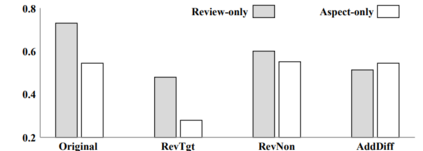
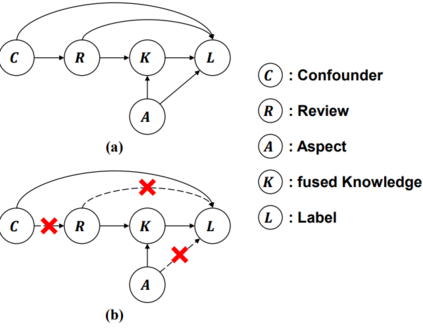
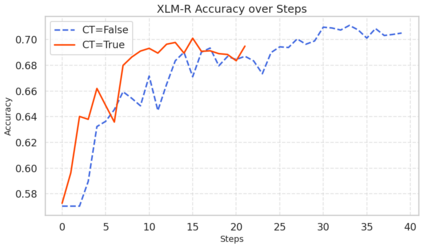
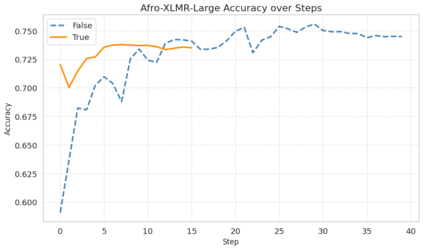
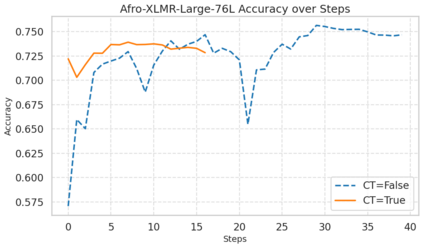
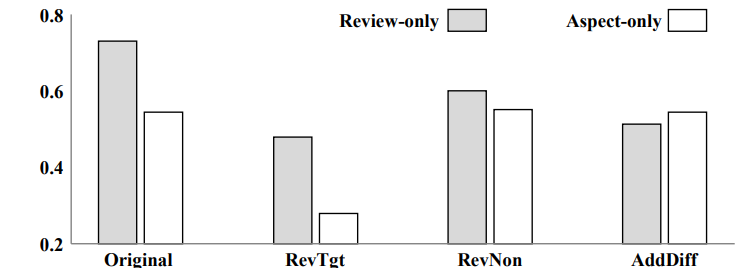
Machine learning models typically assume that training and test data follow the same distribution, an assumption that often fails in real-world scenarios due to distribution shifts. This issue is especially pronounced in low-resource settings, where data scarcity and limited domain diversity hinder robust generalization. Domain generalization (DG) approaches address this challenge by learning features that remain invariant across domains, often using causal mechanisms to improve model robustness. In this study, we examine two distinct causal DG techniques in low-resource natural language tasks. First, we investigate a causal data augmentation (CDA) approach that automatically generates counterfactual examples to improve robustness to spurious correlations. We apply this method to sentiment classification on the NaijaSenti Twitter corpus, expanding the training data with semantically equivalent paraphrases to simulate controlled distribution shifts. Second, we explore an invariant causal representation learning (ICRL) approach using the DINER framework, originally proposed for debiasing aspect-based sentiment analysis. We adapt DINER to a multilingual setting. Our findings demonstrate that both approaches enhance robustness to unseen domains: counterfactual data augmentation yields consistent cross-domain accuracy gains in sentiment classification, while causal representation learning with DINER improves out-of-distribution performance in multilingual sentiment analysis, albeit with varying gains across languages.
翻译:暂无翻译