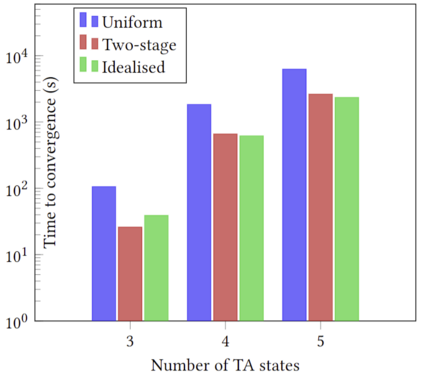
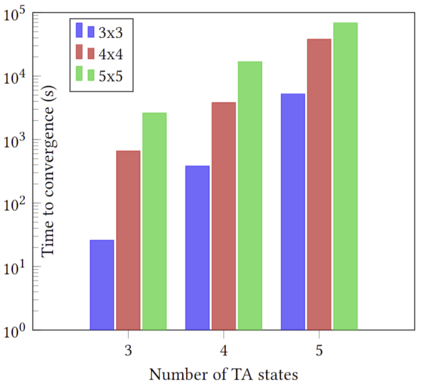
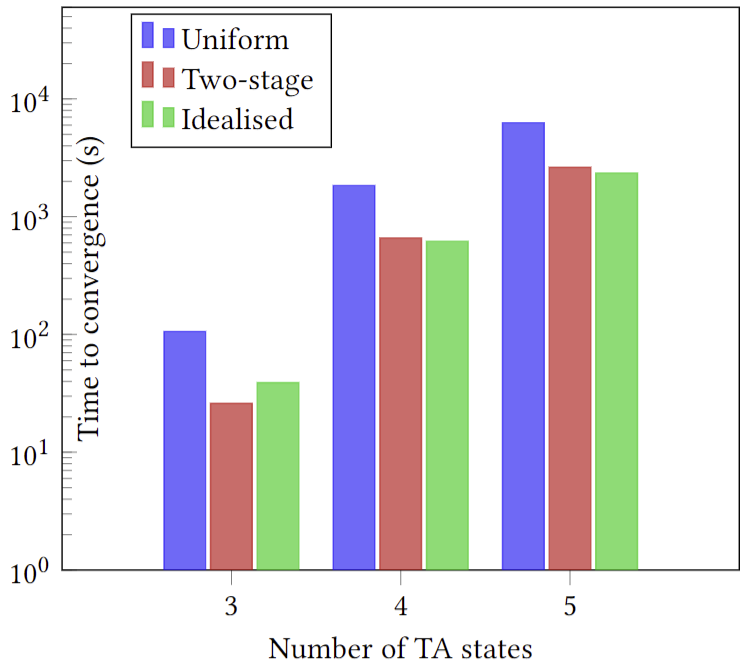
Training reinforcement learning (RL) agents using scalar reward signals is often infeasible when an environment has sparse and non-Markovian rewards. Moreover, handcrafting these reward functions before training is prone to misspecification, especially when the environment's dynamics are only partially known. This paper proposes a novel pipeline for learning non-Markovian task specifications as succinct finite-state `task automata' from episodes of agent experience within unknown environments. We leverage two key algorithmic insights. First, we learn a product MDP, a model composed of the specification's automaton and the environment's MDP (both initially unknown), by treating the product MDP as a partially observable MDP and using the well-known Baum-Welch algorithm for learning hidden Markov models. Second, we propose a novel method for distilling the task automaton (assumed to be a deterministic finite automaton) from the learnt product MDP. Our learnt task automaton enables the decomposition of a task into its constituent sub-tasks, which improves the rate at which an RL agent can later synthesise an optimal policy. It also provides an interpretable encoding of high-level environmental and task features, so a human can readily verify that the agent has learnt coherent tasks with no misspecifications. In addition, we take steps towards ensuring that the learnt automaton is environment-agnostic, making it well-suited for use in transfer learning. Finally, we provide experimental results compared with two baselines to illustrate our algorithm's performance in different environments and tasks.
翻译:使用 scalar 奖励 信号的强化培训代理机构 使用 scalar 奖赏 奖励 信号在环境稀少和非 Markovian 奖赏时往往不可行。 此外, 在培训前手工制作这些奖赏功能容易被错误地区分, 特别是当环境动态仅部分为已知时。 本文提出一个新的管道, 用于学习非Markovian 任务规格, 即根据未知环境中的代理经验, 简单化的限定状态 `task automata' 。 我们利用两种关键的算法洞察。 首先, 我们学习了一种产品 MDP, 由规格的自动地图和环境 MDP (最初为未知) 构成的模型, 将产品 MDP 视为部分可观测的 MDP, 使用众所周知的 Baum- Welch 算法算法来学习隐藏的 Markov 模型。 其次, 我们提出一种新的方法, 将任务( 被认为具有确定性的) 自动图解说, 我们所学的自动图解说, 也可以将一个快速化的动作转换到 。