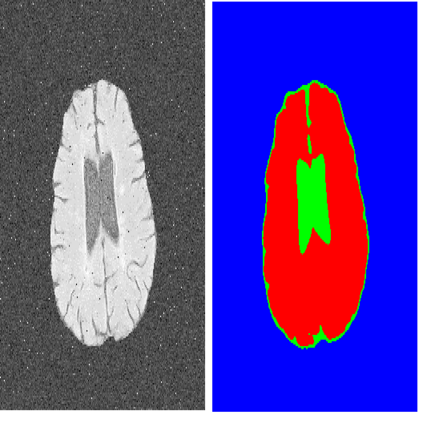
The hybrid architecture of convolution neural networks (CNN) and Transformer has been the most popular method for medical image segmentation. However, the existing networks based on the hybrid architecture suffer from two problems. First, although the CNN branch can capture image local features by using convolution operation, the vanilla convolution is unable to achieve adaptive extraction of image features. Second, although the Transformer branch can model the global information of images, the conventional self-attention only focuses on the spatial self-attention of images and ignores the channel and cross-dimensional self-attention leading to low segmentation accuracy for medical images with complex backgrounds. To solve these problems, we propose vision Transformer embrace convolutional neural networks for medical image segmentation (TEC-Net). Our network has two advantages. First, dynamic deformable convolution (DDConv) is designed in the CNN branch, which not only overcomes the difficulty of adaptive feature extraction using fixed-size convolution kernels, but also solves the defect that different inputs share the same convolution kernel parameters, effectively improving the feature expression ability of CNN branch. Second, in the Transformer branch, a (shifted)-window adaptive complementary attention module ((S)W-ACAM) and compact convolutional projection are designed to enable the network to fully learn the cross-dimensional long-range dependency of medical images with few parameters and calculations. Experimental results show that the proposed TEC-Net provides better medical image segmentation results than SOTA methods including CNN and Transformer networks. In addition, our TEC-Net requires fewer parameters and computational costs and does not rely on pre-training. The code is publicly available at https://github.com/SR0920/TEC-Net.
翻译:暂无翻译