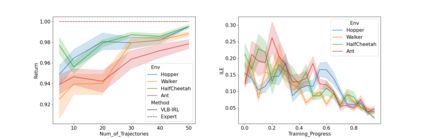
Inverse reinforcement learning (IRL) seeks to learn the reward function from expert trajectories, to understand the task for imitation or collaboration thereby removing the need for manual reward engineering. However, IRL in the context of large, high-dimensional problems with unknown dynamics has been particularly challenging. In this paper, we present a new Variational Lower Bound for IRL (VLB-IRL), which is derived under the framework of a probabilistic graphical model with an optimality node. Our method simultaneously learns the reward function and policy under the learned reward function by maximizing the lower bound, which is equivalent to minimizing the reverse Kullback-Leibler divergence between an approximated distribution of optimality given the reward function and the true distribution of optimality given trajectories. This leads to a new IRL method that learns a valid reward function such that the policy under the learned reward achieves expert-level performance on several known domains. Importantly, the method outperforms the existing state-of-the-art IRL algorithms on these domains by demonstrating better reward from the learned policy.
翻译:暂无翻译