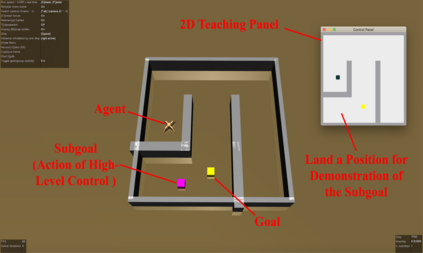
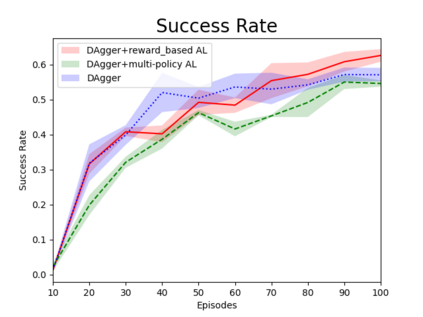
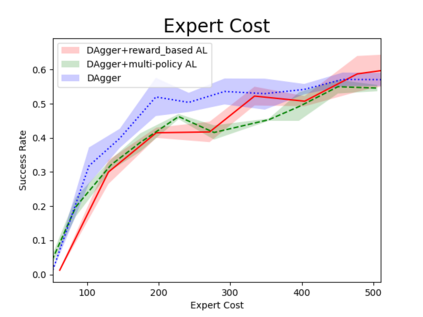
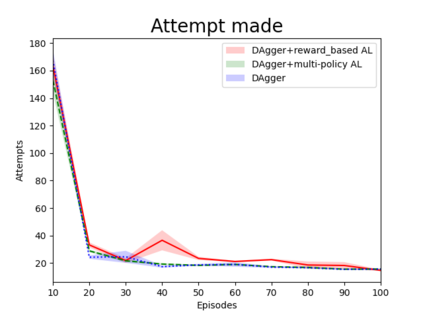
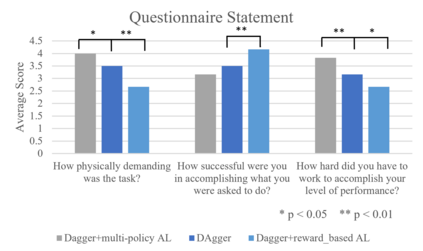
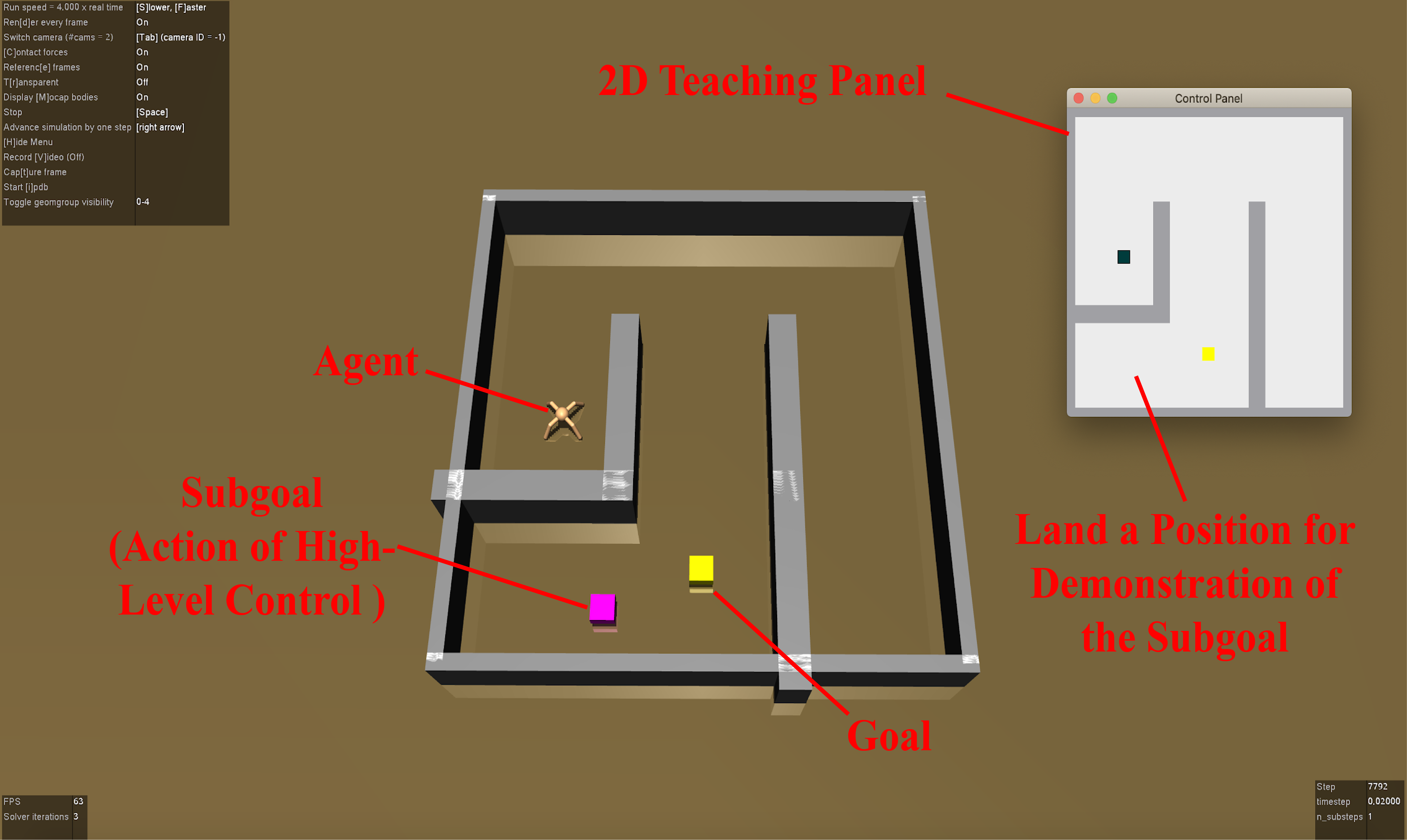
Humans can leverage hierarchical structures to split a task into sub-tasks and solve problems efficiently. Both imitation and reinforcement learning or a combination of them with hierarchical structures have been proven to be an efficient way for robots to learn complex tasks with sparse rewards. However, in the previous work of hierarchical imitation and reinforcement learning, the tested environments are in relatively simple 2D games, and the action spaces are discrete. Furthermore, many imitation learning works focusing on improving the policies learned from the expert polices that are hard-coded or trained by reinforcement learning algorithms, rather than human experts. In the scenarios of human-robot interaction, humans can be required to provide demonstrations to teach the robot, so it is crucial to improve the learning efficiency to reduce expert efforts, and know human's perception about the learning/training process. In this project, we explored different imitation learning algorithms and designed active learning algorithms upon the hierarchical imitation and reinforcement learning framework we have developed. We performed an experiment where five participants were asked to guide a randomly initialized agent to a random goal in a maze. Our experimental results showed that using DAgger and reward-based active learning method can achieve better performance while saving more human efforts physically and mentally during the training process.
翻译:人类可以利用等级结构将任务分成子任务,并有效地解决问题。模仿和强化学习或将它们与等级结构相结合,已被证明是机器人学习复杂任务的有效方法。然而,在以往的等级模仿和强化学习工作中,经过测试的环境是相对简单的2D游戏,行动空间是互不相连的。此外,许多模仿学习工作侧重于改进从专家政策中学到的政策,这些专家政策是硬码的或经过强化学习算法培训的,而不是人类专家。在人类机器人互动的情况下,可以要求人类提供演示来教授机器人,因此,提高学习效率以减少专家的努力,了解人类对学习/训练过程的看法至关重要。在这个项目中,我们探索了不同的模仿算法,并在我们制定的等级模仿和强化学习框架上设计了积极的学习算法。我们进行了一项实验,要求5名参与者指导随机初始化的代理人在迷宫中实现随机目的。我们的实验结果显示,在更积极的学习过程中,使用Dagger和奖励性的方法可以取得更好的成绩。