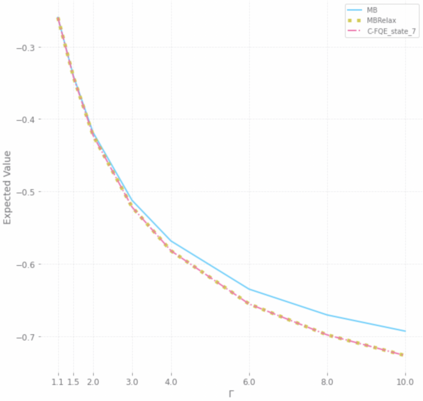
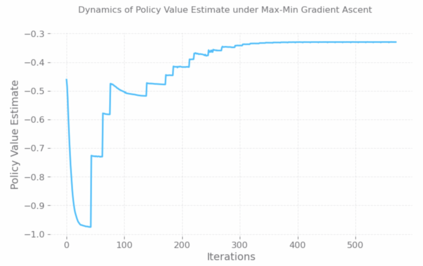
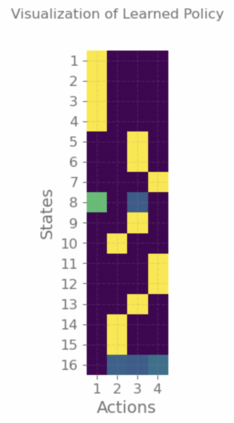
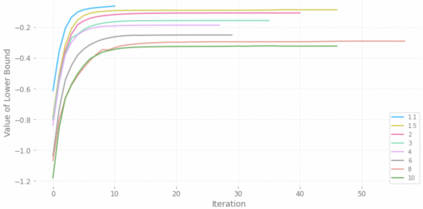
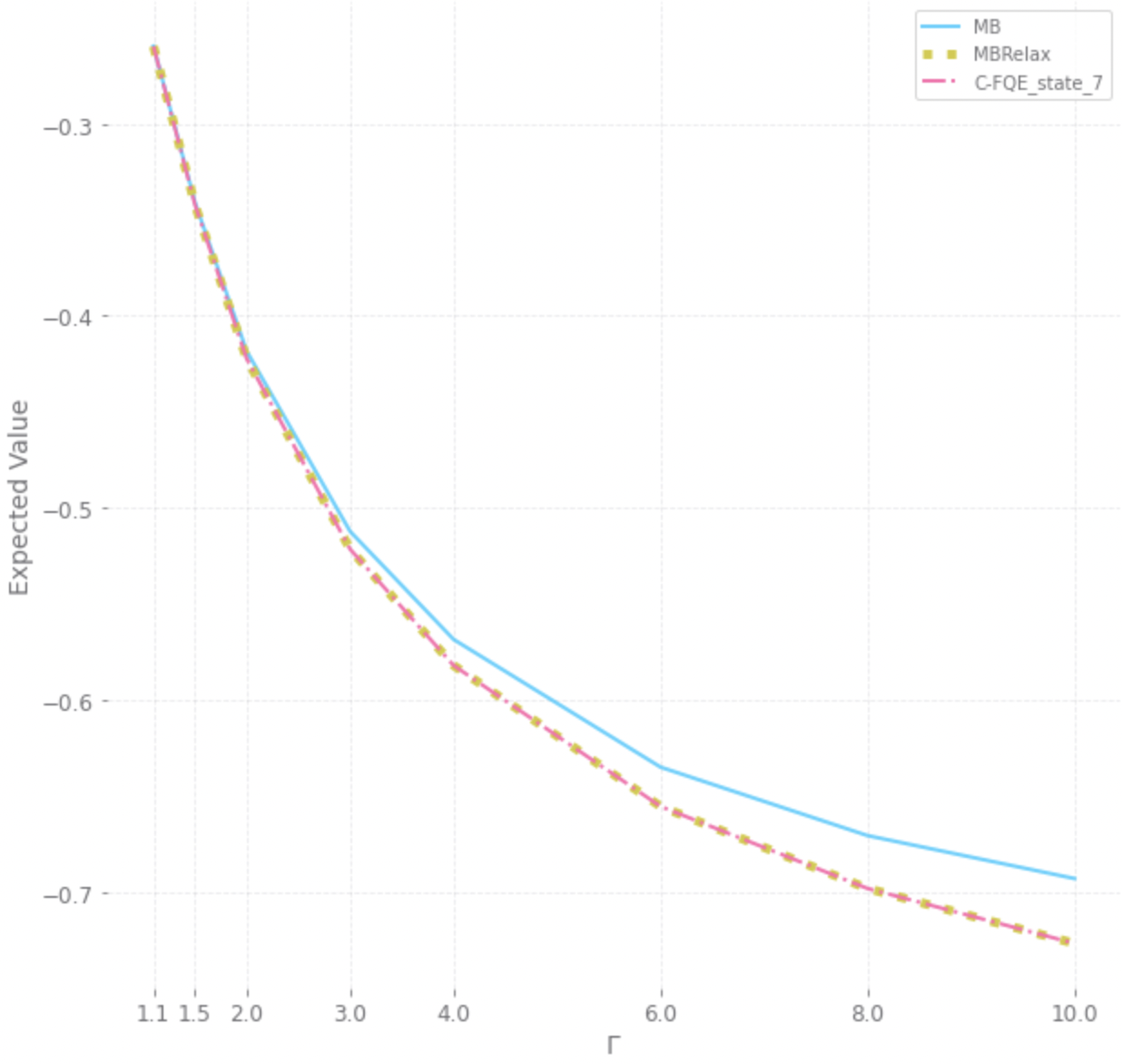
With a few exceptions, work in offline reinforcement learning (RL) has so far assumed that there is no confounding. In a classical regression setting, confounders introduce omitted variable bias and inhibit the identification of causal effects. In offline RL, they prevent the identification of a policy's value, and therefore make it impossible to perform policy improvement. Using conventional methods in offline RL in the presence of confounding can therefore not only lead to poor decisions and poor policies, but can also have disastrous effects in applications such as healthcare and education. We provide approaches for both off-policy evaluation (OPE) and local policy optimization in the settings of i.i.d. and global confounders. Theoretical and empirical results confirm the validity and viability of these methods.
翻译:除少数例外情况外,离线强化学习(RL)迄今一直认为不存在混乱。在古老的回归环境中,混淆者引入了省略的可变偏差,并抑制了因果关系的识别。在离线强化学习(RL)中,他们阻止了对政策价值的识别,因此无法进行政策改进。因此,在离线强化学习(RL)中使用离线强化学习(RL)不仅会导致决策不力和政策不善,而且可能对保健和教育等应用产生灾难性影响。 我们为离政策评估(OPE)和当地政策优化(i.d.)和全球融合者提供了方法。理论和实证结果证实了这些方法的有效性和可行性。