。几个月后,俄罗斯总统预言,人工智能领域的领导地位将成为未来全球主导权的关键。或许最具意义的发展并非来自政治层面。2017年6月,谷歌发布了一篇题为"注意力就是一切"的开创性论文,介绍了Transformer架构,这是一种彻底改变了人工智能产业的深度学习架构。它使得创建称为基础模型的通用语言模型成为可能。与为单一、特定任务设计和训练的传统人工智能模型不同,基础模型被构建为通用型。这意味着它们能对训练数据中的模式、结构和关系有广泛的理解。基础模型最突出的例子包括Anthropic公司的Claude、谷歌的Gemini和OpenAI的ChatGPT。基础模型可以针对各种用例进行定制,包括军事应用。
这一发展产生了三个广泛的影响。首先,快速准确地处理海量数据的能力开启了一个充满新颖军事应用的世界。在"注意力就是一切"论文发表不到十年后,以色列的"薰衣草"和"福音"系统或Palantir公司的"MetaConstellation"平台等人工智能驱动的解决方案已在实战冲突中部署,用于精确目标锁定。人工智能的其他用例还包括兵棋推演与可信战略生成、装备维护需求预测以及后勤规划。其次,基础模型降低了经济规模较小国家将人工智能整合到军事领域的门槛。打造可用的人工智能模型需要大量人力资本、研究计算资源和高质量数据。这种高昂的初期成本,加上先进模型训练所需尖端硬件的出口管制,使得较小国家难以构建自己的人工智能模型。虽然谷歌、Meta和OpenAI等领先的私营公司最初禁止将其模型用于军事目的,但这项限制后来已被解除。这为较小国家授权使用专有模型用于军事应用创造了机会。
第三,复杂人工智能系统日益融入各国军队,使得科技公司在决策高层获得了席位。私营部门在整个人工智能产业链上相较于公共部门具有显著优势。从设计和生产加速深度神经网络训练的关键硬件——图形处理器,到组装和训练前沿人工智能模型,Alphabet、Anthropic、Meta、微软、英伟达和OpenAI等几家大型公司主导着人工智能产业。世界各国政府越来越依赖私营部门的基础设施和专业知识来实现军队现代化。Meta、OpenAI和Palantir公司的高管被任命进入新成立的美国陆军"201支队执行创新团",这表明了私营部门在美国国防和国家安全领域日益增长的地位。因此,国家安全越来越依赖于这些强大科技公司的创新能力、伦理标准和商业决策,这给国家带来了新的制度依赖和治理挑战。
有理由推测,人工智能将在战争中带来一系列切实益处。深度学习的进步有望提高目标锁定精度、增强态势感知并加速决策。它们有可能降低目标误判的发生率,并减少对平民造成意外伤害的可能性。有几个人工智能应用是专门为减轻附带损害而设计的。这些系统利用传感器集群、行为分析和生活模式评估来探测流动的平民,并识别指定视觉符号。此类自动化警告系统可以在检测到风险因素时暂停交战。
然而,人工智能的军事应用仍然充满伦理和法律挑战。围绕自主武器系统和基于人工智能的决策支持系统的法律护栏仍在制定中,并且必须建立在完善的法律伦理框架、政策、公约和传统之上。这留下了监管真空,加剧了违反战争法核心原则(如战斗人员责任、武力相称性原则和非战斗人员豁免权)的风险。此外,过度依赖人工智能辅助决策会招致意外军事交火的风险,从而导致不可预测的冲突升级;这反过来又限制了通过有意义和及时的外交解决螺旋式升级危机的空间。最后,通过分发复杂的开源模型实现的人工智能民主化,使得非国家行为体获得了更强的破坏能力。
鉴于人工智能不可避免地融入军事领域,建立强有力的监管和伦理保障措施对于减轻其负面影响至关重要。本报告将探讨人工智能多样化的军事应用,评估当前的监管格局,审视其中的法律和伦理困境,并提出确保其负责任实施的策略。

提纲
人工智能的军事应用
监管格局
美国法规
碎片化治理
战略风险与监管挑战
关于负责任军事人工智能的建议
I. 优先考虑“合规性内嵌”与伦理工程
II. 制定充分的测试与认证标准
III.确保透明度与可解释性
IV. 强化问责制的法律与政策框架
在经历了超过十年的冲突以及俄罗斯乌克兰战争全面爆发超过1000天之后,与该战争相关的媒体报道和研究常常是事件驱动性的,并且在很大程度上忽视了军事战略层面。交战双方的领土得失、关于提供特定武器系统的长期讨论,以及近来围绕和谈的效用、时机与目标的争议,主导了当前的辩论。然而,这场冲突对欧洲安全架构的中长期军事战略影响,尽管将产生深远后果,却几乎未被公众讨论。在乌克兰,总体战的概念重新出现,战争影响着生活的方方面面。正因如此,加之军事与非军事手段的快速技术进步及其运用的同步性,对俄乌战争进行战术、作战和(最重要的)战略层面的评估势在必行。从对俄罗斯与乌克兰(其在战争初期被认为不可能长期防御)之间的战争分析中,可以得出哪些战略洞见?

本研究基于这样一个假设展开:迄今为止的战争进程表明,有两个战略因素是成功驾驭现代冲突的基本先决条件,并且亟需更深入地审视:即通过“适应性”和“创新”进行变革的能力。然而,这些概念并不新鲜,无论从军事还是科学角度看都是如此。许多研究论文、国防政策,都指出了在现代冲突和战争之前及期间,提高武装力量、经济和社会适应与发展能力的必要性。
这是有充分理由的:自工业革命以来,历史实例表明,技术、经济乃至整体社会能力对军事的适应性和创新力有影响。因此,在过去,一个国家的经济和技术衰退常常伴随着军事停滞。传统上,民用和军用技术的发展遵循相同的范式,并且这两个部门在很长一段时间内相互依存。没有强大的经济与杰出的科学发展相结合,就不可能利用军事创新在冲突中给对手制造战略挑战,或通过创新优势预先可信地威慑对手,也不可能灵活、快速且成功地适应敌方的军事创新。
下文,将以在俄罗斯和乌克兰武装力量中观察到的“创新”与“适应”这两个类别,概略性地阐述这些以战略为主的变革能力。随后,将概述德国目前在创新与适应方面的军事战略变革能力。最后,将基于从俄乌战争中汲取的经验教训,提出改进德国适应与创新能力的措施。在此过程中,聚焦于战争的条令与技术动态,但并非否认战术与作战层面及其相应评估的重要性。目标是为德国能从俄乌战争中获得哪些军事战略洞见的辩论提供推力,并希望总体上鼓励延续对第三方战争的军事战略评估。
俄罗斯的适应与创新之道
俄罗斯在对乌克兰战争中展现的军事战略变革能力,本质上主要是条令性的,仅涉及有限的技术创新。截至目前,技术创新仅限于对已经过实战检验、并经过小幅改装的军事资产和武器系统进行实施和规模化运用。
俄罗斯在2022年2月旨在压垮乌克兰的初始方案,计划是使用高度机动但无法维持长时间作战的空降部队快速占领基辅。同时,动用了被称为“营级战术群”的、基本可自持的战术编队,以击破据称薄弱的乌克兰武装力量抵抗。为使“特别军事行动”成功,俄罗斯在冲突前就努力削弱乌克兰军队,并通过混合与常规手段破坏乌克兰社会的稳定。自占领顿巴斯部分地区和克里米亚以来,甚至更早,俄罗斯就一直试图通过信息宣传、网络攻击、情报活动和破坏行为来削弱乌克兰民众和武装部队的抵抗意志。此外,俄罗斯有步骤地激进化并利用了政治反对派。破坏乌克兰稳定性,最终旨在为俄军部署提供依据。这些做法沿袭了苏联的非线性战争惯例。
行动前夕对指挥控制设施、工业设施、仓库以及雷达和防空阵地的电磁、海上、空中和地面攻击,旨在最大限度地削弱乌克兰武装部队的军事潜力,并确保俄罗斯地面部队以最小损失进攻乌克兰。在全面战争前夕,俄罗斯评估其混合与常规准备措施都已足够成功。然而,由于乌克兰部队在攻击开始前已分散部署,以及俄罗斯武装部队方面对进行恰当的战损评估的忽视,这些准备工作被证明远不如俄罗斯总参谋部预期的有效。正如众所周知,这一战略误判正是俄罗斯初期压垮乌克兰的战略失败的原因。
行动之初,乌克兰既未被震慑而瘫痪,也未出现武装部队瓦解的迹象。因此,乌克兰政府并未投降。训练有素、装备精良的俄罗斯空降部队在对霍斯托梅尔机场的初期突袭成功后不久,便在乌克兰首都基辅以北被摧毁。无论是他们,还是负责增援和解围的营级战术群,大多遭到伏击摧毁或陷入困境,既未配备也未受过进行持久战的训练。
在压垮乌克兰的尝试失败后,俄罗斯的军事和政治领导层在2022年期间成功适应了总体战略局势。俄罗斯的战略转变基于一种假设,即其可调用的军事和经济潜力大于其乌克兰对手,因此能够同时消耗乌克兰军队和平民。在此背景下,军事创新——即在武装部队中发展和运用新技术以实现军事效果——最初只发挥了次要作用。
相反,条令适应性和增加部署经过实战检验的系统,构成了俄罗斯军事战略方法的基石。由于看不到速胜前景,俄罗斯领导层使国家为长期战争做好了准备。2022年12月,一项全面的军事改革——即所谓的“绍伊古改革”获得通过,其设想将俄罗斯武装力量大幅扩充至150万人。仅2023年上半年,在丰厚经济激励措施的推动下,在乌作战的军事人员数量就从36万增至41万,从而免除了进行第二轮部分动员的需要。此前的2009年军事改革——即所谓的“谢尔久科夫改革”——旨在将武装力量的重心转向国际和国内危机处理,缩减规模并提高快速部署能力,但并不适应高强度作战。如今,这些理念大多被摒弃。取而代之的是采纳了一种新的条令,它更少依赖营级战术群的战术灵活性和自持力,而是着眼于在作战层面利用俄军在战斗力方面相对于乌克兰军队的数量和部分质量优势。俄军大部回归了传统的苏联团、师和集团军群结构。
自此以后,尽管付出了己方重大的人员和物资损失代价,俄罗斯的军事行动开始有针对性地打击乌克兰部队集群,通过发挥俄方更高的火力发射速率,在过度延伸的前线以缓慢但稳定的步调作战,来摧毁它们。此外,俄罗斯在冬季月份加强了对乌克兰基础设施的持续攻击。这主要旨在摧毁乌克兰的能源供应,并利用远程空射或海基武器破坏人口稠密城市地区的关键民用设施,以打破乌克兰人的抵抗,并削弱对战争至关重要的工业。
为了维持其中期消耗乌克兰军队及其平民、经济和基础设施的战略方针,俄罗斯在军事和经济层面做出了多项战略调整。在初期压垮战略被证明失败后不久,俄罗斯国防工业便基本转为战时生产,以弥补前线物资损失并装备新动员的部队。除了生产新的主战装备外,俄罗斯武装部队迄今主要依靠使用现有武器库存来弥补其大部分前线损失。其每年生产的约1500辆坦克和3000辆步兵战车中,约80%是经过重新启用和升级的苏联时期系统。此外,来自伊朗和朝鲜的直接武器弹药供应,有助于减轻俄罗斯自身的消耗战略所带来的后果。俄罗斯通过与哈萨克斯坦、亚美尼亚等第三方国家的合作,找到了规避部分西方制裁和禁运的途径,并且与印度和“全球南方”国家的贸易关系得到加强,部分原因是为了弥补西方能源原料市场的损失。俄罗斯成功地采用了最初给其部队造成重大损失的乌克兰有效创新。其中最显著的是大规模使用小型、相对廉价的无人机。事实上,俄罗斯不仅采用了这些技术,还大幅增加了国内产量,并成功地将大规模无人机运用整合到其自身的军事条令中。据俄罗斯消息来源称,到2024年底,俄罗斯生产的无人机数量将比2023年增加十倍。
俄罗斯的电子战能力,在战前可能被高估且在初期相对无效,但很快适应了乌克兰的创新并在数量上得到扩展。这显著降低了交付给乌克兰的西方精确弹药的有效性。此外,这些能力被用于反制无人机,并与保护平台的物理临时解决方案结合使用。后来,俄罗斯为大量可用的常规武器和炸弹加装了快速临时制作的、相对简单的控制装置,以增加其射程和穿透力。因此,俄罗斯作战飞机得以在乌克兰防空系统的射程外活动。总而言之,俄罗斯的方法依赖于条令上的适应以及对现有能力和众多现有系统的技术改进。
乌克兰的适应与创新之道
另一方面,乌克兰武装部队的多功能之处,主要在于技术适应和创新。乌克兰人之所以能在2022年2月全面战争之初进行自卫,是因为在经历了2014年克里米亚被吞并和顿巴斯地区被部分占领的冲击后,他们为保卫国家做好了非常规防御的准备,并动员了社会的各个部分。这包括在人员和物资方面扩编了乌克兰正规军和预备役部队。此外,《国家抵抗基础法》的颁布推动了由现役军人和预备役人员组成的国土防御部队的建立,为潜在的俄罗斯占领下的平民抵抗运动建立了网络,并规定了平民接受军事训练的可能性。
然而,鉴于其数量上的劣势,乌克兰将其主要重点放在了一个其认为相对于俄罗斯具有优势的领域:技术。国防工业的加强和研究机构的资助,催生了与国防部门紧密相连的乌克兰创新中心。认识到相对于俄罗斯在常规力量上的劣势,乌克兰寻求为不对称战争生产、采购和储备武器系统。甚至在全面战争之前,乌克兰就开始不仅储备常规军事资产,还采购和生产军用无人机,并将其整合到部队中。无人机的单独使用并非创新概念,自2020年纳戈尔诺-卡拉巴赫冲突以来,它已成为现代常规战争的一部分。然而,这些系统的广泛和多样化运用,即其即使在最低战术层级得到实施,无疑是一种创新,并成为条令变革的驱动力。在此背景下,应强调的是,鉴于无人机作战带来的技术机遇,乌克兰高级军事人员,特别是乌克兰武装部队前总司令瓦列里·扎卢日内及其继任者亚历山大·瑟尔斯基,已呼吁在乌克兰武装部队中以"作战新设计"的形式进行条令调整。初步成果已开始在战场上显现。与在很大程度上回归苏联时代条令的俄罗斯武装部队不同,乌克兰在条令准备和适应方面的工作是技术驱动的、前所未有的,因而是创新性的。
除了传统的作战和侦察任务,乌克兰军队还使用无人机进行火炮目标识别与校射、战损评估、对被包围或难以到达的部队进行补给,以及利用无人机影像在信息领域达成效果。与人工智能无人机蜂群等颠覆性技术的结合,构成了乌克兰武装部队目前在该领域计划的最后一个创新循环。
除了无人机的创新性使用,还有许多其他例子说明了乌克兰武装部队的新方法。例如,由乌克兰国有的"量子-无线电定位"科研所开发的"矿"-U雷达系统,使得能够侦察黑海水面目标。这连同同样在乌克兰生产的"海王星"反舰导弹,给俄罗斯黑海舰队造成了相当大的损失,并辅以使用无人"自杀式"水面艇的成功作战行动。
经过现代化的"针"-1单兵便携式地空导弹及其在乌克兰部队中的整合,以及在乌克兰生产的"壁垒"-P和"海盗"反坦克导弹,使得能够打击俄罗斯战斗车辆和直升机,特别是在俄罗斯全面心动之初。用于侦察、C2和保障领域的软件,通常由乌克兰武装部队以外的志愿者开发,提高了有限的乌克兰常规手段的效能。最突出的例子之一是Kropyva应用程序,这是一款测绘软件,可整合无人机侦察结果、己方部队位置报告和接触报告。几乎能实时实现指挥控制以及战术和作战层级的火力与机动协调。乌克兰还能够快速将其系统与可商购的天基数据链整合,以确保全面的前线指挥和保障。与此创新精神紧密相关的另一个方面是:乌克兰目前正在摆脱受苏联影响的集中式指挥结构,给予战术军事领导者和保障部队更多的行动自由,甚至整合了(部分)自动化的数字指挥控制信息系统。例如,结合对俄罗斯可能攻击场景的同时开发进行的现代战略和作战兵棋推演,目前用于提高乌克兰总参谋部成员的决策技能。尽管如此,乌克兰的武装力量及其民众仍面临其对手的消耗战,使得俄罗斯得以保持战略主动权。为了摆脱这种不利动态,乌克兰也采取了走向条令适应的措施。然而,西方支持国迄今提供的武器弹药以及国内动员行动的成果,尚不足以使乌克兰消耗俄罗斯部队并将其损失增加到不可接受的水平。乌克兰试图通过以空间为导向、高度机动的突袭性(反)攻来实施其自身的压垮战略,在战术和作战层面确实在2022年秋季的哈尔科夫和赫尔松,以及2024年夏季的库尔斯克取得了一些成功。但并未能大幅给俄罗斯造成战略困境。
此外,乌克兰自下而上的创新方法,缺乏在所有部署的旅中广泛运用以及规模化工作。军事上对使用民用技术或其融入军事结构的限制,仍然是广泛实施创新技术的障碍。因此,在战争初期,经常有个别旅在私人捐助者的支持下独立采购民用技术,特别是无人机。总体而言,乌克兰的技术创新和部分条令创新,甚至在行动前就已启动,并随着战争持续而进一步加强,迄今为止使得该国能够以不对称方式在一些层面上对抗俄罗斯的(相对)规模数量优势。

生成模型是学习高维数据中时空结构的强大工具。然而,现实世界中的许多时空数据集融合了多种模态,并在不同的时空尺度上演化,这对现有生成架构提出了挑战。本论文通过一个三重视角——即解析、预测与沟通高维时空输出——来研究时空生成建模,并以跨越广阔空间、时间和模态范围的地理空间数据作为测试平台。
首先,我提出了TEOChat,这是首个能够通过自然语言指令对地球观测序列进行空间和时间解析的大型多模态助手。我展示了,一个在自然图像和视频上预训练的视觉语言模型可以被重塑为一个强大的通用模型,以胜任时空解析任务。其次,我引入了时空金字塔流,这是一系列用于跨时间尺度高效进行气候预测的流匹配方法。时空金字塔流将生成轨迹分割为一个时空金字塔,其中每个阶段都在特定的时间尺度上运行,同时提高样本的空间分辨率,从而实现在任何时间层级上直接、并行的采样,并支持实时、准确的多尺度气候模拟。最后,我介绍了SAI模拟器,这是一个交互式平台,它能够以易于理解的形式,为研究人员、政策制定者和公众沟通复杂的时空气候输出(例如由生成模拟器产生的输出)。
这些成果共同展示了生成式人工智能如何能够解析、预测与沟通复杂的时空现象,从而实现对多模态、多尺度地理空间数据更有效的建模与交互。



记忆已成为并将继续成为基于基础模型的智能体的核心能力。它支撑着长程推理、持续适应以及与复杂环境的有效交互。随着智能体记忆研究的快速扩张并吸引空前关注,该领域也日益呈现碎片化。当前统称为"智能体记忆"的研究工作,在动机、实现、假设和评估方案上往往存在巨大差异,而定义松散的记忆术语的激增进一步模糊了概念上的清晰度。诸如长/短期记忆之类的传统分类法已被证明不足以捕捉当代智能体记忆系统的多样性和动态性。 本综述旨在提供当前智能体记忆研究最新且全面的图景。我们首先清晰地界定智能体记忆的范围,并将其与大型语言模型记忆、检索增强生成和上下文工程等相关概念区分开来。然后,我们通过形式、功能和动态三个统一的视角来审视智能体记忆。 * 从形式视角,我们识别了智能体记忆的三种主要实现方式,即标记级记忆、参数化记忆和潜在记忆。 * 从功能视角,我们超越了粗略的时间分类,提出了一个更细粒度的分类法,区分了事实性记忆、经验性记忆和工作记忆。 * 从动态视角,我们分析了在智能体与环境交互的过程中,记忆如何随时间被形成、演化和检索。
为支持实证研究和实际开发,我们汇编了一份关于代表性基准测试和开源记忆框架的全面总结。在整合梳理之外,我们阐明了对于新兴研究前沿的前瞻性视角,包括面向自动化的记忆设计、强化学习与记忆系统的深度融合、多模态记忆、多智能体系统的共享记忆以及可信度问题。 我们希望本综述不仅能作为现有工作的参考,更能作为一个概念基础,促使人们将记忆重新思考为设计未来智能体智能时的一等原语。
1 引言
过去两年,我们看到性能日益强大的大语言模型(LLM)已势不可挡地进化为强大的AI智能体(Matarazzo and Torlone, 2025; Minaee et al., 2025; Luo et al., 2025)。这些基于基础模型的智能体在多个领域——如深度研究(Xu and Peng, 2025; Zhang et al., 2025o)、软件工程(Wang et al., 2024i)和科学发现(Wei et al., 2025c)——取得了显著进展,持续推动着通往通用人工智能(AGI)的进程(Fang et al., 2025a; Durante et al., 2024)。尽管早期的"智能体"概念高度异构,但学界已逐渐达成共识:除了纯粹的大语言模型骨干外,一个智能体通常还需具备推理、规划、感知、记忆和使用工具等能力。其中一些能力,如推理和工具使用,已通过强化学习在很大程度上内化于模型参数之中(Wang et al., 2025l; Qu et al., 2025b),而另一些则仍然高度依赖于外部的智能体框架。这些组件共同作用,将大语言模型从静态的条件生成器转变为可学习的策略,使其能够与多样的外部环境交互并随时间自适应地演化(Zhang et al., 2025f)。 在这些智能体的核心能力中,记忆 尤为关键,它明确地促成了从静态大语言模型(其参数无法快速更新)到自适应智能体的转变,使其能够通过环境交互持续适应(Zhang et al., 2025r; Wu et al., 2025g)。从应用角度看,许多领域都要求智能体具备主动的记忆管理能力,而非短暂、易忘的行为:个性化聊天机器人(Chhikara et al., 2025; Li et al., 2025b)、推荐系统(Liu et al., 2025b)、社会模拟(Park et al., 2023; Yang et al., 2025)以及金融调查(Zhang et al., 2024)都依赖于智能体处理、存储和管理历史信息的能力。从发展角度看,AGI研究的一个核心目标是赋予智能体通过环境交互实现持续演化的能力(Hendrycks et al., 2025),而这根本上立足于智能体的记忆能力。 智能体记忆需要新的分类法 鉴于智能体记忆系统日益增长的重要性和学界关注,为当代智能体记忆研究提供一个更新的视角既恰逢其时,也十分必要。提出新分类法和综述的动机有两点:❶ 现有分类法的局限:尽管近期已有几篇综述对智能体记忆提供了宝贵且全面的概述(Zhang et al., 2025r; Wu et al., 2025g),但其分类体系是在一系列方法快速进展之前建立的,未能完全反映当前研究图景的广度和复杂性。例如,2025年出现的新方向,如从过往经验中提炼可复用工具的记忆框架(Qiu et al., 2025a,c; Zhao et al., 2025c),或基于记忆增强的测试时缩放方法(Zhang et al., 2025g; Suzgun et al., 2025),在早期的分类方案中尚未得到充分体现。❷ 概念碎片化:随着记忆相关研究的爆炸式增长,"记忆"这一概念本身正变得日益宽泛和碎片化。研究者们常常发现,标榜研究"智能体记忆"的论文在实现方式、目标和基本假设上差异巨大。各类术语(陈述性、情景性、语义性、参数化记忆等)的扩散进一步模糊了概念的清晰度,这凸显了建立一个能够统一这些新兴概念的、连贯的分类法的迫切需求。 因此,本文旨在建立一个系统性的框架,以调和现有定义、衔接新兴趋势,并阐明智能体系统中记忆的基础原理。具体而言,本综述旨在回答以下关键问题: 关键问题
智能体记忆如何定义?它与大语言模型记忆、检索增强生成(RAG)和上下文工程等相关概念有何关联? 1. 形式:智能体记忆可以采取哪些架构或表示形式? 1. 功能:为何需要智能体记忆?它服务于哪些角色或目的? 1. 动态性:智能体记忆如何随时间操作、适应和演化? 1. 推动智能体记忆研究的前沿方向有哪些?
为解答问题❶,我们首先在第2节为基于大语言的智能体及智能体记忆系统提供形式化定义,并详细比较智能体记忆与大语言模型记忆、检索增强生成(RAG)和上下文工程等相关概念的异同。遵循"形式-功能-动态"三角框架,我们对智能体记忆进行了结构化概述。问题❷探讨记忆的架构形式,我们在第3节讨论并重点介绍了三种主流实现方式:标记级记忆、参数化记忆和潜在记忆。问题❸关注记忆的功能角色,在第4节中,我们区分了三种功能类型:事实性记忆(记录智能体与用户及环境交互中获得的知识)、经验性记忆(通过执行任务逐步增强智能体解决问题的能力)和工作记忆(在单个任务实例中管理工作区信息)。问题❹聚焦于智能体记忆的生命周期与运作动态,我们将按记忆形成、检索和演化的顺序进行阐述。 在通过"形式-功能-动态"视角梳理现有研究后,我们进一步提出了对智能体记忆研究的观点与见解。为促进知识共享与未来发展,我们首先在第6节总结了关键基准测试和框架资源。在此基础上,我们通过第7节探讨数个新兴但尚未充分发展的研究前沿来解答问题❺,这些方向包括面向自动化的记忆设计、强化学习(RL)的融合、多模态记忆、多智能体系统的共享记忆以及可信度问题。 本综述的贡献 总结如下:(1) 我们从一个"形式-功能-动态"的视角,提出了一个最新且多维度的智能体记忆分类法,为理解该领域的当前发展提供了一个结构化的视角。(2) 我们深入探讨了不同记忆形式与功能目的的适用性及相互作用,为如何将各类记忆类型有效地与不同的智能体目标对齐提供了见解。(3) 我们探讨了智能体记忆中新兴且有前景的研究方向,从而勾勒出未来的发展机遇与推进路径。(4) 我们汇编了包括基准测试和开源框架在内的综合资源集,以支持研究人员和从业者进一步探索智能体记忆系统。 综述结构 本综述余下部分结构如下。第2节形式化定义了基于大语言的智能体与智能体记忆系统,并厘清了它们与相关概念的关系。第3、4、5节分别审视了智能体记忆的形式、功能和动态性。第6节总结了代表性的基准测试和框架资源。第7节讨论了新兴的研究前沿和未来方向。最后,我们在第8节总结关键见解,结束本综述。
摘要——多模态大语言模型(Multimodal Large Language Models,MLLMs)通过融合视觉与语言推理能力,能够应对图像描述、视觉问答等复杂任务。尽管 MLLMs 展现出卓越的通用性,但在特定应用场景中的性能仍然受限。针对下游任务对 MLLMs 进行调优主要面临两大关键挑战:任务专家化(Task-Expert Specialization),即预训练数据分布与目标任务数据分布之间的差异限制了目标性能的提升;以及开放世界稳定性(Open-World Stabilization),即灾难性遗忘会导致模型丧失原有的通用知识。本文系统性地综述了近年来 MLLM 下游调优方法的最新进展,并将其归纳为三种范式:(I)选择性调优(Selective Tuning)、(II)加性调优(Additive Tuning)以及(III)重参数化调优(Reparameterization Tuning)。此外,我们在多种主流 MLLM 架构和多样化下游任务上对这些调优策略进行了系统基准评测,以建立标准化的评估分析框架和系统性的调优原则。最后,我们总结了该领域中仍然存在的若干开放挑战,并提出了未来的研究方向。为促进这一快速发展领域的持续进步,我们还提供了一个持续更新的公共资源库,用于跟踪相关研究进展:https://github.com/WenkeHuang/Awesome-MLLM-Tuning。 **关键词——**多模态大语言模型,下游调优,专用能力提升,泛化稳定性
1 引言
大型语言模型(Large Language Models,LLMs)的成功显著重塑了人工智能领域的发展格局,在自然语言理解与生成方面展现出前所未有的能力 [1]–[5]。其卓越的通用性与可扩展性在多个领域树立了新的性能基准,从对话式智能体到复杂问题求解任务均取得了突破性进展。为进一步拓展 LLM 的应用边界,研究者们投入了大量努力,将 LLM 扩展为多模态大语言模型(Multimodal Large Language Models,MLLMs)。这类模型在处理视觉输入并生成连贯且上下文相关的文本描述方面表现出色 [6]–[10]。这种跨模态融合显著拓宽了人工智能的能力边界,使模型具备多模态理解与交互能力。 近年来,MLLM 已迅速从图像描述、视觉问答等基础任务,发展为能够执行复杂推理与创造性生成的高级系统。鉴于 MLLM 通常在大规模、多类型的多模态指令跟随数据集上进行优化 [11]–[15],其在开放世界场景下对相关任务展现出强大的泛化能力。MLLM 的快速发展推动了其在众多实际应用中的落地,包括自动驾驶 [16]、[17]、医疗诊断 [18]、[19] 以及遥感分析 [20] 等。 尽管具备上述优势,MLLM 在某些专业领域或私有数据集上的表现仍然不尽如人意 [21]–[25]。因此,针对下游任务对 MLLM 进行调优(tuning)已成为提升性能的有效途径。在调优阶段,MLLM 能够进一步增强特定任务性能,或使模型行为更好地对齐人类期望 [26]、[27]。然而,尽管调优具有显著潜力,MLLM 在保持良好泛化能力方面仍面临严峻挑战。这主要源于下游数据集往往与预训练阶段所学习到的通用数据分布存在显著差异。模型在适应目标分布的过程中,可能会丧失在预训练阶段获得的通用能力。此外,新知识的学习对已有通用知识产生的负面影响——即灾难性遗忘(catastrophic forgetting)——也是下游适配中一个众所周知的问题 [22]、[23]、[28]–[30]。 为明确本综述的研究动机,我们形式化地总结了 MLLM 下游调优中的两个核心挑战: ♠ 任务专家化(Task-Expert Specialization):当下游数据集呈现出与预训练阶段显著异构的分布特性时,预训练 MLLM 在目标任务上的性能往往受到限制,因此需要通过下游调优使模型演化为特定领域的专家模型。 ♣ 开放世界稳定性(Open-World Stabilization):在针对下游分布进行优化后,MLLM 可能遭受灾难性遗忘,从而丢失在预训练阶段获得的通用知识,最终损害其整体泛化能力。 针对上述挑战,近年来研究者提出并发展了多种先进的调优策略,整体可归纳为以下三大类:(I)选择性调优(Selective Tuning,§3.1),通过选择与下游任务高度相关的参数子集进行更新;(II)加性调优(Additive Tuning,§3.2),在输入空间或模型内部结构中引入额外的可训练模块;(III)重参数化调优(Reparameterization Tuning,§3.3),利用低秩矩阵分解等技术对原始参数权重进行重构。 尽管现有调优方法已被广泛研究,多模态大语言模型领域仍缺乏统一的评估分析框架,用以系统性地衡量不同调优策略在 MLLM 场景下的有效性与独特性。此外,缺乏系统化的调优原则也导致实现流程存在不确定性,进而引发冗余的超参数实验和低效的资源配置。因此,构建全面的评估体系与严格的调优指导原则,对于加速 MLLM 在时间和人力成本受限的真实应用场景(如医学影像分析和遥感任务)中的部署至关重要。本文在图 1 中给出了整体研究概览。
1.1 相关综述工作
随着多模态大语言模型(MLLM)近年来迅速成为研究热点,大量综述性论文相继出现。现有综述大致可分为两类:第一类侧重于 MLLM 的整体发展脉络,强调其在多个应用领域中的潜力,但由于聚焦于概念框架与宏观指导,往往忽视了对具体下游挑战与问题的深入探讨;第二类工作对现有调优方法提供了宽泛的总结,但缺乏系统性的概念框架和针对具体调优技术的深入评估。 尽管少数研究 [31]、[32] 讨论了模型稳定性问题,但其主要关注持续学习(continual learning)范式,即研究神经网络如何在持续学习新知识的同时保持已有知识 [33]–[38],难以直接适配到 MLLM 场景中。MLLM 不仅具有独特的模型结构,还涉及多样化的调优选择,使得传统持续学习方法难以直接迁移。 总体而言,随着该领域的快速发展,**专家化(Specialization)与稳定性(Stabilization)**已成为下游调优多模态大语言模型的两个关键维度:前者确保模型在目标分布上的性能,后者保障模型在广泛通用任务上的适应能力。尽管近年来涌现出大量新工作,现有综述多从碎片化视角出发,缺乏统一分析。相比之下,我们认为这两个方面是相互耦合、共同决定 MLLM 实际部署效果的核心因素。本文是首个同时系统研究下游专家化与上游稳定性,并在多视角实验分析中进行统一基准评测的综述工作。
1.2 论文结构
本文结构如图 1 所示,具体安排如下: §1 介绍多模态大语言模型(MLLM)的发展背景,并概述其在真实场景下调优所面临的两大技术挑战:任务专家化与开放世界稳定性。 §2 系统介绍 MLLM 的建模形式及其调优流程,并进一步指出专家化提升与稳定性遗忘问题。 §3 给出调优方法的分类体系:§3.1 讨论选择性调优方法,通过更新部分已有参数以适应下游分布;§3.2 介绍加性调优方法,通过引入额外参数模块实现领域适配;§3.3 探讨重参数化调优方法,如 LoRA 等模块对参数空间的重构。 §4 进行 MLLM 调优的系统性基准分析,其中 §4.1 描述实验设置、数据集与评估指标,§4.2 比较不同调优方法在多种下游数据集上的表现,§4.3 总结调优原则并分析其内在机理。 §5 讨论开放挑战与潜在研究方向,§5.1 展望未来工作,§5.2 对全文进行总结,强调 MLLM 调优在实际应用中的重要性。
1.3 主要贡献
为弥补现有研究空白,本文对 MLLM 调优过程中专家化与稳定性行为的产生机制进行了系统而及时的综述,主要贡献包括: * 全面综述:深入分析 MLLM 调优过程中专家化与稳定性问题,提供首个系统性、最新进展导向的多模态大语言模型调优综述,涵盖该领域数百篇相关研究。 * 深入分析:选取发表于顶级期刊与会议的代表性调优方法,对现有 MLLM 调优技术进行系统分类,并深入剖析各类方法的优势与局限。 * 系统基准评测:在多种下游场景下对不同调优策略进行全面基准实验,结合专家化与稳定性评估指标,为研究者选择合适基线方法提供实践指导。 * 前瞻性展望:讨论未来潜在研究方向,推动社区重新思考并改进多模态大语言模型在实际应用中的调优设计,促进该领域的持续发展。
俄乌战争已在大多数战场场景中引入了无人机的大规模使用。从班排级使用的侦察无人机、打击敌后数百公里战略目标的神风无人机、能够摧毁现代海军舰艇的海上无人机,到用于引导炮火打击的监视无人机——乌克兰已成为各种技术进步和新战略思想的试验场。尽管许多专家、爱好者和士兵认为无人机是改变游戏规则的武器,但包括乌克兰著名的军事情报总局局长基里洛·布达诺夫在内的其他人,并不相信无人机具有决定性作用。除了探讨无人机能否成为战场上的决定性武器这一问题,本文还讨论了与这类武器相关的局限性,这些局限性取决于部署场景、作战环境、对手的技术水平、生产能力等因素。本文也考量了这样一种假设,即无人机将“仅仅”作为其他武器系统(从反坦克导弹到地对地导弹)的补充,并作为地面部队、侦察组和其他特种单位的通用技术支援工具。本文首先分析无人机在乌克兰使用的起源,然后描述无人机技术的相关发展,并审视无人机使用的现状以及乌克兰无人机生产的政治、经济和实践方面。本文不涉及俄罗斯无人机作战的任何方面。

海上无人作战:海上拒止与完全制海权
乌克兰使用无人武器的其中一个最引人注目的例子,是其针对俄罗斯黑海舰队的海上无人机作战。然而,使用海上无人载具攻击较大海军舰艇的想法并不新鲜,也非乌克兰人所首创。20世纪30年代和40年代,美国就已着手开发能够攻击敌方舰船的空射无人系统。20世纪80年代,泰米尔猛虎组织曾尝试使用海上无人机攻击斯里兰卡海军舰艇。2017年,胡塞武装用一艘海上神风无人机击中了沙特护卫舰“麦地那”号,但未击沉该舰。然而,尽管乌克兰人并未开发出全新的东西,但他们显著改进了这一工具。乌克兰的成功可归因于三个因素:a) 通信系统好得多;b) 无人机的大规模生产;c) 创造性地使用无人机,包括采用狼群战术和与空中无人机的协同攻击。
乌克兰发展海军无人机舰队的道路并非没有挑战。在整个20世纪90年代和21世纪初,乌克兰曾致力于建立一支传统的海军舰艇舰队。这些抱负的显著例子包括:2011年宣布、原定2016年交付但最终未能完工的“弗拉基米尔大帝”号护卫舰;由尼古拉耶夫造船厂设计、在基辅生产至2020年的7艘“斑蝰蛇”级炮艇,它们主要以2018年在刻赤海峡与俄罗斯舰艇的不成功交战而闻名;以及在土耳其造船厂建造的两艘“岛”级护卫舰,本应为乌克兰提供一些额外的火力,但迄今未能取得任何成功。
与乌克兰的雄心有些相悖的是,一支庞大的海军无人机舰队,对于有效将俄罗斯黑海舰队逼退至黑海东部港口(甚至可能至里海)起到了关键作用。2022年初,乌克兰两个相互竞争的情报机构分别启动了海军无人机项目。首先,乌克兰国家安全局开发了一种绰号为“海宝贝”的无人水面艇,这是一种可携带多达800公斤炸药战斗部的遥控快艇。另一个竞争者——乌克兰国防部情报总局,则以他们设计的“马古拉”无人机作为回应,其设计非常相似,能够携带320公斤炸药,航程可达450海里。两种无人机巡航速度可达20节,最高速度为45节。2022年,乌克兰无人机已开始攻击俄罗斯海军舰艇、油轮,以及刻赤大桥和新罗西斯克石油码头等基础设施。2023年,乌克兰加大了攻击强度,甚至击伤了俄罗斯最现代化的信号情报搜集船“伊万·胡尔斯”号和一艘“卡拉库特”级导弹护卫艇。后者于2023年7月才加入俄罗斯黑海舰队服役。
直到2024年初俄罗斯将其能发射“口径”巡航导弹的舰艇撤往里海之前,乌克兰无人机参与了多次有视频记录确认的对俄罗斯舰艇的打击。视频证实了乌克兰无人机所采用成功战术的关键组成部分。成功击沉一艘舰船需要多架无人机进行多次命中。显然,考虑到其相对较低的速度和有限的载药量,无人机撞击造成的破坏无法与高速、大战斗部导弹造成的损害相提并论。而且,与鱼雷不同,无人机是在水线以上而非以下攻击舰船。因此,需要一群无人机进行协同攻击。
成功的无人机攻击还需要高度可靠的快速通信系统,最好是卫星通信。据报道,2022年乌克兰对塞瓦斯托波尔港的首次攻击在埃隆·马斯克意外拒绝乌克兰使用其“星链”通信系统后失败了。数架无人机失去连接并被冲上岸,这给了俄罗斯时间为乌克兰后续攻击做准备。
乌克兰海军无人机取得成功的最后一个原因,与其低成本以及可以利用现成部件生产而不必担心短缺有关。大多数无人机使用的是商用摩托艇的发动机和其他部件。这些无人机使用的引信是苏联时期高爆航空炸弹的标准触发引信。加上每架25万至35万美元的单价,使得无人机生产具有很强的抗打压韧性。由于零部件全球市场有售、生产成本低廉,且该产品的技术水平使其能够在任何具备快艇制造能力的车间组装,因此,无论是通过经济手段还是针对性打击生产设施,都无法停止海军无人机的生产。
对俄罗斯而言,对抗海军无人机唯一有效的方法似乎是让直升机不断在海面巡逻,用机炮摧毁无人机。其小巧的尺寸和低矮的外形使其对雷达隐形,使得反无人机作战几乎变成了一场近战。乌克兰部队通过其反制俄罗斯防御策略的战术,对俄罗斯防空系统构成挑战并危及俄罗斯直升机。据报道,2024年6月,一架正在执行反无人机任务的俄罗斯卡莫夫直升机被己方防空火力误击摧毁。
然而,无人机作战既有优势,也有弱点。尽管是摧毁大型舰艇的廉价有效手段,从而能够阻止敌方海军使用被围水域,但无人机无法完全控制海洋。它们的航程也有限,并且高度依赖于为其提供目标坐标的情报数据。这或许可以解释为何针对俄罗斯海军的攻击大多发生在港口内或港口附近——海军无人机还无法在公海上对舰船进行自由猎杀。期望无人机能在公海常见的风暴和大浪等恶劣条件下运行也还不现实。尽管如此,乌克兰目前正在开发运用海军无人机的新方法。例如,为海军无人机配备防空和对陆多管火箭系统导弹。这可以将海军无人机转变为移动火炮或防空平台,利用海面进行机动,特别是在沿海区域和相对平静的水域。
无人机作战的最新发展证明了海军无人机能力的这种固有局限性。虽然针对陆战无人机的新功能和运用方式不断被开发出来,但海军无人机几乎已从新闻中消失。既然俄罗斯已将其大部分舰队从黑海转移至亚速海,甚至里海,乌克兰无人机便失去了猎杀的目标。这看似矛盾:自从乌克兰将俄罗斯舰队有效逼出黑海后,乌克兰再无海军胜绩,也未发动后续的陆地作战。然而,这有一个非常合乎逻辑的解释:乌克兰海军无人机无法突破部署在刻赤大桥前的俄罗斯防御,那里守卫着进入亚速海的入口,因此无人机无法攻击刻赤大桥以北的俄罗斯舰船。乌克兰也无法在克里米亚或其他地方实施两栖登陆作战,因为它缺乏如巡洋舰、护卫舰和驱逐舰等传统舰艇来压制俄罗斯地面部队并提供防空,当然也缺乏实施登陆行动本身所需的登陆舰。克里米亚的命运将由地面作战决定,而不会涉及海军无人机。
同样是由于缺乏传统舰艇,乌克兰也一直无法通过其他手段扩展其对黑海的控制。仅靠无人机,无法实现这种控制。当然,这并不意味着乌克兰部署海军无人机毫无影响——仅摧毁能够携带“口径”巡航导弹的俄罗斯海军舰艇一项,就拯救了无数乌克兰人的生命。乌克兰敖德萨州和尼古拉耶夫州的海岸也得以免受俄罗斯登陆行动的威胁。但与陆战中使用的无人机相比,海军无人机在可用性方面表现出非常明确的局限:它们仅用于在合理距离内、平静水域且有足够侦察支援的情况下,阻止敌方控制有限的海域。乌克兰海军无人机在黑海的惊人成功,部分可归因于该作战区域的独特性。虽然乌克兰的无人机供应不受限制,但俄罗斯无法简单地从其他舰队调集更多海军舰艇到黑海,因为土耳其控制并限制着通过海峡进入黑海的通道。这使得黑海成为一个非常特殊的战场,其特点是水域封闭、距海岸距离短、缺乏大浪以及其他有利于无人机的因素。


水下无声革命
美海军正通过隐身无人潜航器技术的空前进步,从根本上改变水下作战形态,将自主无人水下航行器定位为21世纪海上安全架构的关键组成部分。随着全球海军竞争在对抗性水域日益加剧,这些复杂的机器人平台正成为改变游戏规则的资产,其能在敌对环境中不被察觉地运行,收集情报、实施侦察,并可能在不危及人员生命的情况下应对敌方威胁。
美海军的技术发展路线图现在将无人系统列为优先事项,将其视为能够扩展作战范围、维持持久监视并在传统载人舰艇面临风险不断升级的对抗领域执行任务的力量倍增器。近期的部署和测试项目表明,隐身无人潜航器不仅仅是对现有能力的渐进式改进,更是海军部队在水下投送力量、维持态势感知和威慑对手方式的范式转变。
战略要务:隐身无人潜航器为何在当下至关重要
当代海上安全挑战需要超越传统海军平台的创新解决方案。传统潜艇虽然强大,但需要大量船员、广泛的后勤支持和巨额资金投入。隐身无人潜航器系统以较低的作战成本提供了互补能力,能够同时在广阔海域展开分布式海上行动。
驱动无人水下航行器发展的战略考量集中在几个趋同的因素上。首先,包括俄罗斯等在内的近邻竞争对手已大幅扩充潜艇舰队和反介入/区域拒止能力,使得美海军在关键区域的行动复杂化。其次,包括通信电缆、能源管道和传感器网络在内的水下基础设施面临日益增加的破坏或监视风险。第三,人工智能、电池系统和自主导航等新兴技术已足够成熟,能够实现持续数周甚至数月的真正独立的水下作业。
根据五角大楼最近的评估,无人水下系统到2045年将构成未来海军平台的约40%,这反映了机构层面对自主能力在大国竞争中提供非对称优势的认识。美海军的水下作战条令日益强调分布式、网络化的力量,而非集中的打击群,无人水下航行器在对抗性战场空间中充当着持久的传感器、通信节点和潜在的武器投送平台。
实现作战可行性的技术突破
近期的技术进步已将隐身无人潜航器的概念从实验原型转变为可部署的作战系统。电池技术的改进,特别是锂离子和燃料电池系统,现在使无人水下航行器能够连续运行更长时间,而无需浮出水面或在任务中途充电。先进的推进系统最大限度地降低了声学特征,使这些平台即使在被声学监视的水域也能不被察觉地运行。
人工智能和机器学习算法或许是自主水下作战最具变革性的赋能因素。现代无人水下航行器采用复杂的决策框架,使其能够在无需人类持续监督的情况下,在复杂水下地形中导航、避开障碍物、识别潜在威胁,并根据环境条件调整任务参数。这些系统集成了传感器融合能力,能够整合声学、磁学和光学数据流,即使在能见度降低的条件下也能构建全面的环境图像。
导航在水下领域仍然是根本性挑战,因为全球卫星导航系统信号无法穿透。当代无人水下航行器通过集成惯性导航系统、地形匹配算法和声学定位网络来解决这一限制。一些先进平台集成了量子传感技术,可探测微小的重力变化以实现无需外部参考的精确导航。通信能力也类似地得到发展,系统现在采用低截获概率声学调制解调器,并在许可环境中运行时偶尔浮出水面进行卫星数据突发传输。
美国海军技术开发界继续大力投资扩展作战包线。当前的研究重点包括使多个无人水下航行器能够自主协作的集群协调算法、利用海洋热梯度的增强型能量收集系统,以及允许快速重新配置以执行从反水雷到反潜作战等不同任务集的模块化有效载荷。
重塑海军能力的作战项目
美海军运行着数个不同的无人水下航行器开发项目,以满足不同规模和能力谱系下的多样化作战需求。以“逆戟鲸”项目为代表的超大型无人水下航行器,是目前正在开发的最大、能力最强的自主水下平台。这些潜艇尺寸的航行器长约51英尺,排水量超过50吨,能够独立运行数月,同时携带包括传感器、水雷或潜在武器系统在内的可观有效载荷。
波音公司是“逆戟鲸”超大型无人水下航行器项目的主承包商,美海军在成功完成原型测试后订购了五套生产型。这些平台利用了最初为“回声航行者”验证机开发的技术,该验证机完成了超过6500英里的长航时自主任务。“逆戟鲸”设计为从岸上设施而非母艇潜艇部署,在保持战略到达能力的同时降低了作战复杂性。其模块化有效载荷舱可容纳多种任务模块,从而能够根据作战需求的演变,快速重新配置以支持情报收集、水雷战、电子战或打击任务。
大型无人水下航行器属于中等能力范围,通常长20-30英尺,重数吨。“蛇头”项目代表了海军在大型无人水下航行器方面的主要工作,旨在开发与潜艇鱼雷发射管兼容的平台。诺斯罗普·格鲁曼公司和洛克希德·马丁公司已获得原型开发合同,系统预计在未来几年内达到初始作战能力。这些航行器为“弗吉尼亚”级潜艇等平台提供了可部署的自主资产,用于前沿侦察、通信中继或有效载荷投送,而无需母船暴露自身于被探测风险之下。
中型和小型无人水下航行器用于满足战术需求,包括反水雷、港口安全和近距离监视。由通用动力任务系统公司开发的“刀鱼”水面反水雷无人水下航行器,采用先进声纳系统探测和分类濒海环境中的掩埋水雷——这项任务传统上需要潜水员或专用舰艇在危险条件下执行。同样,“狮子鱼”小型无人水下航行器为远征部队提供了可由小艇、海滩或前沿作战地点部署的单兵便携式水下侦察能力。
竞争全谱系中的海上安全应用
隐身无人潜航器平台在竞争、危机和冲突的整个谱系中增强了海上安全。在和平时期的竞争中,持久的无人水下航行器监视能够持续监控对手的潜艇基地、航运模式和水下基础设施,而不会产生载人舰艇在敏感区域行动所带来的外交复杂问题。这些系统可以在关键阻塞点附近游弋,跟踪潜艇过航和通信,而无需浮出水面或暴露其存在。
情报、监视与侦察任务是当前一代无人水下航行器的主要应用领域。先进的声学传感器阵列、合成孔径声纳系统和光学成像能力,使这些平台能够测绘海底地形、识别水下设施、监视海上交通并跟踪对手舰船,其分辨率以往需要依赖高风险的载人潜艇行动才能实现。长续航力所实现的持久存在意味着战略区域能得到持续观察,而非受限于潜艇部署周期的间歇性监视。
随着无人水下航行器能力的成熟,反潜战应用正在迅速扩展。自主传感器分布式网络可以在战略区域建立声学屏障,探测和跟踪对手潜艇,同时减轻传统反潜战平台的负担。未来的概念设想无人机蜂群协同搜索和跟踪潜艇接触,采用协同搜索模式和传感器融合,以保持接触,即使面对采用先进声学对抗措施的静音对手潜艇。
水雷战场景尤其清晰地展示了无人水下航行器的作战优势。自主系统可以系统地勘测疑似水域,通过先进的分类算法识别水雷,并或将其标记以备后续清除,或使用集成对抗系统直接消除威胁,从而避免使载人舰艇或潜水员冒险进入可能布设水雷的水域。“刀鱼”及类似平台将反水雷作战从高风险串行行动转变为分布式、持续性的清除行动。
基础设施保护是一个新兴的任务领域,水下无人机海军作战在此提供了独特能力。海底通信电缆承载着约99%的洲际数据流量,使其成为对手破坏或监视的战略目标。同样,海上能源基础设施、港口设施和海军基地也极易成为破坏或侦察的目标。自主无人水下航行器巡逻可以持续监视这些关键资产,检测可疑活动、未经授权的船只或潜在威胁,其效率远高于水面巡逻或定期的载人检查。
地缘政治背景:同级水下竞争
美海军对隐身无人潜航器技术投资的加速,发生在水下领域战略竞争日益加剧的背景下。美军认为潜在对手也在同步发展自身的无人水下航行器能力,尽管公开信息表明美国项目在自主性、续航力和传感器性能方面保持着技术优势。如俄罗斯的发展特别侧重于大型自主系统,包括“波塞冬”核动力鱼雷以及用于北极行动的各种研究平台。
北冰洋正成为水下竞争的新兴领域,因为气候变化减少了冰层覆盖,开辟了新的过境通道和资源获取机会。所有北极国家都在该地区扩展潜艇和无人水下航行器的行动,其中自主系统在季节性冰层下持续运行方面具有特殊优势。美国海军的北极战略明确将无人水下系统视为维持区域态势感知和作战介入的关键赋能因素。
其他海域推动海上安全自主系统的发展。尤其拥挤、声学复杂的浅水环境有利于能够在密集商业交通和复杂海底地形中隐蔽运行的持久性平台。无人水下航行器提供了在争议区域保持态势感知的选择,而不会产生与传统海军存在行动相关的政治复杂性或升级风险。
挑战与局限:为近期期望降温
尽管技术进步显著,但先进的无人水下航行器开发项目仍面临重大挑战,这些挑战限制了其当前的作战能力,并使将其整合到海军力量结构变得复杂。通信限制仍然是根本性的,因为水声信道仅能提供低带宽连接,不适合传输大量数据或实现响应式指挥控制。这一限制要求系统具备高水平的自主性,但如果无人水下航行器遇到需要人类判断的意外情况,也会产生风险。
自主系统的指挥控制框架引发了关于权限、责任和交战规则的复杂问题。虽然当前的无人水下航行器在人类监督下运行并遵循预设的任务参数,但未来的应用(包括武装型)将需要明确的条令指导,规定自主系统何时可以使用武力,以及在何种情况下必须保留人类授权。关于自主武器系统的国际人道法考量,为作战运用决策增加了额外的复杂性。
对手的反无人水下航行器能力正与友方的发展同步演进。潜在的威胁包括被动和主动声学探测系统、自主的猎杀型无人水下航行器、针对自主控制系统的网络攻击,以及在拒止区域对航行器的物理捕获。大多数无人水下航行器相对较低的速度限制了其被探测时的规避选项,而其高昂的单体成本使得损失可能非常重大。全面评估其脆弱性需要在测试期间进行逼真的威胁模拟——这项能力在当前的验证项目中仍然不足。
后勤和维护对持续作战提出了实际挑战。虽然无人水下航行器相比传统潜艇减少了人员需求,但它们仍然需要广泛的后勤支持基础设施用于任务规划、数据利用、维护和物流。电池系统需要定期更换,传感器需要校准和维修,船体完整性检查也必不可少。支持超大型无人水下航行器行动的岸上基础设施意味着重大的资本投入,特别是对于支持分布式海上作战概念的前沿部署地点。
美军将隐身无人潜航器融入海军架构与未来概念
美海军将隐身无人潜航器技术视为分布式海上作战概念不可或缺的组成部分,而非独立能力。近期战略文件中阐述的“分布式海上作战”框架强调在网络化的力量在广阔地理区域行动,以同时给对手制造多重困境,同时降低对集中打击的脆弱性。无人水下航行器在这一分布式架构中充当传感器、通信节点和潜在的武器投送平台。
与有人平台的整合仍然是美海军发展的优先事项。“弗吉尼亚”级潜艇和未来的“哥伦比亚”级弹道导弹潜艇配备了部署和回收大型无人水下航行器的设施,从而扩展了这些舰船的有效传感器范围并减少了其被探测的风险。水面作战舰艇同样正在获得发射和控制无人水下航行器的能力,用于反水雷、反潜战和远征任务。有效的有人-无人协同需要稳健的通信系统、直观的操作员界面以及常规功能的自动化,以避免因额外的协调负担而使舰员不堪重负。
蜂群概念代表了水下作战创新的一个特别有前景的前沿。多个自主载具协同行动,可以完成单个平台无法完成的任务,同时为应对个别载具故障或损失提供冗余。设想中的应用包括:协同搜索模式以快速覆盖大面积区域;多基地声纳配置以提高对静音目标的探测性能;以及饱和攻击以压倒对手的防御。实现这些概念需要在蜂群算法、载具间通信以及能够验证复杂涌现行为的测试方法方面取得进展。
模块化有效载荷和开放式架构使得在技术成熟和作战需求变化时能够快速演进能力。当前的计划强调适应性强的平台,可容纳多种传感器套件、通信系统以及可能的武器,而不是为每项任务开发专用无人水下航行器。这种方法降低了开发成本,加快了能力交付速度,并在战略形势演变时提供了作战灵活性。行业合作伙伴正在开发跨多种航行器级别的标准化接口和有效载荷模块,从而产生加速创新的生态系统效应。
人工智能和机器学习有望在未来几十年显著增强无人水下航行器的能力。当前系统采用相对简单的基于规则的自主性,但新兴的人工智能技术可以实现更复杂的行为。美国海军正在投资“人工智能可靠性”方法,以确保这些系统即使在面对超出其训练经验的新情况时,也能表现出可预测和可靠的行为。
美海军工业基础与国际伙伴关系
美国支持无人水下航行器开发的国防工业基础包括成熟的顶级承包商、专业的技术公司和学术研究机构。波音、通用动力、洛克希德·马丁和诺斯罗普·格鲁曼作为主要采购项目的主承包商,将专业供应商的子系统集成为完整的作战平台。这些主承包商利用其在海洋系统、自主技术和复杂项目管理方面的丰富经验,将需求转化为可部署的能力。
专业公司提供了实现无人水下航行器能力的关键技术。电池制造商开发提供更长续航力的先进能量存储系统。传感器公司提供声学阵列、光学系统和磁探测器。软件公司开发自主算法、任务规划工具和数据利用能力。导航系统供应商提供惯性测量单元、声学定位系统和新兴的量子传感器。这种生态系统方法将创新分布在众多公司之中,同时在主承包商层面保持集成专业知识。
国际组织关系将无人水下航行器的开发扩展到了国家性工作之外。澳大利亚、英国和美国之间的“澳英美三边安全伙伴关系”包括在水下自主系统方面的合作。这些国家正在联合开发技术、分享作战概念并协调需求以确保互操作性。通过北约框架也进行着类似的合作,成员国分享研究成果并协调能力开发,以避免重复工作,同时确保联盟部队能够有效协同作战。
包括日本、韩国和数个欧洲国家推动着其自身先进的无人水下航行器开发计划。日本在自主水下系统方面展现了先进水平,利用了其先进的商业水下技术领域。欧洲国家在特定技术领域,如静音技术、先进材料和新型推进概念方面提供了专业知识。
美海军正在推动培育非传统国防承包商和技术初创公司,它们为水下自主挑战提供了新颖的解决方案。小公司在追求高风险、高回报的技术方面通常展现出更大的灵活性,而这些技术是成熟公司所回避的。近期的采购改革工作使得与非常规公司的合同签订速度更快,加速了创新周期。几家风险投资公司专注于海洋技术投资,创造了支持初创公司度过开发阶段的金融机制,直到它们能够竞争传统的国防合同。
对海战的战略影响
隐身无人潜航器能力的扩散将从根本上改变支配水下战及更广泛海军作战的战略考量。传统潜艇战强调隐蔽、耐心以及对有限探测机会的谨慎管理。在对抗区域持久运行的自主系统,减少了对手潜艇的作战自由度,迫使它们保持更深、移动更慢或接受更高的探测风险——所有这些都限制了其效能。
有利于无人系统的成本交换比带来了特别的战略优势。一艘“弗吉尼亚”级潜艇的成本约为35亿美元,需要135名船员,而一艘“逆戟鲸”超大型无人水下航行器的成本大约在4000万到5000万美元之间,且完全自主运行。这种成本差异使得能够以单个传统平台的成本分布式部署多艘无人水下航行器,从而使对手的目标定位计算复杂化,并为应对损失提供了冗余。即使对手成功压制了个别无人水下航行器,整体任务仍能以最小的作战影响继续。
然而,技术扩散确保了竞争对手最终将部署可比较的能力,这可能导致水下作战环境对各方都相互恶化。如果多个国家在战略水域部署大量自主系统,由此产生的拥塞和相互监视可能会使各方的传统潜艇行动复杂化。这种动态最终可能有利于拥有更庞大潜艇舰队和更广泛岸基基础设施的国家。
向无人系统的转变也可能改变支配海军竞争的政治-军事动态。自主平台的损失与载人舰船的伤亡具有不同的政治后果,可能降低危机期间的升级门槛。相反,在无需承担船员风险的情况下保持持久存在的能力,可能使各国在争议区域采取更强硬的作战姿态,从而增加误判或意外升级的可能性。建立规范无人水下航行器行动的准则和建立信任措施,是战略稳定对话的一个重要议程项目。
未来展望:地平线上的下一代能力
未来,美海军技术路线图设想了能力远超当前平台的日益复杂的自主水下系统。包括紧凑型核动力源、先进燃料电池或诸如海水电池等非常规概念在内的能源突破性技术,可能实现近乎无限的续航力,从而将无人水下航行器从间歇性部署资产转变为永久的海洋哨兵。核动力无人水下航行器将匹敌传统潜艇的续航力,同时保持自主运行优势,尽管其单价会大幅提高并带来额外的安全考量。
包括增材制造在内的先进制造技术,可能实现无人水下航行器部件甚至整船的分布式生产和战地制造。这种能力将改变前沿部署部队的后勤,允许在不依赖漫长供应链的情况下快速更换受损或损失的系统。为增材制造优化的模块化设计可以进一步增强作战灵活性,使载具能够针对特定作战环境或任务要求进行定制。
受海洋生物启发的仿生技术为大幅提高效率和隐身性提供了潜力。模仿鱼类游动动作的推进系统可以将声学特征降低到低于当前机械螺旋桨或喷水推进系统的水平,同时提高能源效率。包含活性声学材料的类皮肤涂层可能实现自适应伪装,动态调整以匹配环境噪声特征。这些受生物启发的方法在很大程度上仍处于实验阶段,但如果成功从实验室过渡到作战系统,将代表潜在的变革性技术。
超越导航传感器的量子技术可能彻底改变水下通信和传感。量子通信系统有望实现安全、抗干扰的连通性,并且可能在经典电磁方法失效的水下环境运行。超越重力导航的量子传感技术可能使得在更远距离上探测潜艇的磁特征、声辐射甚至中微子辐射成为可能,从而从根本上改变当前有利于静音潜艇的探测几何格局。
海上安全自主系统与通用人工智能的融合,最终可能产生能够真正独立进行战略决策的水下平台。虽然当前的自主性仍然是狭隘且基于规则的,但未来的人工智能系统可能展现出可与人类操作员媲美的创造力、判断力和适应性。这些能力将实现当前技术无法完成的任务剖面,同时也引发了关于军事指挥结构、问责制以及自主系统在战争中的适当角色等深刻问题。
结论:为21世纪竞争变革海军力量
隐身无人潜航器技术所代表的远不止是渐进的能力提升——其标志着海军部队在海上领域运作、竞争和投送力量方式的根本性变革。随着各国海军在各类尺寸和能力谱系上加速无人水下航行器开发项目,这些自主平台正成为未来舰队架构中不可或缺的组成部分,它们扩展作战半径、维持持久存在,并完成先前不可能或风险过高的任务。
人工智能、先进传感器、改进的能源系统和复杂的自主算法的融合,已达到一个临界点,使得真正具有作战能力的水下机器人而不仅仅是实验原型成为可能。诸如美海军“逆戟鲸”、“蛇头”和“刀鱼”等项目,展现了美军机构致力于将这些技术从概念转化为可部署能力的动机。随着测试的推进和早期作战经验的积累,条令框架、训练项目和支持基础设施也日趋成熟,以将无人系统与传统平台整合。
驱动这一变革的战略必要性超越了技术可能性,延伸至作战需求。当代安全挑战包括近邻对手的潜艇扩散、水下基础设施的脆弱性以及对抗性区域的进入,这些都需要自主系统独特提供的能力。在无需承担船员风险的情况下,维持持久监视、实施分布式作战并在拒止区域行动的能力,弥补了当前海军能力的关键缺口,同时在大国竞争中提供了非对称优势。
然而,要实现自主水下作战的全部潜力,需要持续的投资、针对复杂威胁的逼真测试,以及在多个技术前沿的持续创新。必须同时发展平台本身、将其整合到舰队作战中、建立有效的指挥控制框架,并与伙伴合作以最大化协同能力。这项事业的成功将在未来几十年大幅提升海上安全,而失败则可能将在水下领域的优势拱手让给正积极发展其自身自主系统的战略竞争对手。
正在水下发生的这场静默革命,其最终影响可能不亚于以往从风帆到蒸汽、从水面到水下、从常规动力到核动力的海军转型。随着隐身无人潜航器的扩散和成熟,它们将从根本上重塑海战的特性,改变战略平衡、作战概念以及海上力量的根本性质。率先掌握这些技术的国家,将在定义21世纪海战的水下领域竞争中享有显著优势。
参考来源:thedefensewatch

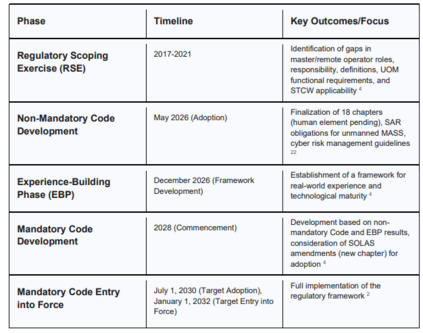
海事领域自主系统的兴起,正从根本上改变着远程操作中心的作用。远程操作中心是集中式设施,能够对远程海上船舶进行实时监视、管理与控制。本文在海上自主水面船舶的背景下,对远程操作中心的多方面问题进行了全面审视,探讨了从现有法律框架、人为因素到技术基础设施和人员培训等一系列主题。考虑到国际海事组织关于在2032年前强制实施《海上自主水面船舶规则》的路线图,本研究从运行、人员、技术和法律等多个维度,分析了远程操作中心的现状与未来要求。它探讨了用于降低人为失误和错误决策的风险管理策略、相比传统方法在培训和职业规划方面的现代化改进,以及远程操作人员的心理健康。最终,本研究提出了战略性建议,以确保远程操作中心在未来的海事运行中能够安全、高效且可持续地运作。
原创作者:宋晨旭 王世泽 肖良望 孙楚芮
指导老师:张伟男
原创指导:刘元兴 转载须标注出处:哈工大SCIR
1. 物理AI介绍
1.1 背景
随着人工智能技术的火热发展,最新的GPT-5.1和Gemini 3等模型展示出了强大的自然语言对话和推理能力,也可以胜任数学、编程等领域的任务。视觉-语言-动作模型(VLA)则进一步利用了多模态大模型的能力,来控制机器人执行动作。 然而,当下普通的大模型仍然缺乏对现实世界的高层次感知与理解能力,VLA驱动的机器人可以完成简单的指令,但面对复杂的环境与任务时却显得乏力。举例来说,人类通过对于运动、惯性等物理知识的掌握,可以轻松预测一个运动中物体的行进轨迹;凭借对于空间的感知能力,人类可以轻松判断物体之间的距离远近、遮挡关系、方位朝向。类似的问题对于人类来说十分简单,但对于当下的人工智能模型来说却非常困难 [1]。我们期望机器人有朝一日可以像各种科幻题材的影视文学作品中那样,轻松完成从日常家务到专业生产的一系列任务,这种程度的人工智能也被称之为“通用人工智能”(Artificial General Intelligence)[2]。但是,人工智能目前的表现水平还远远不够。这一局限性的本质原因在于目前主流的大模型缺乏对于现实世界底层物理规则的理解,不能准确预测自身行为的物理后果,也就无法做到基于与其自身与现实世界的互动来持续调整策略。为此,人工智能领域的学者们提出了“物理人工智能(AI)”这一概念。
1.2 物理AI定义
物理AI的定义可以总结为具备物理形体、掌握物理知识的人工智能。 物理AI****给予人工智能物理形体,让其能与现实世界直接交互。传统的人工智能指通过计算机程序来模拟人类智能,但普遍只存在于虚拟的数字空间中,无法与现实世界产生直接交互,可以被称之为“数字AI” [3] [4]。而物理AI则在传统数字AI的基础上,让人工智能通过物理形体获得与现实世界交互的能力,并具有行为驱动的学习能力,可以从互动中总结经验、学习知识。 另一方面,与同样拥有物理形体的“具身智能”相比,物理AI更加侧重对于现实世界物理规律的掌握,要求AI做到可以凭借对物理规律的理解来指导决策过程,在执行任务时充分考虑现实条件以及事物的因果规律。物理AI需要掌握对时间、空间的理解,以及动力学、热力学、电磁学等基础物理学知识,以此在现实任务场景中达到人类水平的推理与决策能力。 Salehi [3] 进一步解释了物理AI应具备的能力:物理AI是传统数字AI的进一步发展,不仅能够在数字空间中处理信息,也能主动地与现实物理世界进行交互,通过传感器来感知现实环境,并能够动态预测环境未来状态,根据掌握的知识自主决策行动。目的是可以做到自主适应,持续学习,在执行任务时充分考虑环境的不确定性、信息的不完全性,以及事物的物理规律。物理AI,是实现通用人工智能(AGI)路上的一步。 物理AI是一种高层面的人工智能设计与研发理念,注重“行动-反馈-学习-改变”的循环。物理AI也代表着对智能的一种新的思考方式:智能是无法从数据计算和功能的堆叠中产生出来的,而是从行动中涌现出来,行动应该被看作学习与思考的一种方式。对于物理AI来说,思考不仅仅是对知识的抽象理解、对数据的处理和计算,而是发掘动作与规律之间对应关系的过程。人工智能需要做到从行动和经验中学习,理解自身行为的内在意义,才能实现真正的自主性。
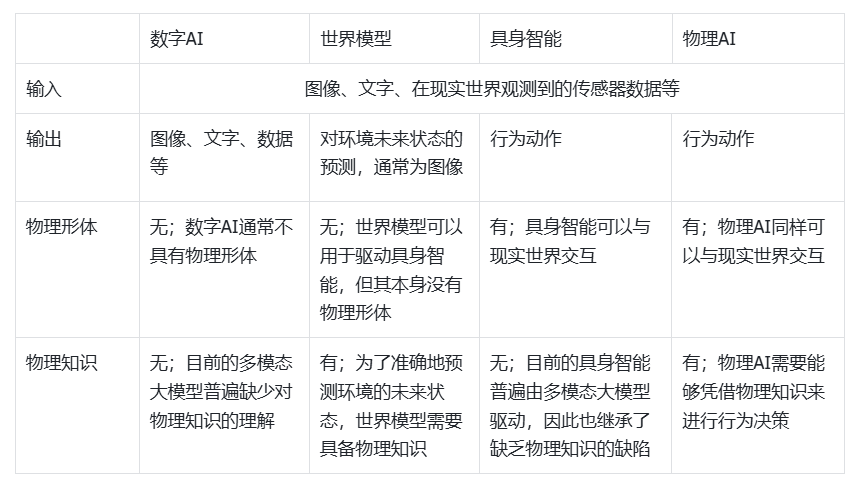
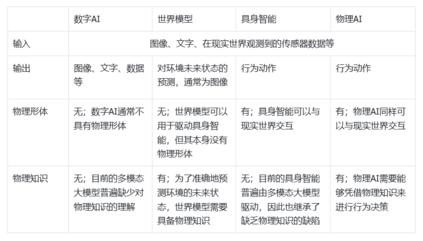
表1:物理AI与相关概念的比较(数字AI,世界模型,具身智能)。 物理AI定义中所包含的“行为驱动的学习能力”这一思想可以追溯至上个世纪90年代人工智能学界的观点,当时的部分学者认为思考离不开物理形体 [3]。Aslan Miriyev和Mirko Kovac两位学者在2020年Skills for Physical Artifical Intelligence一文中正式提出了物理AI的概念,将物理AI作为传统数字AI的对应,号召科研人员在人工智能及机器人的设计过程中充分考虑AI的物理形体,给予AI在现实世界的互动能力 [4]。英伟达公司CEO黄仁勋在2025年1月举办的美国消费类电子产品展览会(CES)上发表演讲时,重点提到物理AI,并认为物理AI将引领人工智能领域的新一波浪潮、将其称之为人工智能的新前沿。
图1:英伟达总裁黄仁勋在CES 2025的演讲中,预测物理AI会是人工智能领域的新前沿。图片来自网络。
2. 物理AI的代表性工作
2.1 Cosmos系列模型
英伟达公司在CES 2025期间公布了他们在物理AI领域的成果:Cosmos系列模型。其中,Cosmos-Predict1,也被称之为“世界基础模型”World Foundation Model,可以准确地预测系统的未来状态,生成符合物理规律的高质量视频 [5];Cosmos-Transfer1则允许用户控制视频生成的过程,针对不同的任务需要,调整生成视频中的物体材质、形状、结构,或者生成深度图等特殊形式的视频,满足无人驾驶、机器人控制等不同领域对于视频数据的不同需求 [6]。这两个模型生成的视频可以为物理AI的训练提供大量高质量、符合物理规律的训练数据,助力物理AI的研发。除此之外,Cosmos-Reason1模型作为特化的推理模型,采用了传统Transformer的自注意力与Mamba的混合架构,使得模型的上下文窗口更长、计算过程更高效;在经过大量的微调和强化学习训练后,拥有了相比于一般多模态大模型更强大的物理推理能力 [7]。
图2:英伟达Cosmos-Reason1推理模型 [7],采用了Transformer和Mamba的混合架构,在接受视频和文字输入后,可以针对现实场景问题输出带有思维链的推理过程与答案。
2.2 Gemini Robotics系列模型
谷歌DeepMind团队Gemini机器人搭载的Gemini Robotics系列模型也是物理AI领域的代表性工作之一 [8]。VLM模型GR-ER-1.5在谷歌Gemini模型的基础上针对具身推理进行了优化,可以将复杂的任务分解为一系列步骤,并在分步骤执行的过程中不断优化策略;GR-ER-1.5也拥有优秀的物理知识掌握能力,可以进行空间、时间推理,并理解一系列基础物理规律、因果关系,能准确判断物体的可供性(affordance)。而VLA模型GR-1.5则进一步将具身推理能力应用到机器人控制上,让机器人在执行动作前先针对任务目标进行思考,将任务分解后再逐步执行;这种分步骤行动的方法要优于一次性计划所有动作。除此之外,GR-1.5在训练中使用了名为Motion Transfer的新颖方法,使得GR-1.5可以学习多种具身形态机器人的数据,并可以将自身的能力以zero-shot的方式迁移至不同形态的具身机器人上,极大地提高了GR-1.5模型的泛用性。
图3:谷歌Gemini Robotics 1.5系列模型 [8],包括GR-1.5 VLA模型和GR-ER-1.5 VLM模型。二者搭配后可以高效地控制不同形体的机器人完成复杂的现实场景任务。
2.3 当前人工智能面临的挑战
物理AI这一领域目前仍处于起步阶段。为了尽可能地提升人工智能的学习与推理能力,让其达到或超过人类水准,需要先了解目前人工智能模型在数据、架构、训练方法等方面的缺陷,并加以解决。经过近些年来的研究积累,科学界对于目前人工智能的不足之处有了更深入的了解,这些缺陷可以归结为以下三个主要问题:**训练数据缺乏物理属性,对物理空间感知能力不足,以及缺乏物理知识。**如何解决这三个问题也成为了目前物理AI领域的三个主流研究方向:符合物理规律的数据生成,旨在解决数据拓展问题;增强物理空间感知能力,弥补传统AI在视觉感知上的缺陷;提升物理推理能力,让AI能够更好地基于物理知识进行行为决策,以应对复杂的现实场景任务。本文将分别介绍每个研究方向的背景与发展现状。
3. 符合物理规律的数据生成
3.1 问题背景:训练数据缺乏物理属性
多模态大模型的能力很大程度上取决于训练数据的质量。目前常用的训练数据集普遍取材于互联网上的文字、图像、视频,但这些数据中对空间结构、物理规律等方面的描述不足够、不准确,导致训练出来的模型无法掌握这些知识。以Kamath et.al. [31] 的工作为例,该文章发现LAION数据集中图片对应的文字描述经常包含模糊不清或错误的空间信息。然而,如果从头搭建数据集,则需要过滤海量的互联网数据、挑选合格的样本,或者需要在现实环境中收集真实数据,这两种做法都面临效率低、成本高的问题。仿真环境模拟出来的数据也很难准确地还原现实中的物理现象,存在sim-to-real鸿沟,不能直接迁移到机器人训练上。因此,想要实现物理AI,就要先解决训练数据缺乏物理属性的问题。
图4:Kamath et.al. [31] 对LAION数据集进行分析,发现很多图片的文字描述中包含模糊不清或者错误的空间介词,如above,below,behind等,部分图片并非与物体的空间关系有关。
3.2 研究内容
生成式AI的内容生成能力有潜力解决数据拓展问题。生成式AI可以低成本、高效率地生产图像、视频,甚至3D模型等各种形式内容,并以此作为人工智能模型的训练数据。但这一方法的前提是提升AI生成内容中物理现象的准确性。符合物理规律的数据生成旨在提升AI在生成内容的过程中对于物理现象的描述的准确性,生成各种场景下的高拟真度内容,为物理AI的训练提供高质量数据。目前,提升生成模型的物理准确性的工作主要可以分为以下两方面:(1)提升训练数据对物理现象的描述:已有的训练数据中缺乏对物理现象的具体性、准确性描述,导致模型的训练效果差,缺乏对物理现象的识别能力,因此一部分工作选择从头搭建高质量数据集,或者研发高效的数据生成、标注管道;(2)如何将物理规律融入生成过程中:物理现象可以用语言描述或者用数学公式表示,但将物理规律融入到模型的生成过程中并不容易,生成式模型需要具备将物理规律作为限制来控制生成过程,或者学会精确预测系统与环境在物理影响下的变化。
3.2.1 提升训练数据对物理现象的描述
生成式模型训练数据的主要形式是2D图像与文字描述组成的数据对,但常见的训练数据集中,2D图像通常并不会明显地展示某一物理现象的完整过程,文字描述也倾向于陈述图像的直观内容而往往省略具体的物理现象或者空间关系等信息 [9]。这使得基于这些数据训练得到的生成式模型缺乏对物理规律的理解,当用户提供文字指令或参考图片时,模型也不能准确预测出要生成的事物该如何依照物理规律进行变化发展。 为此,一部分工作从头搭建了高质量数据集,或者设计新颖的流程来改进已有的数据集。WISA [9] 从头构造了一个新的数据集WISA-80K,该数据集包含80000条视频,覆盖了力学、热力学以及光学3个核心物理领域内17个基础物理现象。WISA-80K的每一个样本简洁、直接地展示了具体的物理现象,避免数据对模型的训练产生干扰。另一方面,SpatialCLIP [10] 注意到数据集中图像配对的描述信息缺乏对于空间关系的解释,于是设计了一套利用MLLM重新为数据集编写图像描述的流程,并通过随机修改空间关系介词来生成负样本,让VLM可以在训练中学会分辨不同的空间关系。此外,PhysX: Physical-Grounded 3D Asset Generation [11] 这篇工作提出现有的3D数据的局限于几何结构和外观纹理,于是从头构造了一个拥有绝对尺度、材料属性、可供性、运动学以及功能描述5个方面的标注的数据集,并设计了一个可扩展的人工辅助的标注流水线,为目前的3D数据集进行物理标注。PhysX文章中提出的PhysXGen模型,在实现图片生成3D资产的同时,也能够为生成的3D资产标注其可能具有的物理属性。
图5:WISA [9] 工作中提出的WISA-32K数据集,包含3个类别17种不同物理现象的视频样本。
3.2.2 将物理规律融入生成过程
物理规律可以通过视觉图像、文字描述、数学公式等方法表示出来,但对于生成式AI来说,最关键的问题在于如何将这些对于物理规律的表示与模型的生成过程有效地结合起来。生成模型往往不能很好地理解视觉与文字中蕴含的物理规律,无法本能地在生成过程中识别到不符合物理规律的细节并进行干预;数学公式可以被引入到损失函数中,但现实世界的物理现象十分复杂,还经常涉及到多种物理规律之间的相互影响,让生成模型同时考虑大量的物理规律并不现实。为了让模型学会理解物理规律,并在生成内容的过程中将这些知识加以运营,科研界正在尝试各种训练方法与模型架构。 一部分工作从用户输入的提示(prompt)出发,加强物理信息对模型生成过程的约束。例如Hao et.al. [12] 的工作中提出,可以先让模型进行“反事实”推理,生成不符合物理规律的负提示(physics-aware negatives),再利用无分类器引导的方法,利用负提示来控制扩散模型在生成视频时远离那些会违反物理规律的特征。这种方法无需重新训练模型,可以直接应用在基座模型上。实验证明,在针对生成内容物理准确度的测试基准VideoPhy和PhyGenBench上,这种“负提示”控制的生成方式可以有效提高CogVideoX和Wan2.1等基座模型的表现。同时,WorldGPT [13] 中作者提出可以基于用户的输入图片,首先生成视频首部和尾部的关键帧,通过对prompt进行增强来引导视频生成模型在关键帧之间扩散出其他帧,保证生成视频中物体的空间一致性和动作一致性。
图6:Hao et.al. [12] 通过反事实推理生成负提示,让正提示与负提示相结合,共同引导模型生成符合物理规律的视频。 另外,以VideoREPA为代表的工作将物理规律融入进模型的损失函数中,让模型在学习优化损失函数的过程中学会物理规律 [14]。VideoREPA引入了Token Relation Distillation (TRD) 损失函数,该损失函数通过对空间和时间特征的关系进行对齐,将VFM中的物理理解能力蒸馏到T2V模型中,从而提高了生成视频的物理合理性。VideoREPA不依赖专门的物理数据集,具有更强的通用性,能够有效生成符合物理规律的视频。 与此同时,Ji et.al. 的PhysMaster [15] 和 Lin et.al. 的Phys-AR [16] 工作则利用强化学习的方式来训练生成模型最大程度上符合物理规律。PhysMaster提出了一个名为 PhysEncoder 的模块,专门用于从输入图像中提取物理信息,比如物体的相对位置、材质以及潜在的物理交互等;PhysEncoder将这些信息作为物理表示输入到生成模型中,从而利用增强prompt的方式来提升视频生成的物理一致性。在此基础上,为了优化物理表示并有效引导生成模型的训练,PhysMaster 采用了强化学习与人类反馈(RLHF)的策略,使用直接偏好优化(DPO) 框架来进一步提高生成视频的物理合理性。通过这种方法,模型能够根据人类反馈优化生成的视频,最大化物理一致性。Phys-AR也使用了监督微调(SFT)和强化学习相结合的方式,通过奖励函数优化模型的物理推理能力,确保生成的视频遵循物理法则。
4. 增强物理空间感知能力
4.1 问题背景:对物理空间的感知能力不足
物理AI要求人工智能做到与现实世界进行交互,这也就要求大模型需要具备更高水平的物理空间感知能力,能够理解并掌握物体与环境的三维空间关系。然而,目前的大模型普遍使用的编码器以CLIP为代表,但这些编码器在训练中主要依赖于2D图像,导致它们只能识别2D空间的信息而缺乏对于现实3D世界的理解。Tong et.al.的工作中即对CLIP模型视觉能力的缺陷进行了深入分析,发现基于CLIP编码器的多模态大模型在识别空间关系、物体细节上有很大不足 [32]。2D形式的输入难以准确提现3D世界的空间信息,但深度图、点云、3D建模等3D数据则可以帮助人工智能获得对现实环境更深入的理解。然而,深度图等数据虽然包含3D信息,但对模型的编码能力有很高要求,同时这些3D数据也普遍需要特定的感应设备来获取,如光学雷达等。因此,物理AI需要进一步提升人工智能模型的物理空间感知能力。
图7:SpatialBot [17] 一文中通过实验发现,以GPT-4o为代表的大模型单纯2D RGB图像输入,难以准确判断物体的空间关系,但通过深度图则可以针对问题做出正确回答。
4.2 研究内容
为了克服类CLIP编码器的局限性以及大模型无法掌握3D信息等问题,物理AI需要提升模型的物理空间感知能力,在2D图像与文字等常见的输入模态之外增加对深度图、点云、3D建模等数据格式的编码与学习能力,充分利用这些能够更准确体现现实世界3D特征的输入模式。另一方面,很多学者也在探索人工智能模型该如何更高效地从2D图像输入中感知3D信息,避免模型过度依赖于光学雷达等特化的感知设备。感知能力的提升将极大程度上促进物理AI对于现实世界的理解能力。增强物理空间感知能力的相关工作按照数据类型和对数据的处理方法可以分为两种:(1)3D模态输入,让模型在2D RGB图像以外也能够理解深度图、点云、3D模型等形式的数据;(2)从2D输入提取3D信息,通过架构上的改进或者数据处理方式,将3D信息从2D输入中还原出来。
4.2.1 3D模态输入
目前多数的大模型都使用类似CLIP架构的编码器来处理输入数据,将图像编码为token后与语言进行对齐。这些CLIP架构编码器普遍由2D图像和文字描述组成的数据对训练而来;然而,由于维度的压缩,2D图像普遍无法反应现实3D世界中的空间关系和动态变化的物理现象,这导致CLIP架构编码器缺乏对于空间关系和物理规律的理解。为了能让大模型更好地理解现实世界中复杂的空间、时间以及物理规律,一个自然而然的解决方法就是让模型接收3D格式的输入数据,例如深度图、点云,或者3D建模等。这些3D数据相比2D图像可以更好地还原现实世界,帮助大模型从输入中获得更多信息。 以SpatialBot [17] 模型为代表的工作,在普通的2D RGB图像之外也可以接收深度图作为额外输入,以此增强模型对于空间的理解能力。SpatialBot也考虑到室内场景和室外场景中物体深度信息的尺度不统一,例如室内场景中物体的深度普遍较小、但任务对于距离判断需要很高的精度,而室外环境下物体深度的数量级要远远大于室内物体,因此使用了ZoeDepth模型,使用单目深度估测算法来准确预测不同场景下2D RGB图像的深度信息,达到更优的效果。除了直接接受深度图输入外,SpatialBot也可以通过调用API的方式自主地获取RGB输入图像中目标物体的深度信息。
图8:SpatialBot架构图 [17]。SpatialBot可以在2D RGB图像以外接受深度图作为额外输入,或者通过调用API来估测物体的深度信息,以此辅助模型进行更准确的空间推理。 使用点云的大模型则以PointLLM为代表。PointLLM-v2 [18] 在模型中使用了点云编码器,能够将点云输入编码为特征,再经过MLP将这些3D特征映射到文字token的空间中,让语言模型基于文字与3D信息的混合token来生成回答。
图9:PointLLM-v2架构图 [18]。PointLLM-v2利用点云编码器来处理点云格式的输入,提取3D特征并融合至基座语言模型的token空间中,让语言模型基于文字与3D信息的混合token来生成回答。
4.2.2 从2D输入提取3D信息
虽然3D数据可以帮助大模型更好地从输入中获得更多3D信息,但在现实中,并不一定每一个任务场景都有3D数据可以作为输入。另外,通常只有在具有光学雷达等专业传感器的前提下,模型才能从环境中直接观察到深度图、点云等3D数据,这种硬件需求也限制了模型的应用性。出于这些原因,业界也在探索如何直接利用2D图像来获得更多3D信息。这类工作按实现方法可以大致分为两类:(1)架构上改进已有的大模型,使用空间编码器等方式从2D输入中提取3D特征;(2)数据上对2D输入进行处理,通过prompting或者构建3D坐标系等方式来增强模型对于3D关系的感知。
**4.2.2.1 架构改进
为了尽可能地从2D输入中提取3D信息,大模型可以在架构上进行改进,使用针对3D感知能力进行特化的编码器,来增强模型的感知能力。随着计算机视觉领域的技术发展,目前已有很多方法可以直接通过多张2D图像来精确地还原3D场景,比如最新的VGGT模型可以凭借2D图像输入直接推断出场景中的多种关键3D信息,比如相机的位姿、深度图、3D点跟踪等,这使得VGGT有潜力成为非常高效的空间编码器 [19]。 Spatial-MLLM [20] 使用VGGT模型作为额外的空间编码器,从2D视频输入中提取3D特征,再经由连接层与普通2D编码器得到的2D特征融合在一起。基于Qwen2.5VL-3B搭建的Spatial-MLLM凭借对3D信息更深入的理解,在针对视觉空间智能的VQA基准测试VSI-Bench上表现优秀,超过了Qwen2.5-VL-72B和LLaVA-Video-72B等开源大模型以及GPT-4o和Gemini-1.5-Pro等闭源大模型。Evo-0 [21] 则更进一步,将VGGT融入了VLA模型,可以在RLBench的仿真环境中高成功率地完成叠叠乐积木、拿雨伞、挂晾衣架等任务,表现优于和OpenVLA-OFT;在现实世界中也可以出色完成对普通物体以及透明材质物体的拾取、放置。
图10:SpatialMLLM架构 [20]。该模型包括2D编码器与空间编码器(基于VGGT模型)的双编码器架构,可以有效地从2D输入中提取3D信息,辅助模型对于空间任务的推理。 Chen et.al. [22] 的工作则从注意力机制视角系统分析了 VLM 空间推理失败的原因,通过实验发现模型在进行视觉推理时,注意力往往落在与问题无关的区域,且模型中间层的视觉注意力与答案正确性高度相关;基于实验结果,作者认为,真正关键的是注意力在图像上的几何分布是否与目标物体对齐。为此,作者选择改进模型的注意力解码阶段的过程,提出了ADAPTVIS方法:根据当前生成答案的置信度,对注意力进行缩放——置信度高时强化现有关注区域;置信度低时促使模型重新探索其他空间关系。在不改动视觉编码器和语言模型参数的前提下,该方法通过解码阶段的注意力调控显著缓解 VLM 的空间推理缺陷。
**4.2.2.2 数据处理
除了使用空间编码器等方法来改进模型架构上,模型也可以直接对输入进行处理,来辅助模型对于3D信息的感知,例如直接采用3D重建算法从2D图像输入中还原物体的三维坐标、位置等,帮助模型建立内在的三维坐标系;也可以在图像中为物体标注包围盒(bounding box),或在prompt中注入物体的包围盒信息,引导模型基于这些信息来进行空间推理。 以SpatialReasoner为代表的工作利用2D图像输入来还原3D场景信息,辅助模型在统一的3D坐标系下进行空间视觉推理。SpatialReasoner [23] 作为VLM,旨在提升模型对于3D VQA任务的几何感知能力,从单张2D图像预测物体的三维位置,将图像中的关键物体的坐标统一在三维坐标系下,并将其作为贯穿 “3D感知—几何计算—空间推理”的统一结构化接口,摆脱仅依赖自然语言进行隐式空间推断的局限。GPT4Scene [24] 针对VLM 在VQA任务中缺乏全局布局与跨帧对应的问题,提出了一种新的视觉提示范式,通过对纯2D视频输入进行结构化预处理来显式补充缺失的三维信息。其核心思路是先从视频输入中进行3D重建,生成Bird’s Eye View(BEV)俯视图,提供整体场景布局;再为所有帧与BEV引入一致的时空物体标记(STO-markers),构建局部观察与全局空间结构之间的对应关系。在无需修改模型架构的前提下,该范式为VLM提供可对齐的 3D 结构信号,使其具备跨帧一致的物体跟踪与场景定位能力,从而显著提升3D QA和视觉指代等任务表现。
图11:SpatialReasoner模型与其它模型在空间视觉推理任务上的对比 [23]。通过构建统一的三维坐标系,SpatialReasoner在推理过程中可以准确地判断出物体之间的空间关系,得到正确答案。 在VLA领域,Being-H0 [25] 通过恢复输入视频的三维一致性来增强模型的行动理解与机器人可迁移性。其利用MANO参数和弱透视投影,将来自不同视角、不同相机参数、不同分辨率视频的手部动作统一到共享的三维参考系,从而消除尺度、坐标系与成像几何的差异,为模型提供一致的3D空间语义。完成对齐后,Being-H0在此空间中学习手部运动的时间结构并执行视觉–语言–动作的统一建模。通过这一机制,Being-H0显式恢复输入视频的三维一致性,使其能够在后续阶段完成动作建模与机器人迁移。 另一方面,以Muturi et.al. [26] 为代表的工作则从prompt出发,通过在prompt中注入任务目标物体的包围盒,来辅助模型进行空间推理,提升推理结果的准确性。SpatialVLM [27] 也训练模型从2D输入中预估物体包围盒信息,并辅以思维链推理的方式,来让模型进行更深入的空间推理。
5. 提升物理推理能力
5.1 问题背景:缺乏物理知识
物理AI需要掌握现实世界中的物理规律,然而现实场景普遍十分复杂,多种物理现象经常交织在一起,涉及不同的原理。推理思维链CoT或者微调等方式虽然可以提升模型的通用推理能力,但却很难提升模型对于物理规律的理解和应用。此外,目前的VLA模型缺乏主动学习、持续学习的能力,无法做到从行动中总结规律、提取经验,并以此主动调整行为模式;在目前的信息不足以完成任务时,大模型普遍做不到主动地去调整策略、获得更多信息,或者回看输入、深入观察细节。为此,物理AI需要探索人工智能思考与推理的新范式,提升人工智能的物理推理能力。
5.2 研究内容
为了解决普通的大模型对于物理知识的缺乏,物理AI需要针对性地训练模型在推理与决策过程中考虑物理知识,训练模型掌握事物的因果关系,在决策和行动过程中将自身、周边物体与环境的物理特性当做决策因素与限制条件,这样才能进一步提升机器人在现实世界中的活动能力与任务成功率。物理AI还需要提升人工智能模型的主动适应与持续学习能力,不再依赖于提前设定好的行动规则,而是在通过与现实世界进行的交互中直接学习规律、总结经验,并能够主动地收集更多信息、智能识别到输入中与任务相关的细节,这样才能最大程度上提升物理AI的泛用性、通用性、自主性。然而,让人工智能学会这些能力并非容易之举,目前的大模型在提升物理推理能力方面主要面临以下三个方面的挑战:
5.2.1 探索更有效的推理增强技术
当前物理推理、空间关系建模与时间顺序理解等子领域普遍依赖通用的大语言模型推理范式。研究者倾向于采用微调、思维链、反思、提示工程等“性能增强型”捷径策略。例如英伟达的Cosmos-Reason1模型通过微调和强化学习的方式,一定程度上提升了模型对于汽车行驶、判断视频时间顺序等方面的推理能力 [7] 。然而,这些方法虽然有可能在特定任务上提升基准性能,却往往无法从根本上消除逻辑不一致或违反领域常识等问题,且缺失了对于领域下资源的广泛利用。这种“以通用能力覆盖专业需求”的路径虽在短期内见效快,但长期来看,制约了真正具备领域专家级推理能力的人工智能系统的发展。举例来说,PhysBench [28] 这篇工作通过实验证明,思维链方法并未能有效地提升大模型的物理理解能力,用语言来详细描述视觉信息中的物理图像并不能让模型更好地理解、遵循物理规律。关于空间智能的实验也证明,思维链方法同样不能提升大模型对于空间关系的理解 [1]。这些实验结果意味着模型需要更复杂的机制来真正做到“理解”视觉输入,而不能只是依靠简单的语言描述。为了能够最大化未来人工智能模型对于物理规律的理解能力,实现通用自主的物理AI,我们需要不断探索新的、更加有效的推理范式。Yang et al.在实验中发现思维链对于提升空间推理能力的局限性后,发现大模型可以通过构建认知地图(cognitive map)来显式地表示模型对于场景布局和空间关系的理解,并以此辅助推理过程 [1]。另一方面,以CoT-VLA [33] 为代表的工作开始探索“视觉思维链”(Visual CoT)这一新颖的推理增强方法,将视觉图像作为推理的中间步。相比于以往的VLA模型直接生成动作指令,CoT-VLA在思考过程中先生成图像,将任务分解为一系列中间状态,循序渐进地生成动作指令来逼近这些中间状态的任务目标,最后完成完整的任务。视觉思维链让人工智能能够像人类一样,直接用图像融入思考过程,弥补了传统的只依赖于文本信息的思维链方法无法捕捉现实环境视觉细节的缺点。 图12:CoT-VLA [33] 与普通VLA模型的对比:CoT-VLA没有直接生成动作指令,而是先生成预测图像作为中间状态,以此指引模型将任务分解为一系列步骤,逐步完成任务。
5.2.2 考察物理推理能力的测试基准
当前主流的考察人工智能推理能力的benchmark及其配套的基线模型往往流域表面,过多地聚焦于单选题形式的最终答案正确率,而忽视对推理过程本身的评估。这种“只看结果、不问过程”的评价方式,既无法判断模型是否通过合理的逻辑链条得出结论,也难以识别其是否依赖数据偏差或表面相关性进行猜测。更关键的是,它无法反映模型在面对复杂、多步、需整合多种约束条件的推理场景时的真实能力。因此,现有评测体系难以有效引导模型向可解释、鲁棒、符合人类认知逻辑的方向演进,科研界需要针对模型的物理推理能力,提出更加有针对性、考核更全面的测试基准,在问题设计上考察模型对于物理知识的全方面理解与运用,在评判标准上不仅要考虑答案准确性,更要观察模型的推理过程是否合理,避免模型通过统计学相关性“猜”到答案而非真正理解问题。Shen et.al. [29] 的工作认为,目前虽然已有很多物理知识相关的测试基准,如PHYBench,UG-Physics,OlympiadBench等,但这些基准的评测使用的是用文字描述的物理问题,缺乏对模型视觉理解能力的考察;为此,他们提出了PhyX测试基准,包含3000道基于视觉输入的物理推理问题,覆盖力学、电磁学、热力学、光学、声学、现代物理六个领域。PhyX相比PHYBench等以往的物理知识测试基准,更加注重模型对于视觉输入的理解能力,需要模型理解图画、函数图像等信息才能准确作答。这样的测试基准有助于科学界更加深入地研究人工智能的物理知识水平。Dong et.al. [30] 也同样注意到了目前常见的基准测试忽视了模型对于视觉输入的理解与运用能力,并提出在测试基准中应该增强对于模型推理过程的考察,确保模型不仅能够给出正确的最终答案,还能提供基于视觉线索的连贯、逐步推理路径。他们提出的MVPBench包含物理实验、物理问题、空间关系、动态预测四个门类,并在评判标准中加入了对于模型CoT推理过程的考察,包括CoT的发散性(生成不同推理路径的能力)以及CoT的效率(避免过于冗长的推理过程,让模型的推理更加简洁高效)。通过对CoT过程的深入评判,MVPBench发现过长的CoT确实会干扰模型的推理能力,让模型生成过多重复性、与任务不相关的思考内容。
5.2.3 增强跨模态推理能力
现有推理范式高度依赖文本模态,对视觉等其他感知模态的支持明显不足。一方面,多数模型在处理包含图像的任务时,仅将视觉信息作为辅助输入,未能将其深度融入推理过程;另一方面,训练数据中缺乏高质量的、图文对齐的多模态推理样本,导致模型难以从图像中提取结构化语义,进而限制了其在真实世界场景中的综合推理能力。这种模态割裂不仅削弱了模型对物理世界的整体理解,也阻碍了具身智能和多模态认知系统的发展,因此,人工智能需要提升跨模态推理能力,弥补过往模型的不足之处。首先,在视觉模态上,Chen et.al. [22] 在对大模型内在注意力的分布进行实验调查后发现,代表视觉图像输入的token占到所有token序列的90%,但最终只得到约10%的模型注意力。这意味着大模型在推理过程中,并没有真正地理解图像输入,也未能有效地利用图像信息中的全部细节,而是主要依靠文本描述在进行推理。实验同时也发现,直接提升视觉输入token的注意力权重也并不能增强模型的表现;相反,如果能把模型的注意力更好地集中在图像输入中与目标任务相关的细节上,模型在推理任务上的准确性则会有效提升。这证明对于模型来说,提升推理能力需要模型能够做到深入理解图像输入、捕捉与任务有关的视觉细节。为了解决这一问题,Chen et.al.在工作中提出了ADAPTVIS方法:根据当前生成答案的置信度,对注意力进行缩放——置信度高时强化现有关注区域;置信度低时促使模型重新探索其他空间关系。在不改动视觉编码器和语言模型参数的前提下,该方法通过解码阶段的注意力调控显著缓解 VLM 模型的空间推理缺陷。 图13:ADAPTVIS方法 [22] 可以根据模型对于当前生成答案的置信度,来对模型的注意力进行缩放,让模型在置信程度高时专注于细节,而在置信程度低时重新探索其它区域。这种方法有效提高了模型的推理准确性。其次,Kamath et.al. [31] 的实验证明类似CLIP架构的模型普遍缺乏对于空间关系的理解,不能将视觉图像中物体之间的空间关系与文字中类似“上,下,前,后”等方位介词对应起来。这一根本性缺陷的源头仍然是在CLIP架构的训练数据与训练方法上,主流的数据集中,图像的文字描述很少提供关于空间关系的准确描述,“上,下,前,后”等方位介词的使用混淆不清;而且空间关系的表示方法在不同数据中也并不一致,有些文字对空间关系的描述对应的是观众视角,而有些却对应的是图像中物体的视角;另外,早期数据集中训练任务的设计也并没有针对性检验模型的空间理解能力。该实验也再一次验证了目前的模型缺乏对于语言和视觉信息的跨模态整合能力,不能将文字、图像对应起来,以致于缺乏对于空间关系等关键知识的掌握与应用能力。因此,Kamath et al.在工作中号召未来的研究工作将目光放在如何进一步整合模型的图像与视觉感知能力,以便更好地实现跨模态理解与推理能力。
6. 总结
人工智能领域近几年来取得了突飞猛进的发展。基于多模态大模型的广泛运用,可以猜测未来更先进的人工智能模型一定会通用性更强、泛用性更广,并且在对知识和经验的总结、学习、应用能力上达到并超过人类水准。物理AI是目前科研界对于更先进的人工智能模型的期望之一,是人类对于实现AGI的一次尝试。本文总结了物理AI这一新兴研究领域的发展现状,将物理AI视为一种新颖的人工智能设计理念,其关键在于构建“行动-反馈-学习-改变”的循环,以行动的方式驱动模型的持续学习、自主适应。物理AI的发展目前面临着三大重要问题,即训练数据缺乏物理属性、对物理空间的感知能力不足、缺乏物理知识;针对这些问题,科研界正积极探索符合物理规律的数据生成、增强物理空间感知能力、提升物理推理能力三个研究方向,并已经取得了一定进展。可以相信,在不远的将来,学习能力更强、推理水平更高、行动更加智能的物理AI会成为现实。
7. 参考文献
[1] Yang, Jihan, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. 2025. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 10632-10643. [2] Goertzel, Ben. 2014. Artificial general intelligence: Concept, state of the art, and future prospects. Journal of Artificial General Intelligence 5.1. [3] Salehi, Vahid. 2025. Fundamentals of Physical AI. Journal of Intelligent System of Systems Lifecycle Management 2. [4] Miriyev, Aslan, and Mirko Kovač. 2020. Skills for physical artificial intelligence. Nature Machine Intelligence 2.11: 658-660. [5] Nvidia. 2025. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575. [6] Nvidia. 2025. Cosmos-transfer1: Conditional world generation with adaptive multimodal control. arXiv preprint arXiv:2503.14492. [7] Nvidia. 2025. Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning. arXiv preprint arXiv preprint arXiv:2503.15558. [8] Gemini Robotics Team. 2025. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer. arXiv preprint arXiv:2510.03342. [9] Wang, Jing, Ao Ma, Ke Cao, Jun Zheng, Zhanjie Zhang, Jiasong Feng, Shanyuan Liu et al. 2025. Wisa: World simulator assistant for physics-aware text-to-video generation. arXiv preprint arXiv:2503.08153. [10] Wang, Zehan, Sashuai Zhou, Shaoxuan He, Haifeng Huang, Lihe Yang, Ziang Zhang, Xize Cheng et al. 2025. SpatialCLIP: Learning 3D-aware Image Representations from Spatially Discriminative Language. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 29656-29666. [11] Cao, Ziang, Zhaoxi Chen, Liang Pan, and Ziwei Liu. 2025. Physx-3d: Physical-grounded 3d asset generation. arXiv preprint arXiv:2507.12465. [12] Hao, Yutong, Chen Chen, Ajmal Saeed Mian, Chang Xu, and Daochang Liu. 2025. Enhancing physical plausibility in video generation by reasoning the implausibility. arXiv preprint arXiv:2509.24702. [13] Yang, Deshun, Luhui Hu, Yu Tian, Zihao Li, Chris Kelly, Bang Yang, Cindy Yang, and Yuexian Zou. 2024. WorldGPT: a Sora-Inspired Video AI Agent as Rich World Models from Text and Image Inputs. arXiv preprint arXiv:2403.07944. [14] Zhang, Xiangdong, Jiaqi Liao, Shaofeng Zhang, et al. 2025. VideoREPA: Learning Physics for Video Generation through Relational Alignment with Foundation Models. arXiv preprint arXiv:2505.23656. [15] Ji, Sihui, Xi Chen, Xin Tao, Pengfei Wan, and Hengshuang Zhao. 2025. PhysMaster: Mastering Physical Representation for Video Generation via Reinforcement Learning. arXiv preprint arXiv:2510.13809. [16] Lin, Wang, Liyu Jia, Wentao Hu, et al. 2025. Reasoning Physical Video Generation with Diffusion Timestep Tokens via Reinforcement Learning. arXiv preprint arXiv:2504.15932. [17] Cai, Wenxiao, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. 2025. Spatialbot: Precise spatial understanding with vision language models." In 2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 9490-9498. IEEE. [18] Xu, Runsen, Shuai Yang, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. 2025. Pointllm-v2: Empowering large language models to better understand point clouds. IEEE Transactions on Pattern Analysis and Machine Intelligence. [19] Wang, Jianyuan, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. 2025. Vggt: Visual geometry grounded transformer. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 5294-5306. [20] Wu, Diankun, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. 2025. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. arXiv preprint arXiv:2505.23747. [21] Lin, Tao, Gen Li, Yilei Zhong, Yanwen Zou, Yuxin Du, Jiting Liu, Encheng Gu, and Bo Zhao. 2025. Evo-0: Vision-language-action model with implicit spatial understanding. arXiv preprint arXiv:2507.00416. [22] Chen, Shiqi, Tongyao Zhu, Ruochen Zhou, Jinghan Zhang, Siyang Gao, Juan Carlos Niebles, Mor Geva, Junxian He, Jiajun Wu, and Manling Li. 2025. Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas. arXiv preprint arXiv:2503.01773. [23] Ma, Wufei, Yu-Cheng Chou, Qihao Liu, Xingrui Wang, Celso de Melo, Jianwen Xie, and Alan Yuille. 2025. Spatialreasoner: Towards explicit and generalizable 3d spatial reasoning. arXiv preprint arXiv:2504.20024. [24] Qi, Zhangyang, Zhixiong Zhang, Ye Fang, Jiaqi Wang, and Hengshuang Zhao. 2025. Gpt4scene: Understand 3d scenes from videos with vision-language models. arXiv preprint arXiv:2501.01428. [25] Luo, Hao, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, and Zongqing Lu. 2025. Being-h0: vision-language-action pretraining from large-scale human videos. arXiv preprint arXiv:2507.15597. [26] Muturi, Tanner W., Blessing Agyei Kyem, Joshua Kofi Asamoah, Neema Jakisa Owor, Richard Dzinyela, Andrews Danyo, Yaw Adu-Gyamfi, and Armstrong Aboah. 2025 Prompt-guided spatial understanding with rgb-d transformers for fine-grained object relation reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5280-5288. [27] Chen, Boyuan, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14455-14465. [28] Chow, Wei, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Campagnolo Guizilini, and Yue Wang. 2025. PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding. In ICLR 2025 Workshop on Foundation Models in the Wild. [29] Shen, Hui, Taiqiang Wu, Qi Han, Yunta Hsieh, Jizhou Wang, Yuyue Zhang, Yuxin Cheng et al. 2025. PhyX: Does Your Model Have the" Wits" for Physical Reasoning?. arXiv preprint arXiv:2505.15929. [30] Dong, Zhuobai, Junchao Yi, Ziyuan Zheng, Haochen Han, Xiangxi Zheng, Alex Jinpeng Wang, Fangming Liu, and Linjie Li. 2025. Seeing is Not Reasoning: MVPBench for Graph-based Evaluation of Multi-path Visual Physical CoT. arXiv preprint arXiv:2505.24182. [31] Kamath, Amita, Jack Hessel, and Kai-Wei Chang. 2023. What’s "up" with vision-language models? Investigating their struggle with spatial reasoning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 9161-9175. [32] Tong, Shengbang, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes wide shut? exploring the visual shortcomings of multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9568-9578. [33] Zhao, Qingqing, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li et al. 2025. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 1702-1713.