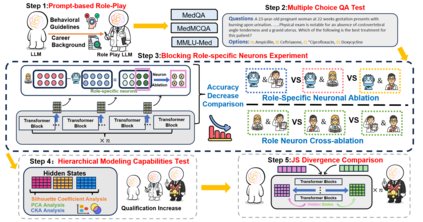
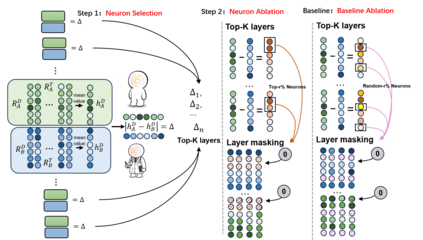
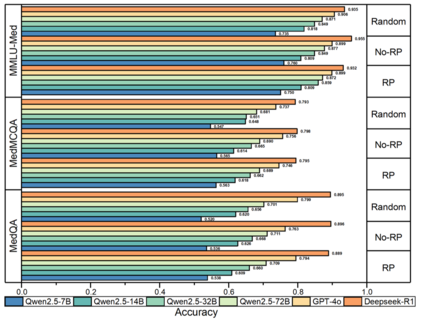
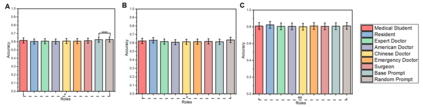
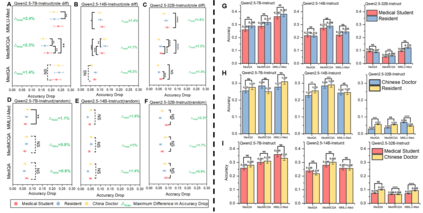
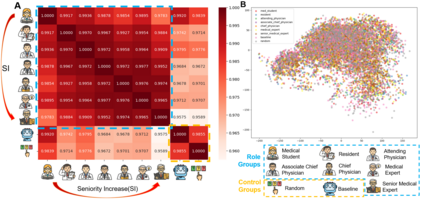
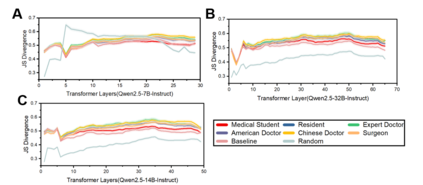
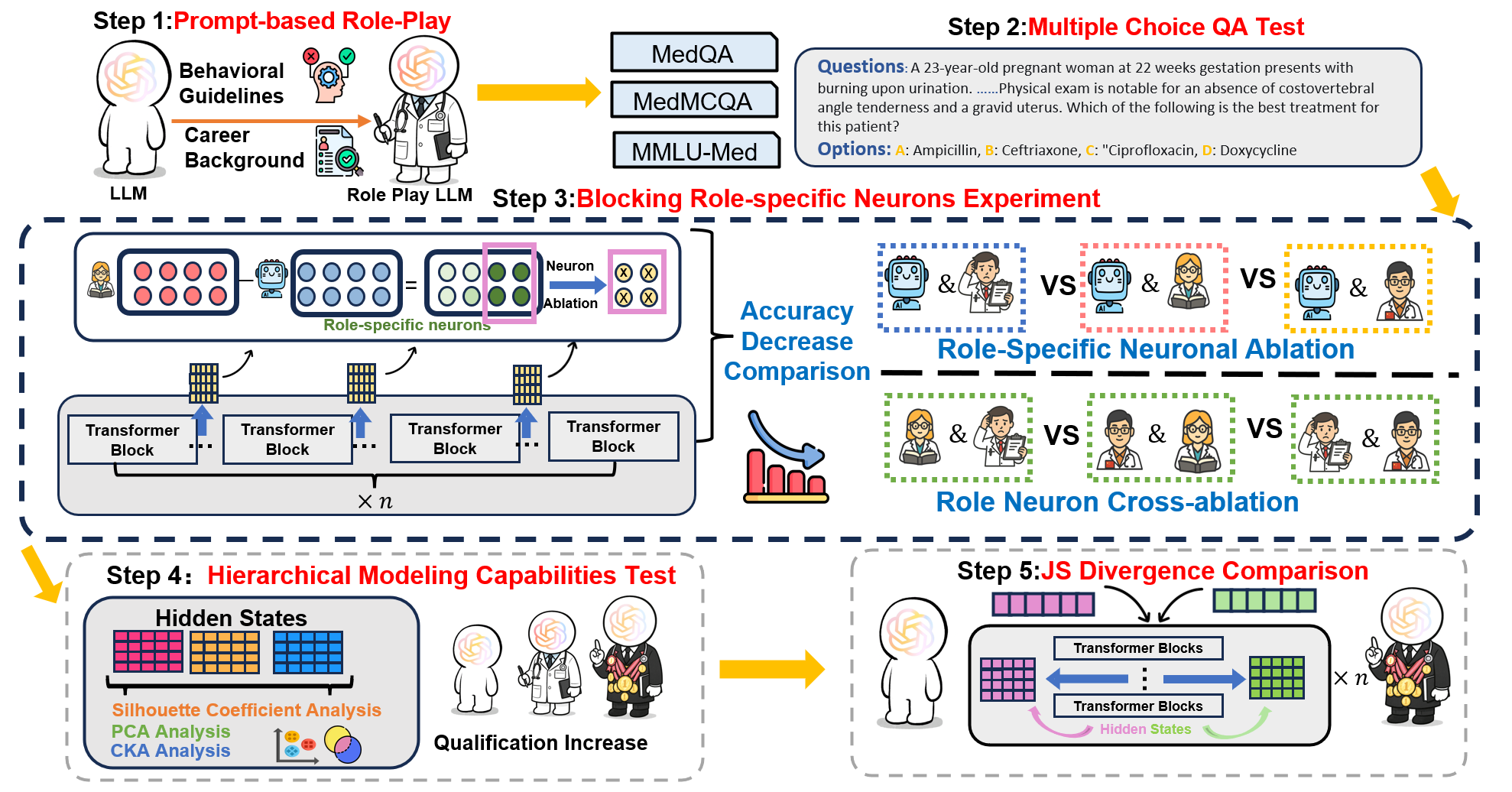
Large language models (LLMs) have gained significant traction in medical decision support systems, particularly in the context of medical question answering and role-playing simulations. A common practice, Prompt-Based Role Playing (PBRP), instructs models to adopt different clinical roles (e.g., medical students, residents, attending physicians) to simulate varied professional behaviors. However, the impact of such role prompts on model reasoning capabilities remains unclear. This study introduces the RP-Neuron-Activated Evaluation Framework(RPNA) to evaluate whether role prompts induce distinct, role-specific cognitive processes in LLMs or merely modify linguistic style. We test this framework on three medical QA datasets, employing neuron ablation and representation analysis techniques to assess changes in reasoning pathways. Our results demonstrate that role prompts do not significantly enhance the medical reasoning abilities of LLMs. Instead, they primarily affect surface-level linguistic features, with no evidence of distinct reasoning pathways or cognitive differentiation across clinical roles. Despite superficial stylistic changes, the core decision-making mechanisms of LLMs remain uniform across roles, indicating that current PBRP methods fail to replicate the cognitive complexity found in real-world medical practice. This highlights the limitations of role-playing in medical AI and emphasizes the need for models that simulate genuine cognitive processes rather than linguistic imitation.We have released the related code in the following repository:https: //github.com/IAAR-Shanghai/RolePlay_LLMDoctor
翻译:暂无翻译