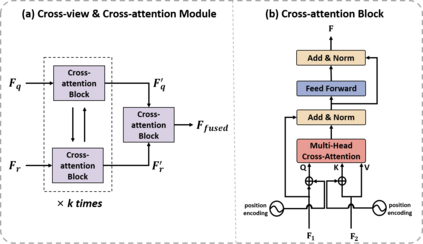
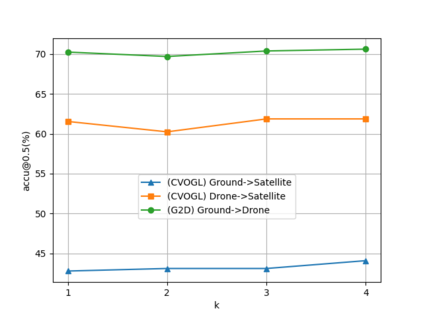
Cross-view object geo-localization has recently gained attention due to potential applications. Existing methods aim to capture spatial dependencies of query objects between different views through attention mechanisms to obtain spatial relationship feature maps, which are then used to predict object locations. Although promising, these approaches fail to effectively transfer information between views and do not further refine the spatial relationship feature maps. This results in the model erroneously focusing on irrelevant edge noise, thereby affecting localization performance. To address these limitations, we introduce a Cross-view and Cross-attention Module (CVCAM), which performs multiple iterations of interaction between the two views, enabling continuous exchange and learning of contextual information about the query object from both perspectives. This facilitates a deeper understanding of cross-view relationships while suppressing the edge noise unrelated to the query object. Furthermore, we integrate a Multi-head Spatial Attention Module (MHSAM), which employs convolutional kernels of various sizes to extract multi-scale spatial features from the feature maps containing implicit correspondences, further enhancing the feature representation of the query object. Additionally, given the scarcity of datasets for cross-view object geo-localization, we created a new dataset called G2D for the "Ground-to-Drone" localization task, enriching existing datasets and filling the gap in "Ground-to-Drone" localization task. Extensive experiments on the CVOGL and G2D datasets demonstrate that our proposed method achieves high localization accuracy, surpassing the current state-of-the-art.
翻译:暂无翻译