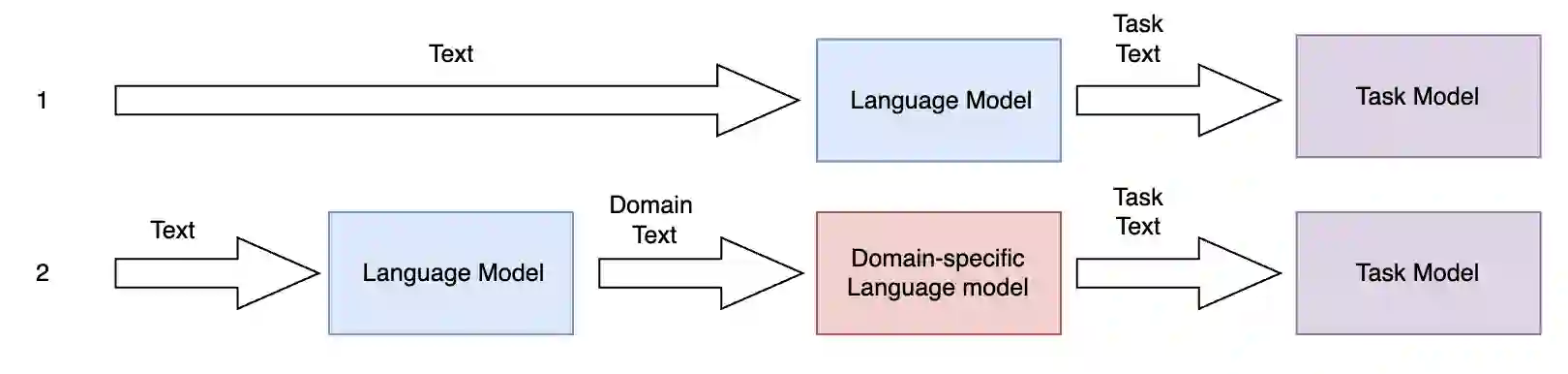
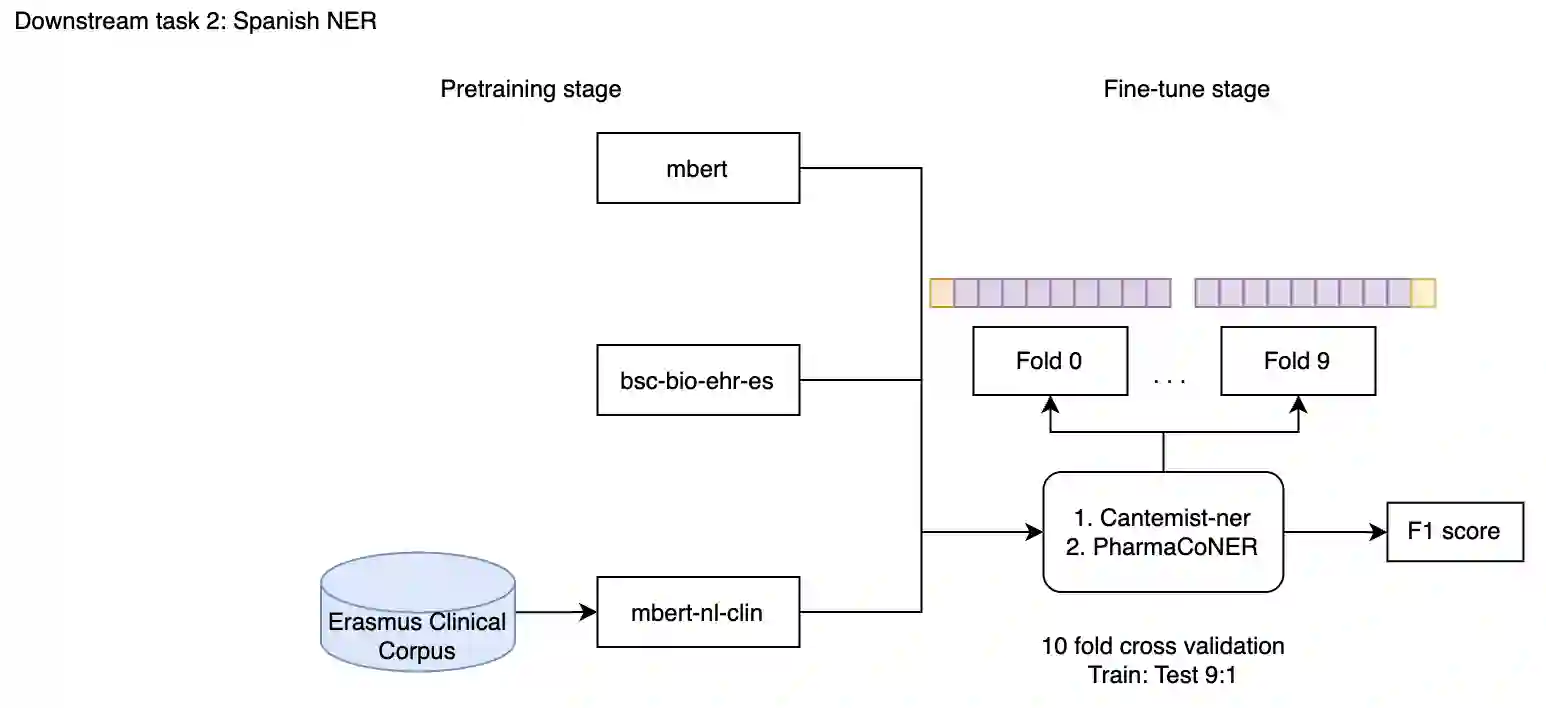
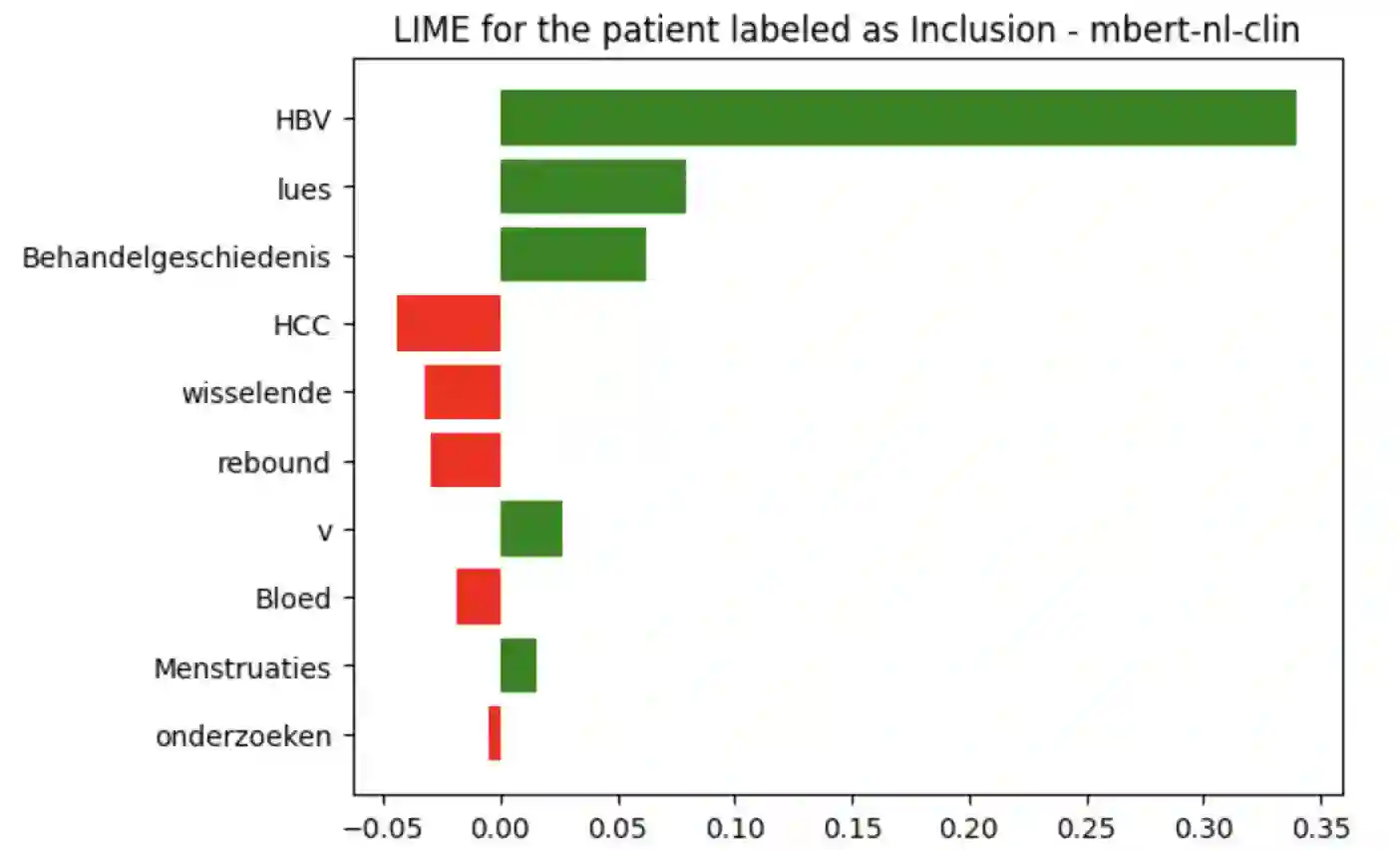
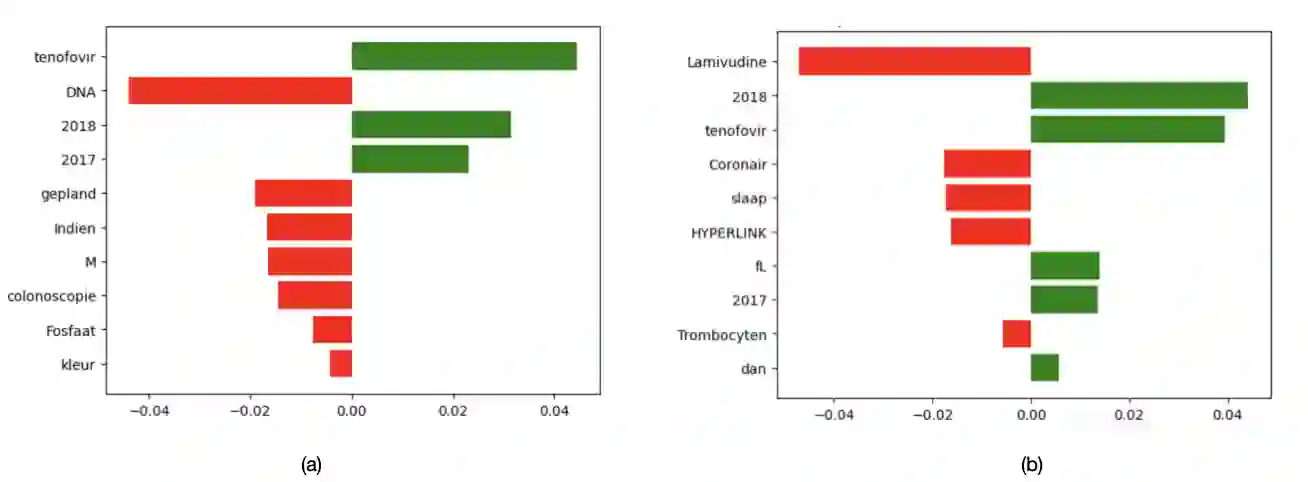
In multilingual healthcare applications, the availability of domain-specific natural language processing(NLP) tools is limited, especially for low-resource languages. Although multilingual bidirectional encoder representations from transformers (BERT) offers a promising motivation to mitigate the language gap, the medical NLP tasks in low-resource languages are still underexplored. Therefore, this study investigates how further pre-training on domain-specific corpora affects model performance on medical tasks, focusing on three languages: Dutch, Romanian and Spanish. In terms of further pre-training, we conducted four experiments to create medical domain models. Then, these models were fine-tuned on three downstream tasks: Automated patient screening in Dutch clinical notes, named entity recognition in Romanian and Spanish clinical notes. Results show that domain adaptation significantly enhanced task performance. Furthermore, further differentiation of domains, e.g. clinical and general biomedical domains, resulted in diverse performances. The clinical domain-adapted model outperformed the more general biomedical domain-adapted model. Moreover, we observed evidence of cross-lingual transferability. Moreover, we also conducted further investigations to explore potential reasons contributing to these performance differences. These findings highlight the feasibility of domain adaptation and cross-lingual ability in medical NLP. Within the low-resource language settings, these findings can provide meaningful guidance for developing multilingual medical NLP systems to mitigate the lack of training data and thereby improve the model performance.
翻译:在多语言医疗应用中,领域特定的自然语言处理(NLP)工具较为有限,尤其对于资源稀缺语言而言。尽管多语言双向编码器表示(BERT)为缓解语言差异提供了有前景的动机,但资源稀缺语言中的医疗NLP任务仍未被充分探索。因此,本研究探讨了在领域特定语料库上进行进一步预训练如何影响模型在医疗任务上的性能,重点关注荷兰语、罗马尼亚语和西班牙语三种语言。在进一步预训练方面,我们进行了四项实验以构建医疗领域模型。随后,这些模型在三个下游任务上进行了微调:荷兰语临床记录中的自动化患者筛查、罗马尼亚语和西班牙语临床记录中的命名实体识别。结果表明,领域适应显著提升了任务性能。此外,对领域(如临床领域与通用生物医学领域)的进一步细分导致了不同的性能表现。临床领域适应模型的表现优于更通用的生物医学领域适应模型。同时,我们观察到了跨语言可迁移性的证据。此外,我们还进行了进一步研究以探索导致这些性能差异的潜在原因。这些发现凸显了领域适应与跨语言能力在医疗NLP中的可行性。在资源稀缺语言环境下,这些发现可为开发多语言医疗NLP系统提供有意义的指导,以缓解训练数据不足的问题,从而提升模型性能。