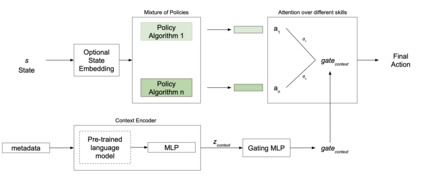
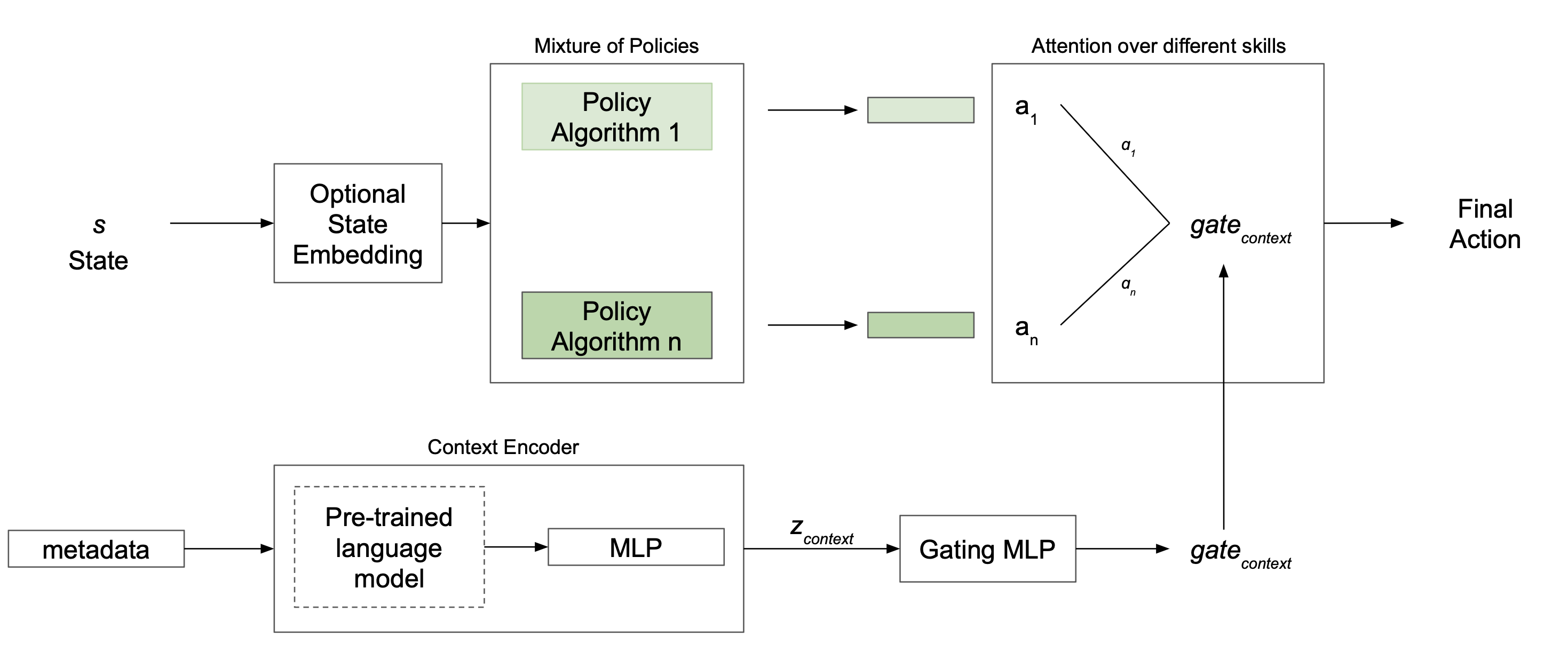
Multi-task reinforcement learning often relies on task metadata -- such as brief natural-language descriptions -- to guide behavior across diverse objectives. We present Lexical Policy Networks (LEXPOL), a language-conditioned mixture-of-policies architecture for multi-task RL. LEXPOL encodes task metadata with a text encoder and uses a learned gating module to select or blend among multiple sub-policies, enabling end-to-end training across tasks. On MetaWorld benchmarks, LEXPOL matches or exceeds strong multi-task baselines in success rate and sample efficiency, without task-specific retraining. To analyze the mechanism, we further study settings with fixed expert policies obtained independently of the gate and show that the learned language gate composes these experts to produce behaviors appropriate to novel task descriptions and unseen task combinations. These results indicate that natural-language metadata can effectively index and recombine reusable skills within a single policy.
翻译:暂无翻译