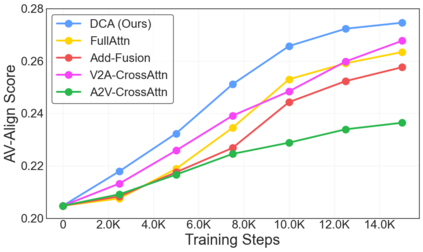
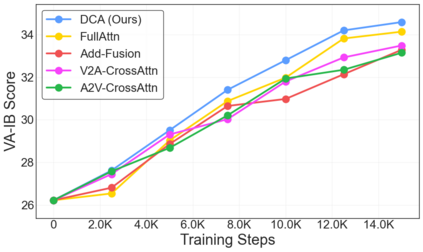
This study focuses on a challenging yet promising task, Text-to-Sounding-Video (T2SV) generation, which aims to generate a video with synchronized audio from text conditions, meanwhile ensuring both modalities are aligned with text. Despite progress in joint audio-video training, two critical challenges still remain unaddressed: (1) a single, shared text caption where the text for video is equal to the text for audio often creates modal interference, confusing the pretrained backbones, and (2) the optimal mechanism for cross-modal feature interaction remains unclear. To address these challenges, we first propose the Hierarchical Visual-Grounded Captioning (HVGC) framework that generates pairs of disentangled captions, a video caption, and an audio caption, eliminating interference at the conditioning stage. Based on HVGC, we further introduce BridgeDiT, a novel dual-tower diffusion transformer, which employs a Dual CrossAttention (DCA) mechanism that acts as a robust ``bridge" to enable a symmetric, bidirectional exchange of information, achieving both semantic and temporal synchronization. Extensive experiments on three benchmark datasets, supported by human evaluations, demonstrate that our method achieves state-of-the-art results on most metrics. Comprehensive ablation studies further validate the effectiveness of our contributions, offering key insights for the future T2SV task. All the codes and checkpoints will be publicly released.
翻译:暂无翻译