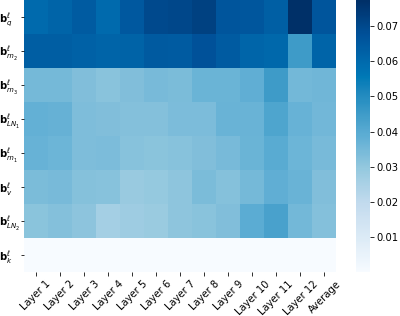
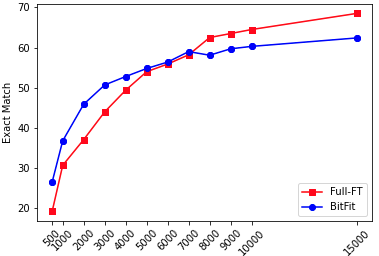
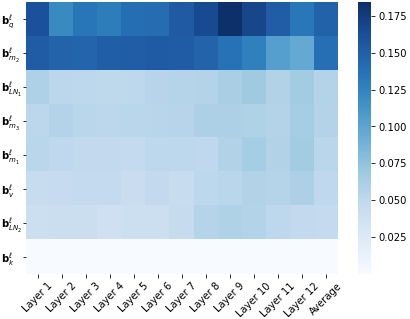
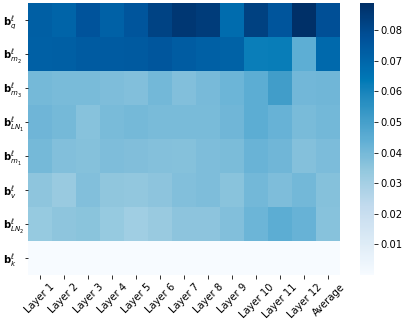
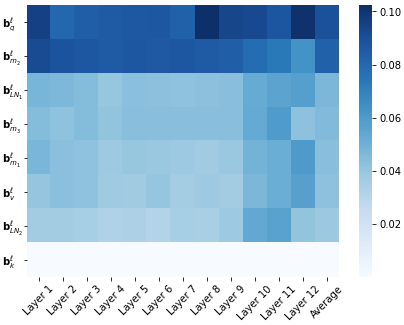
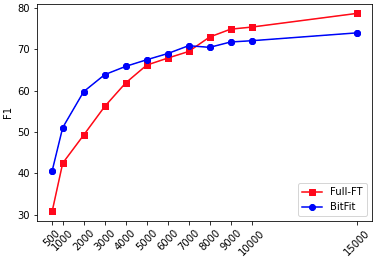
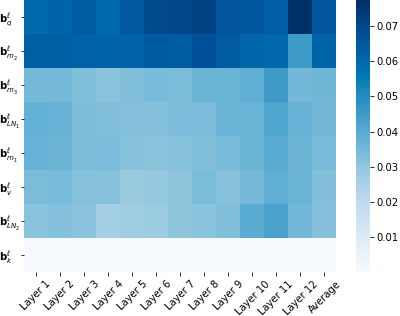
We show that with small-to-medium training data, fine-tuning only the bias terms (or a subset of the bias terms) of pre-trained BERT models is competitive with (and sometimes better than) fine-tuning the entire model. For larger data, bias-only fine-tuning is competitive with other sparse fine-tuning methods. Besides their practical utility, these findings are relevant for the question of understanding the commonly-used process of finetuning: they support the hypothesis that finetuning is mainly about exposing knowledge induced by language-modeling training, rather than learning new task-specific linguistic knowledge.
翻译:我们发现,根据中小培训数据,只有经过预先培训的BERT模型的偏差术语(或偏见术语的一个子集)才能微调整个模型(有时甚至优于),对整个模型进行微调。对于更大的数据来说,只有偏差的微调与其他微调方法相比具有竞争力。这些结论除了实用效用外,还关系到理解常用的微调过程:它们支持这样的假设,即微调主要是暴露语言建模培训引起的知识,而不是学习新的特定任务语言知识。