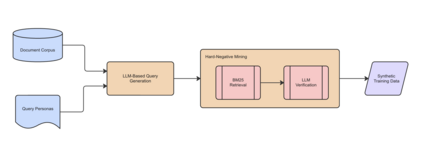
Dense embedding models have become critical for modern information retrieval, particularly in RAG pipelines, but their performance often degrades when applied to specialized corpora outside their pre-training distribution. To address thi we introduce CustomIR, a framework for unsupervised adaptation of pre-trained language embedding models to domain-specific corpora using synthetically generated query-document pairs. CustomIR leverages large language models (LLMs) to create diverse queries grounded in a known target corpus, paired with LLM-verified hard negatives, eliminating the need for costly human annotation. Experiments on enterprise email and messaging datasets show that CustomIR consistently improves retrieval effectiveness with small models gaining up to 2.3 points in Recall@10. This performance increase allows these small models to rival the performance of much larger alternatives, allowing for cheaper RAG deployments. These results highlight that targeted synthetic fine-tuning offers a scalable and cost-efficient strategy for increasing domain-specific performance.
翻译:暂无翻译