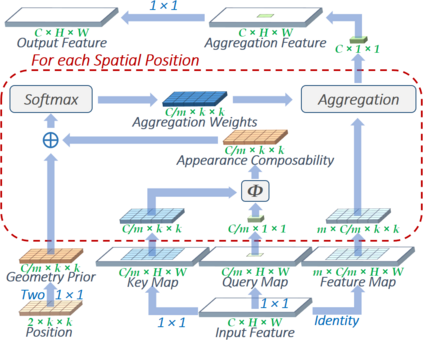
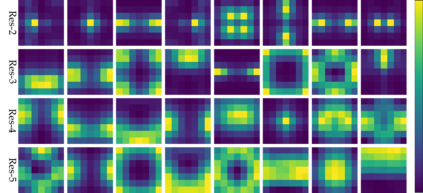
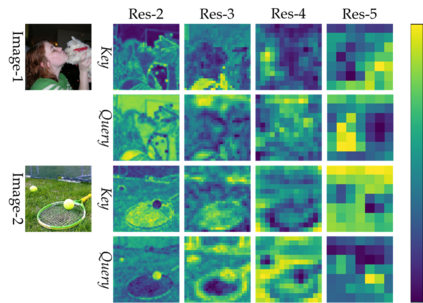
The convolution layer has been the dominant feature extractor in computer vision for years. However, the spatial aggregation in convolution is basically a pattern matching process that applies fixed filters which are inefficient at modeling visual elements with varying spatial distributions. This paper presents a new image feature extractor, called the local relation layer, that adaptively determines aggregation weights based on the compositional relationship of local pixel pairs. With this relational approach, it can composite visual elements into higher-level entities in a more efficient manner that benefits semantic inference. A network built with local relation layers, called the Local Relation Network (LR-Net), is found to provide greater modeling capacity than its counterpart built with regular convolution on large-scale recognition tasks such as ImageNet classification.
翻译:变迁层多年来一直是计算机视觉中的主要特征提取器,然而,变迁中的空间聚合基本上是一个模式匹配过程,它应用固定过滤器,在模拟空间分布不同的视觉元素时效率低。本文展示了一个新的图像特征提取器,称为本地关系层,根据本地像素配对的构成关系,适应性地决定聚合权重。通过这种关联方法,它可以将视觉要素以更高效的方式结合到高层实体中,从而有利于语义推断。一个以本地关系层建立的网络,称为本地关系网络(LR-Net),其模型能力大于在图像网络分类等大规模识别任务上与常规革命建立的对应网络。