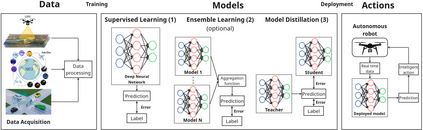
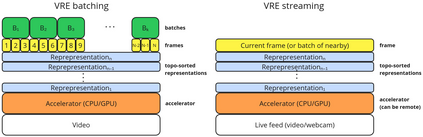
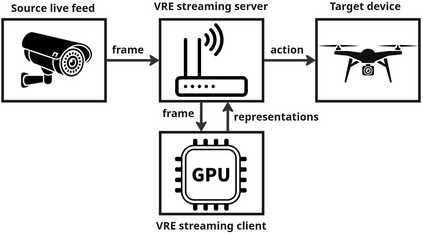
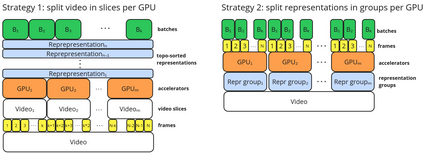
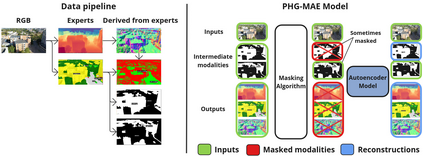
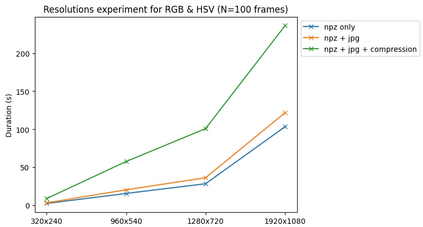
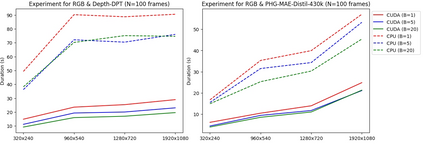
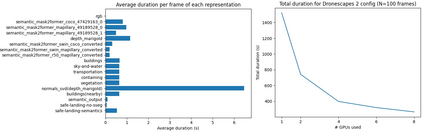
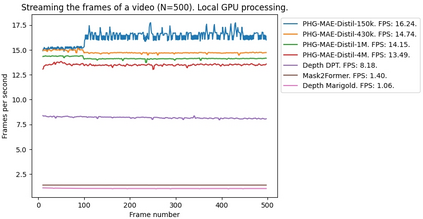
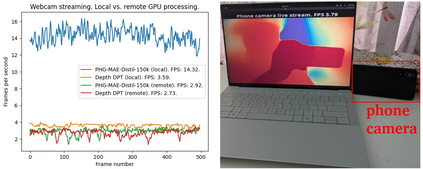
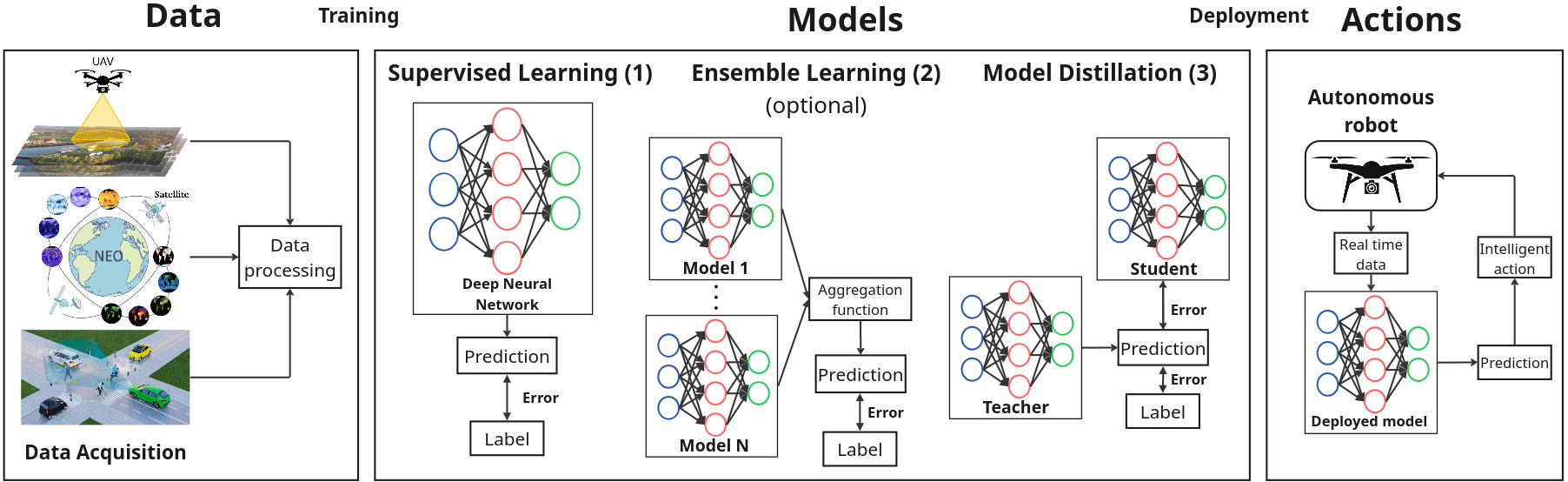
The real-world is inherently multi-modal at its core. Our tools observe and take snapshots of it, in digital form, such as videos or sounds, however much of it is lost. Similarly for actions and information passing between humans, languages are used as a written form of communication. Traditionally, Machine Learning models have been unimodal (i.e. rgb -> semantic or text -> sentiment_class). Recent trends go towards bi-modality, where images and text are learned together, however, in order to truly understand the world, we need to integrate all these independent modalities. In this work we try to combine as many visual modalities as we can using little to no human supervision. In order to do this, we use pre-trained experts and procedural combinations between them on top of raw videos using a fully autonomous data-pipeline, which we also open-source. We then make use of PHG-MAE, a model specifically designed to leverage multi-modal data. We show that this model which was efficiently distilled into a low-parameter (<1M) can have competitive results compared to models of ~300M parameters. We deploy this model and analyze the use-case of real-time semantic segmentation from handheld devices or webcams on commodity hardware. Finally, we deploy other off-the-shelf models using the same framework, such as DPT for near real-time depth estimation.
翻译:暂无翻译