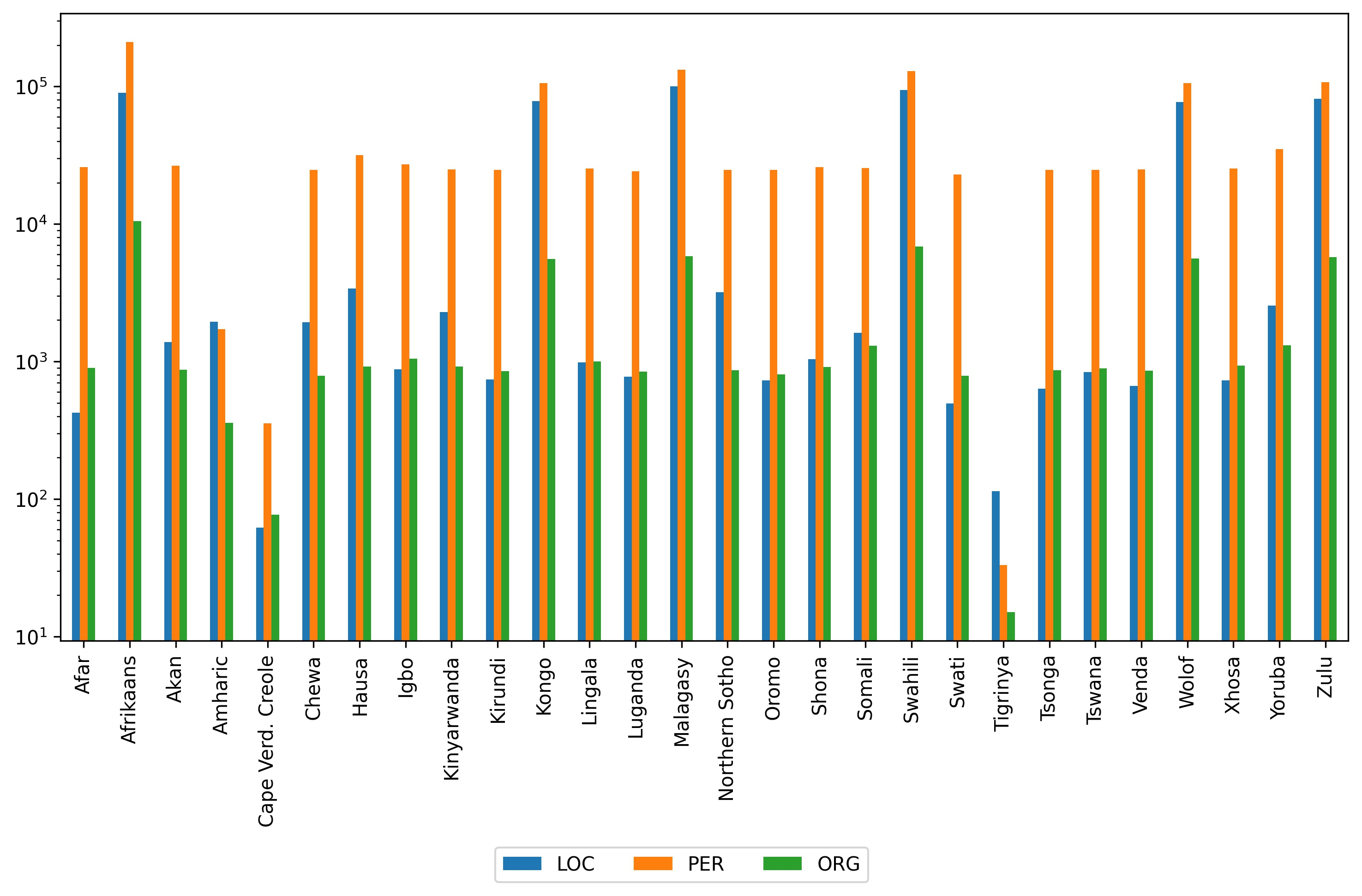
This work supports further development of language technology for the languages of Africa by providing a Wikidata-derived resource of name lists corresponding to common entity types (person, location, and organization). While we are not the first to mine Wikidata for name lists, our approach emphasizes scalability and replicability and addresses data quality issues for languages that do not use Latin scripts. We produce lists containing approximately 1.9 million names across 28 African languages. We describe the data, the process used to produce it, and its limitations, and provide the software and data for public use. Finally, we discuss the ethical considerations of producing this resource and others of its kind.
翻译:这项工作通过提供与共同实体类型(人员、地点和组织)相对应的Wikita派生地名清单资源,支持进一步开发非洲语文的语言技术。虽然我们并不是第一个在地名清单中使用Wikita的维基数据,但我们的方法强调可扩展性和可复制性,并解决不使用拉丁文字的语文的数据质量问题。我们制作了28种非洲语文的190万个地名清单。我们描述了数据、制作数据所用的程序及其局限性,并提供软件和数据供公众使用。最后,我们讨论了制作这一资源和其他类型的资源的道德考虑。