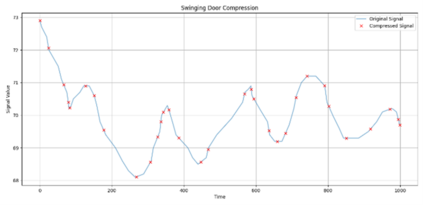
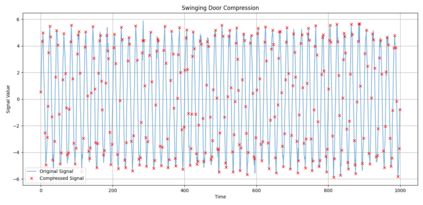
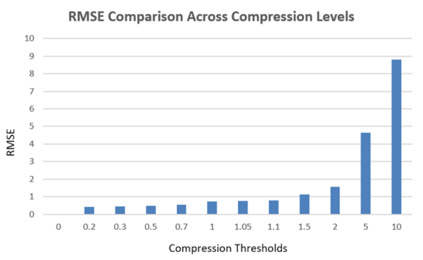
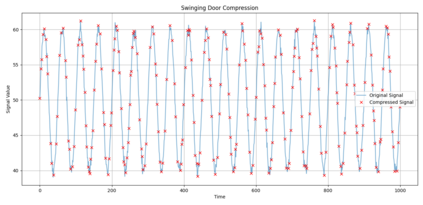
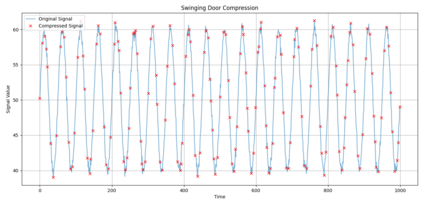
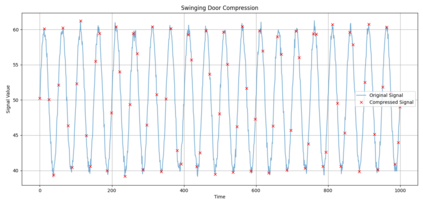
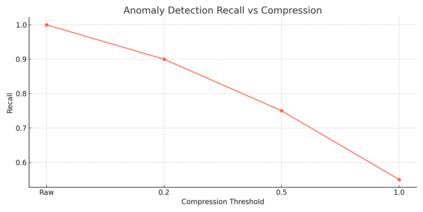
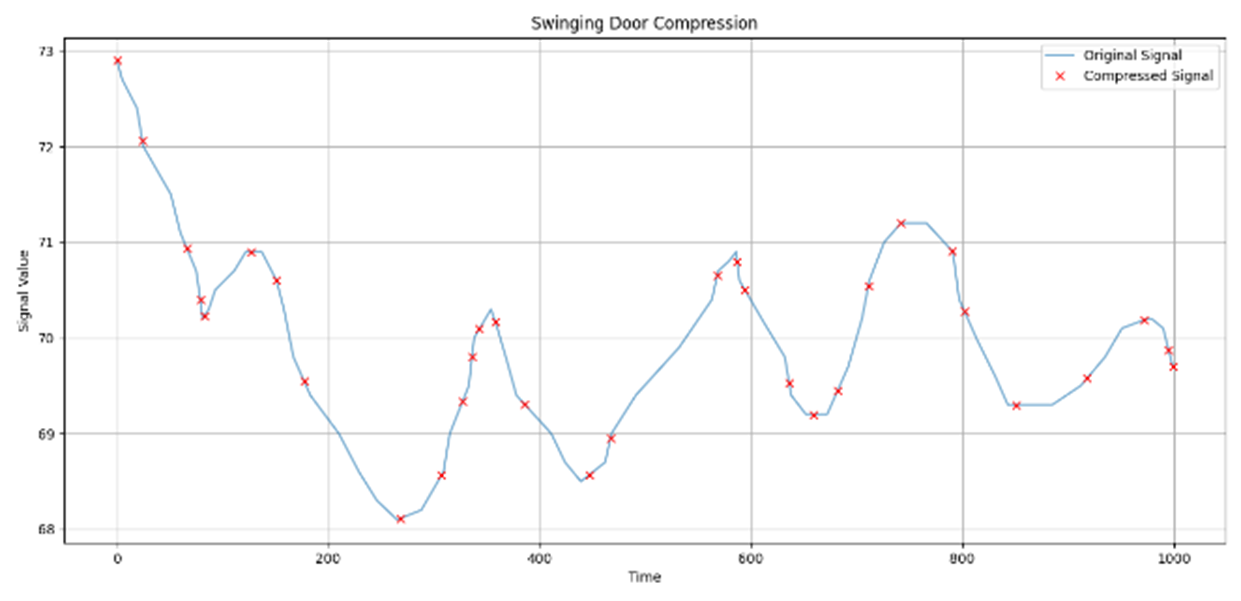
In industrial and IoT environments, massive amounts of real-time and historical process data are continuously generated and archived. With sensors and devices capturing every operational detail, the volume of time-series data has become a critical challenge for storage and processing systems. Efficient data management is essential to ensure scalability, cost-effectiveness, and timely analytics. To minimize storage expenses and optimize performance, data compression algorithms are frequently utilized in data historians and acquisition systems. However, compression comes with trade-offs that may compromise the accuracy and reliability of engineering analytics that depend on this compressed data. Understanding these trade-offs is essential for developing data strategies that support both operational efficiency and accurate, reliable analytics. This paper assesses the relation of common compression mechanisms used in real-time and historical data systems and the accuracy of analytical solutions, including statistical analysis, anomaly detection, and machine learning models. Through theoretical analysis, simulated signal compression, and empirical assessment, we illustrate that excessive compression can lose critical patterns, skew statistical measures, and diminish predictive accuracy. The study suggests optimum methods and best practices for striking a compromise between analytical integrity and compression efficiency.
翻译:在工业与物联网环境中,海量的实时与历史过程数据持续生成并归档。随着传感器与设备捕获每个操作细节,时间序列数据的规模已成为存储与处理系统的关键挑战。高效的数据管理对于确保可扩展性、成本效益与及时分析至关重要。为降低存储成本并优化性能,数据历史库与采集系统常采用数据压缩算法。然而,压缩会带来权衡,可能损害依赖此类压缩数据的工程分析的准确性与可靠性。理解这些权衡对于制定既能支持运营效率又能保障准确可靠分析的数据策略至关重要。本文评估了实时与历史数据系统中常用压缩机制与分析解精度之间的关系,涵盖统计分析、异常检测与机器学习模型。通过理论分析、模拟信号压缩与实证评估,我们阐明过度压缩会丢失关键模式、扭曲统计度量并降低预测精度。本研究提出了在分析完整性与压缩效率之间达成平衡的最优方法与最佳实践。