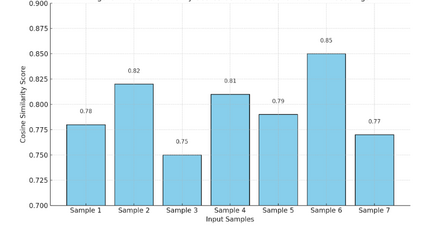
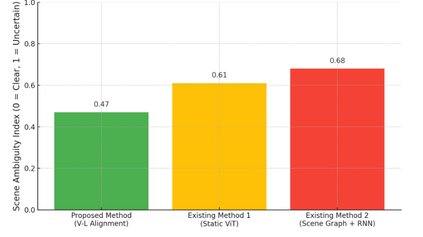
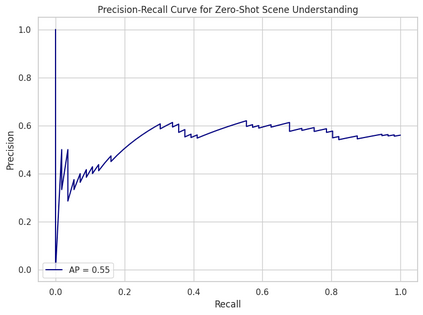
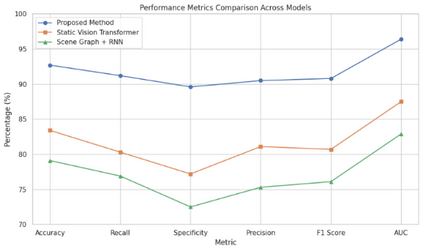
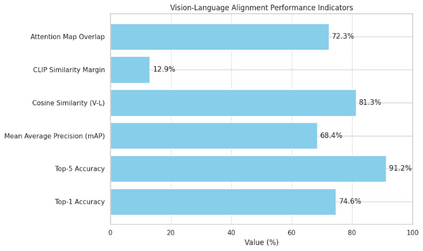
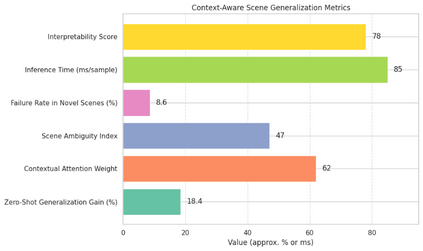
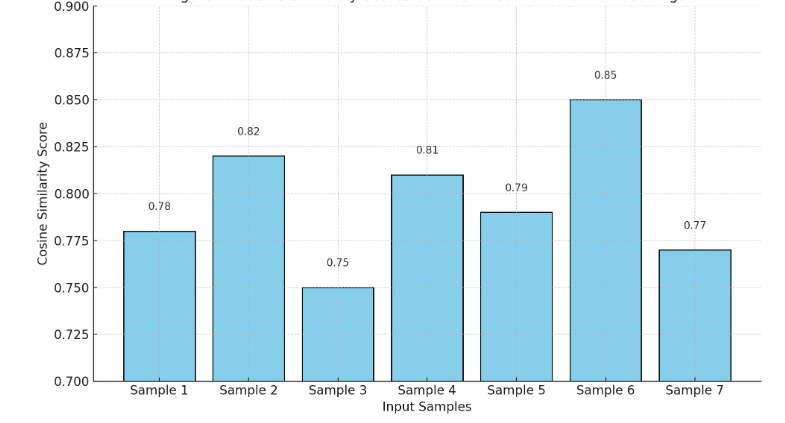
In real-world environments, AI systems often face unfamiliar scenarios without labeled data, creating a major challenge for conventional scene understanding models. The inability to generalize across unseen contexts limits the deployment of vision-based applications in dynamic, unstructured settings. This work introduces a Dynamic Context-Aware Scene Reasoning framework that leverages Vision-Language Alignment to address zero-shot real-world scenarios. The goal is to enable intelligent systems to infer and adapt to new environments without prior task-specific training. The proposed approach integrates pre-trained vision transformers and large language models to align visual semantics with natural language descriptions, enhancing contextual comprehension. A dynamic reasoning module refines predictions by combining global scene cues and object-level interactions guided by linguistic priors. Extensive experiments on zero-shot benchmarks such as COCO, Visual Genome, and Open Images demonstrate up to 18% improvement in scene understanding accuracy over baseline models in complex and unseen environments. Results also show robust performance in ambiguous or cluttered scenes due to the synergistic fusion of vision and language. This framework offers a scalable and interpretable approach for context-aware reasoning, advancing zero-shot generalization in dynamic real-world settings.
翻译:暂无翻译