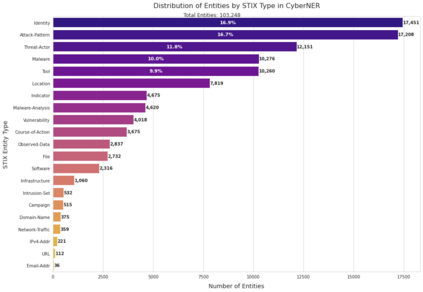
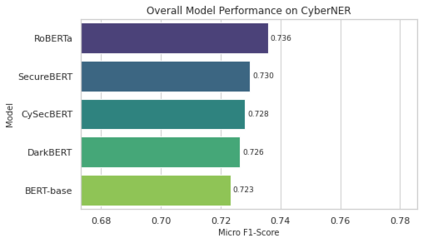
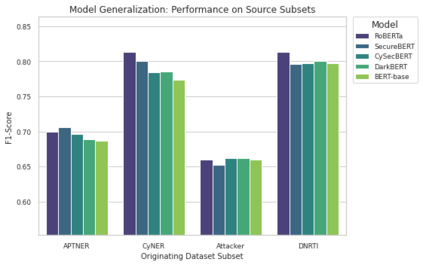
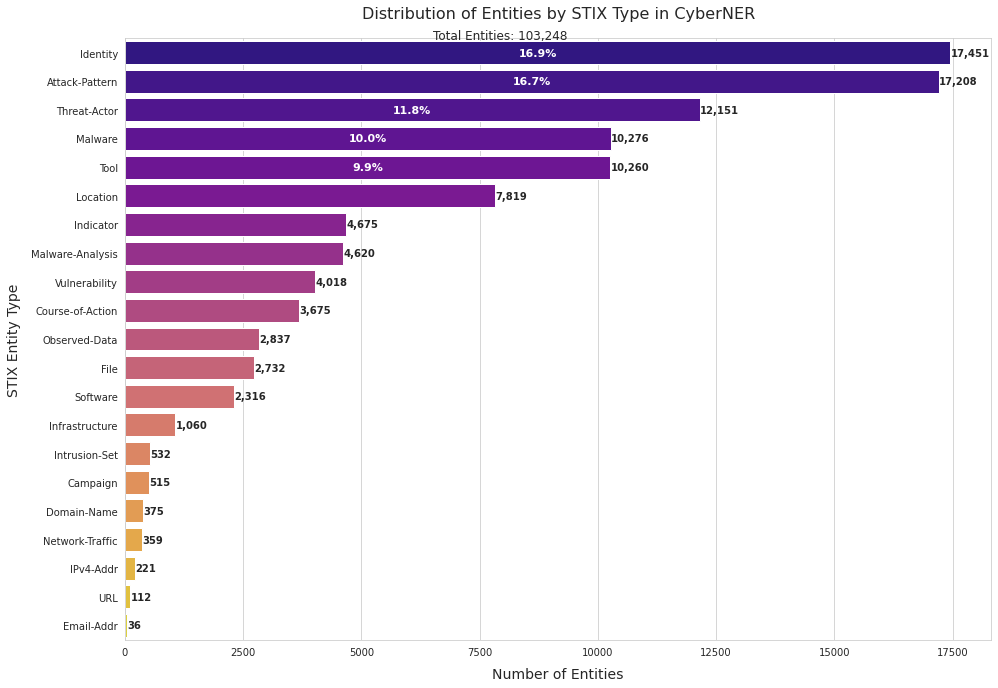
Extracting structured intelligence via Named Entity Recognition (NER) is critical for cybersecurity, but the proliferation of datasets with incompatible annotation schemas hinders the development of comprehensive models. While combining these resources is desirable, we empirically demonstrate that naively concatenating them results in a noisy label space that severely degrades model performance. To overcome this critical limitation, we introduce CyberNER, a large-scale, unified corpus created by systematically harmonizing four prominent datasets (CyNER, DNRTI, APTNER, and Attacker) onto the STIX 2.1 standard. Our principled methodology resolves semantic ambiguities and consolidates over 50 disparate source tags into 21 coherent entity types. Our experiments show that models trained on CyberNER achieve a substantial performance gain, with a relative F1-score improvement of approximately 30% over the naive concatenation baseline. By publicly releasing the CyberNER corpus, we provide a crucial, standardized benchmark that enables the creation and rigorous comparison of more robust and generalizable entity extraction models for the cybersecurity domain.
翻译:暂无翻译