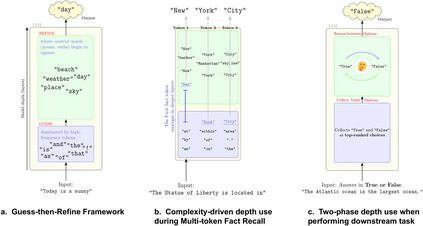
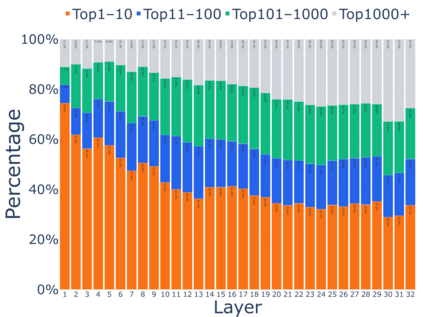
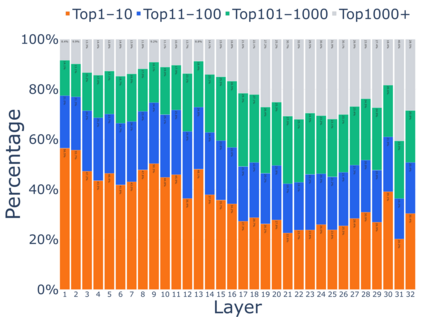
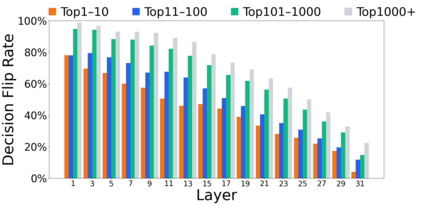
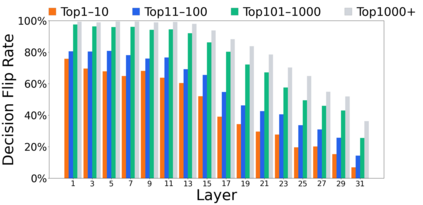
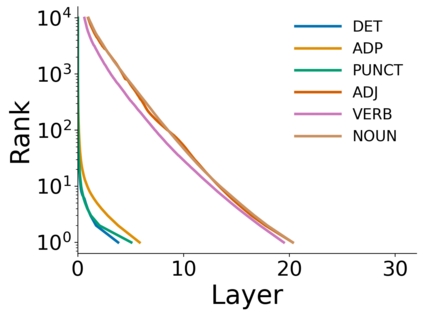
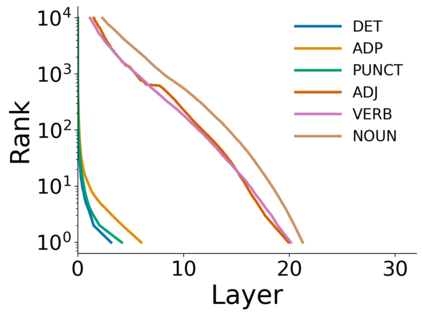
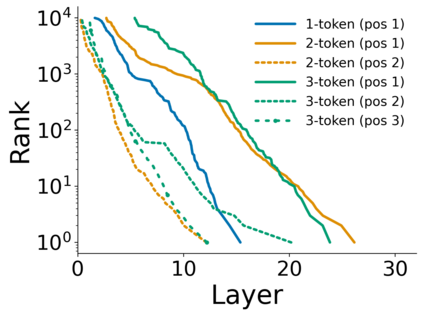
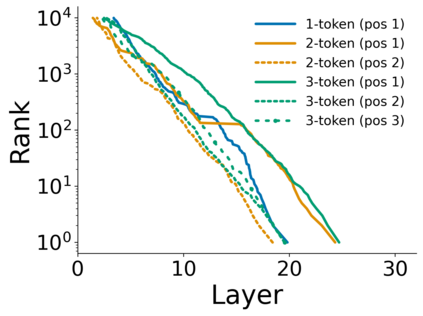
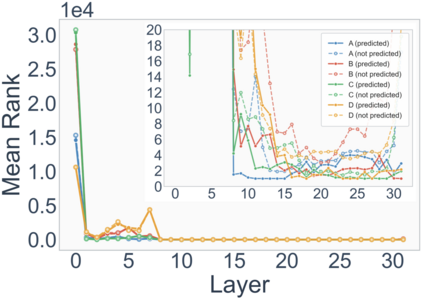
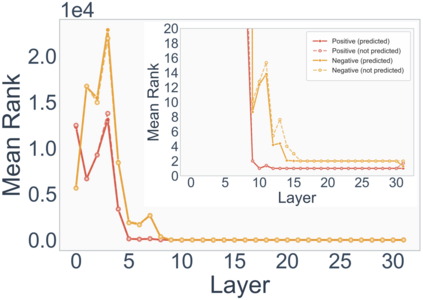
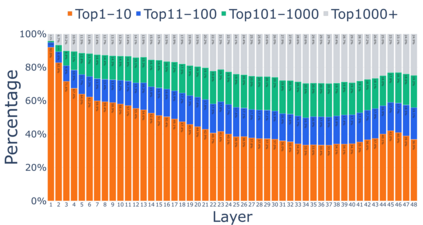
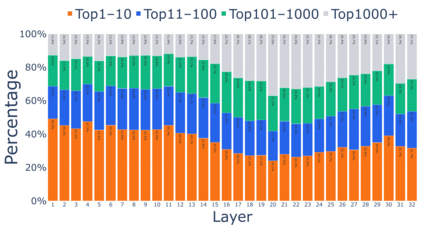
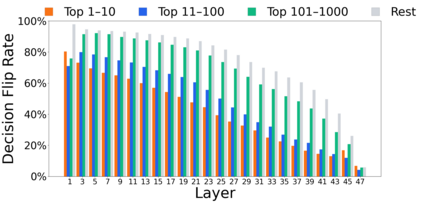
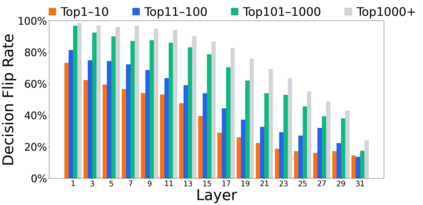
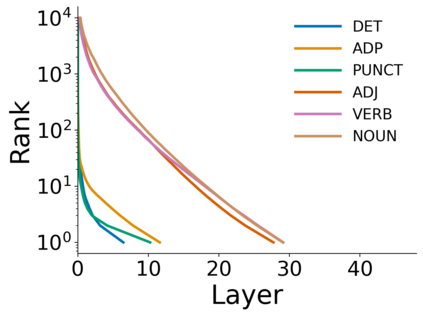
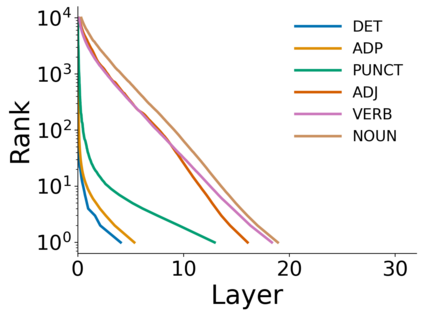
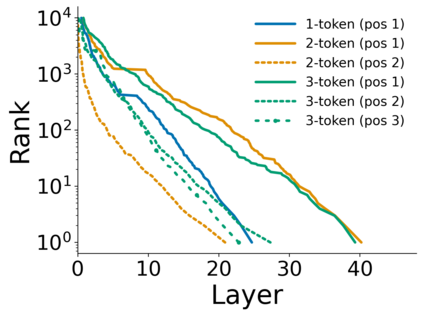
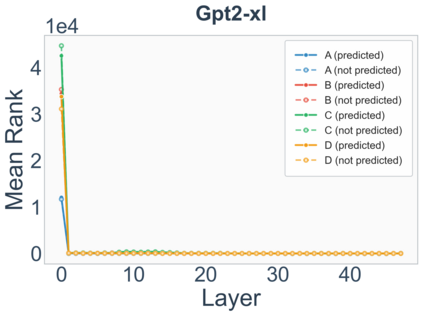
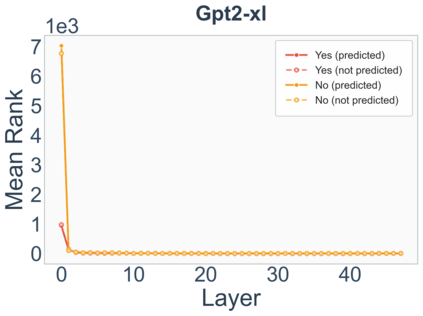
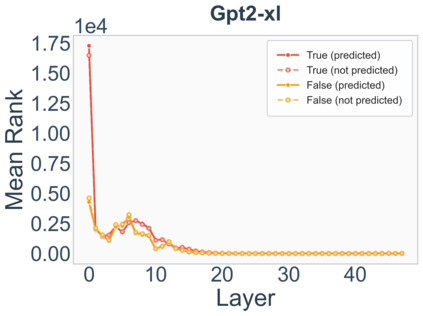
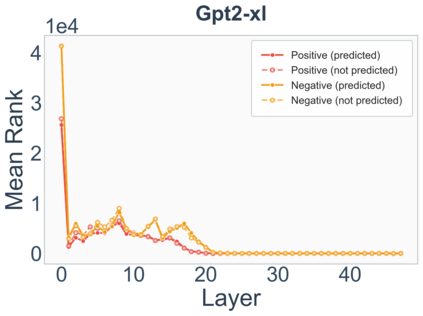
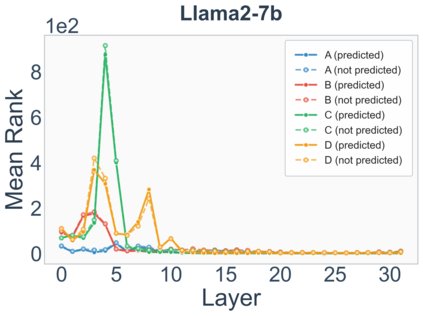
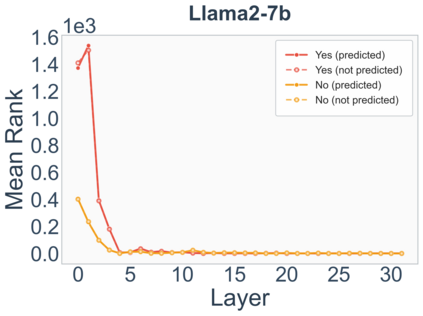
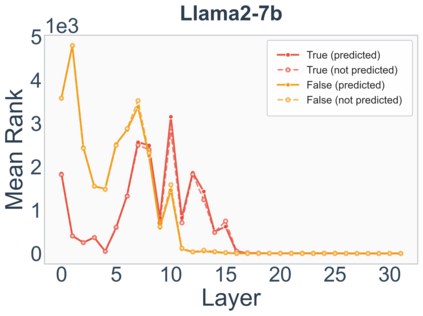
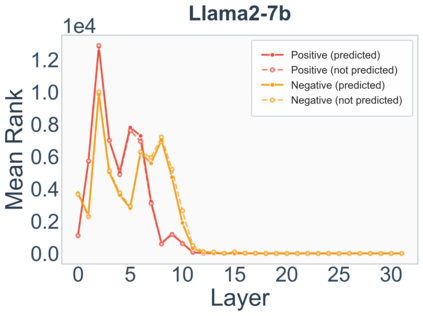
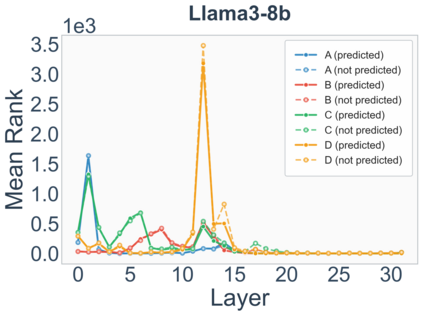
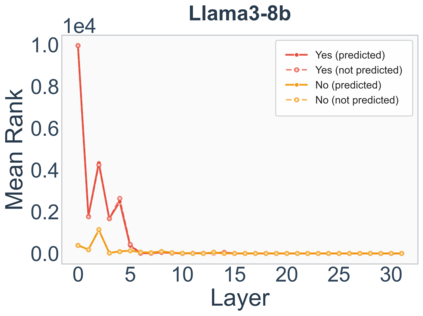
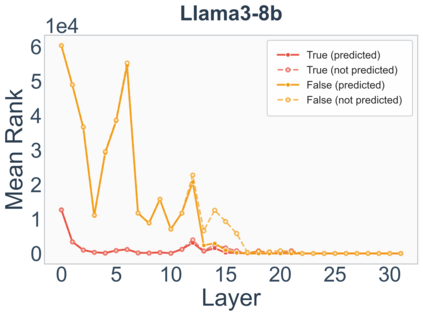
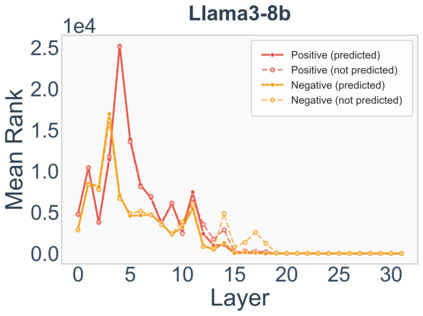
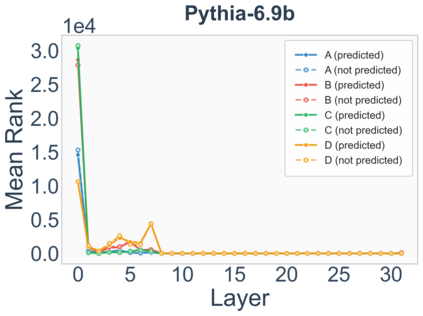
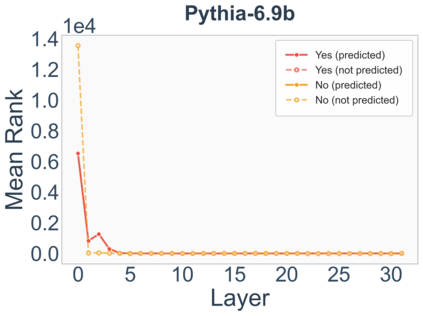
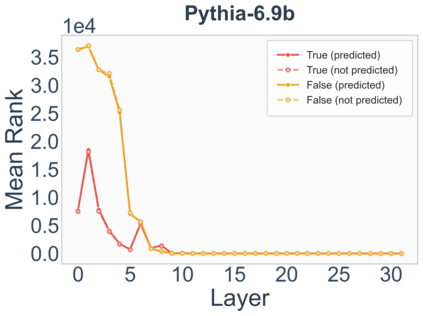
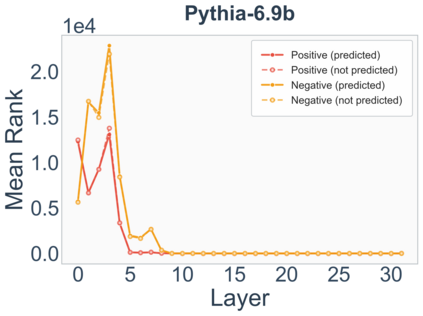
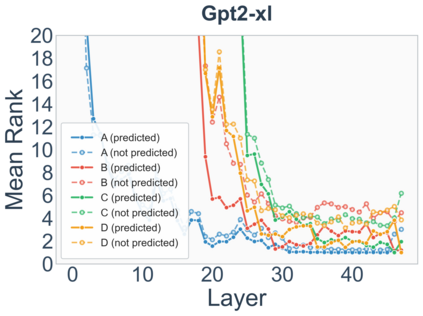
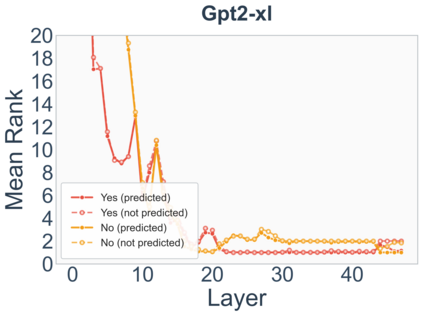
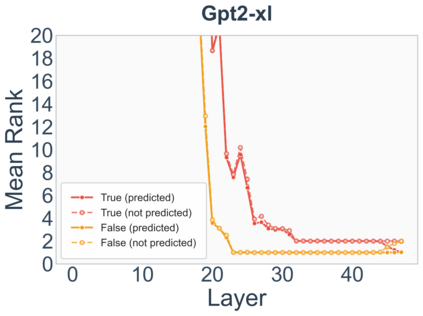
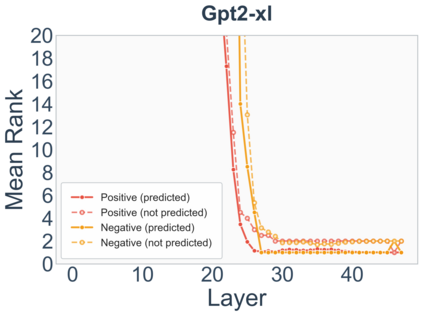
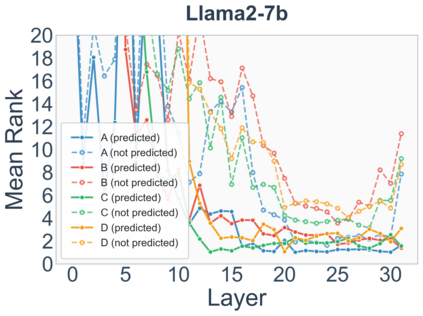
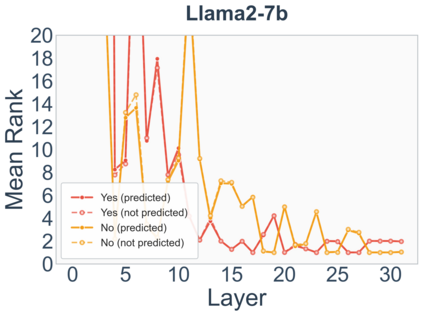
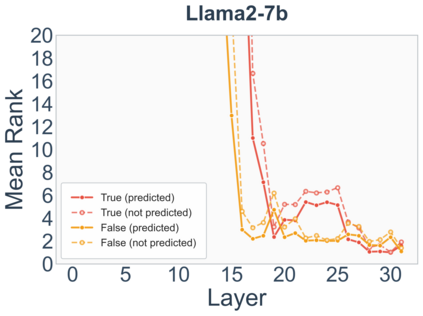
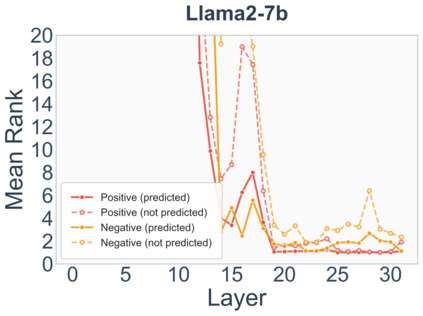
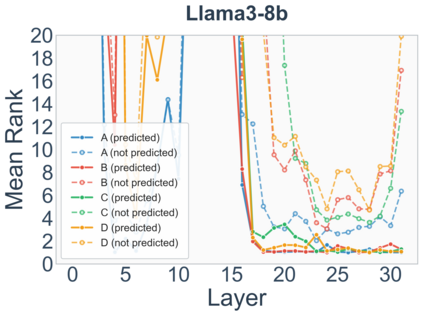
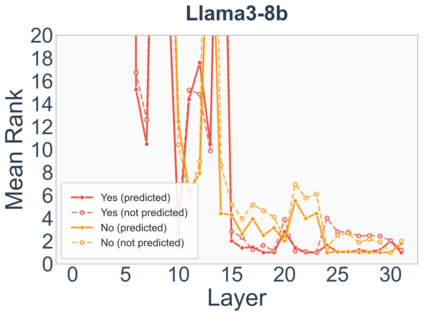
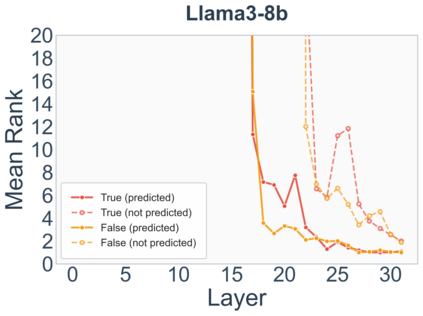
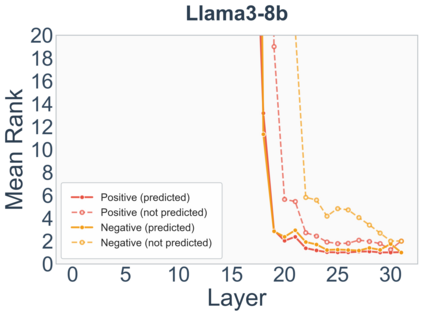
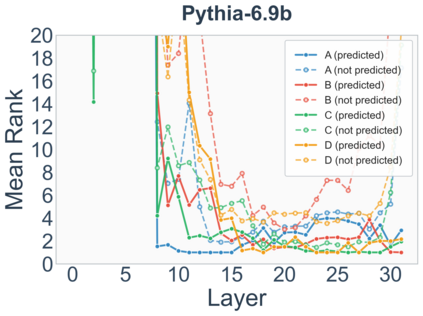
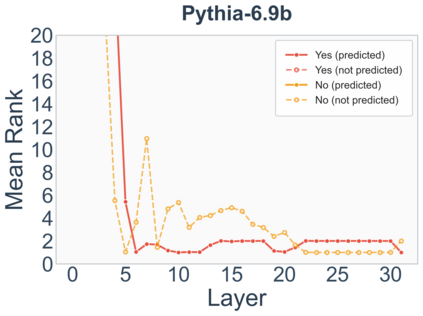
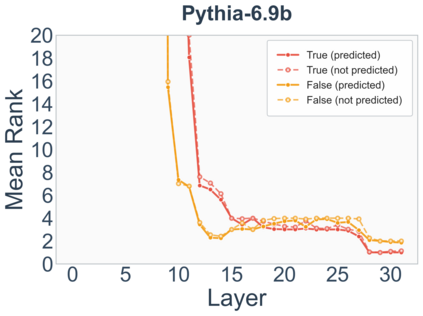
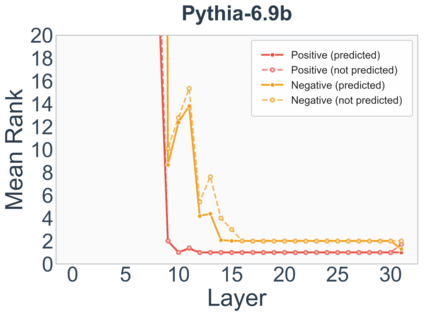
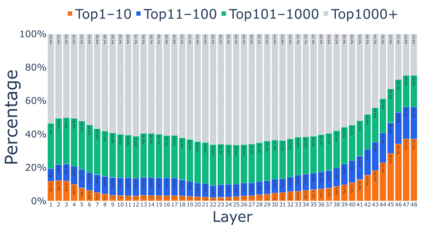
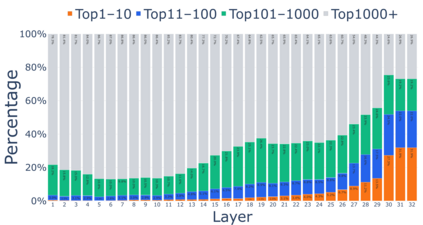
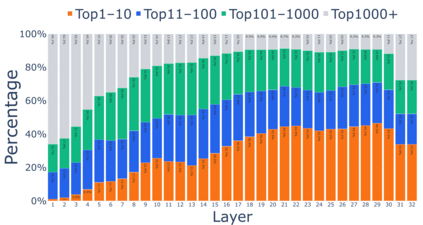
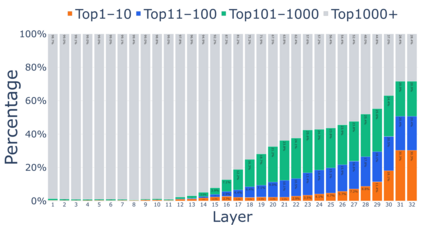
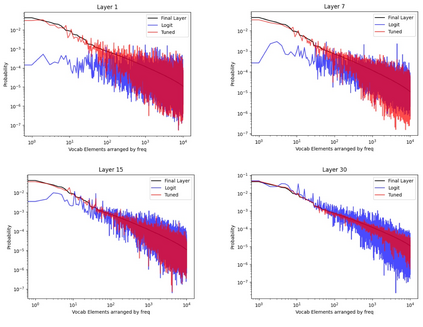
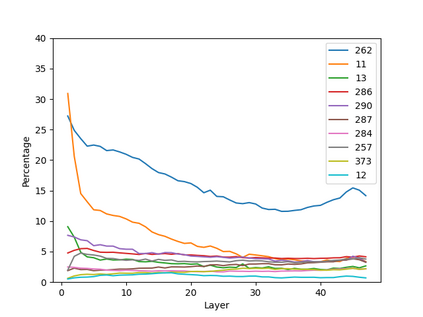
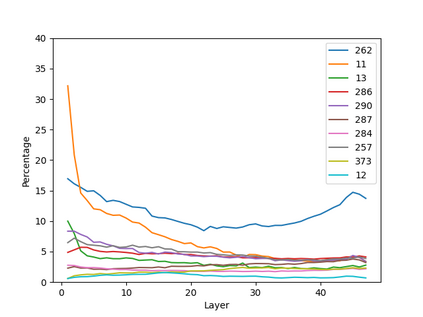
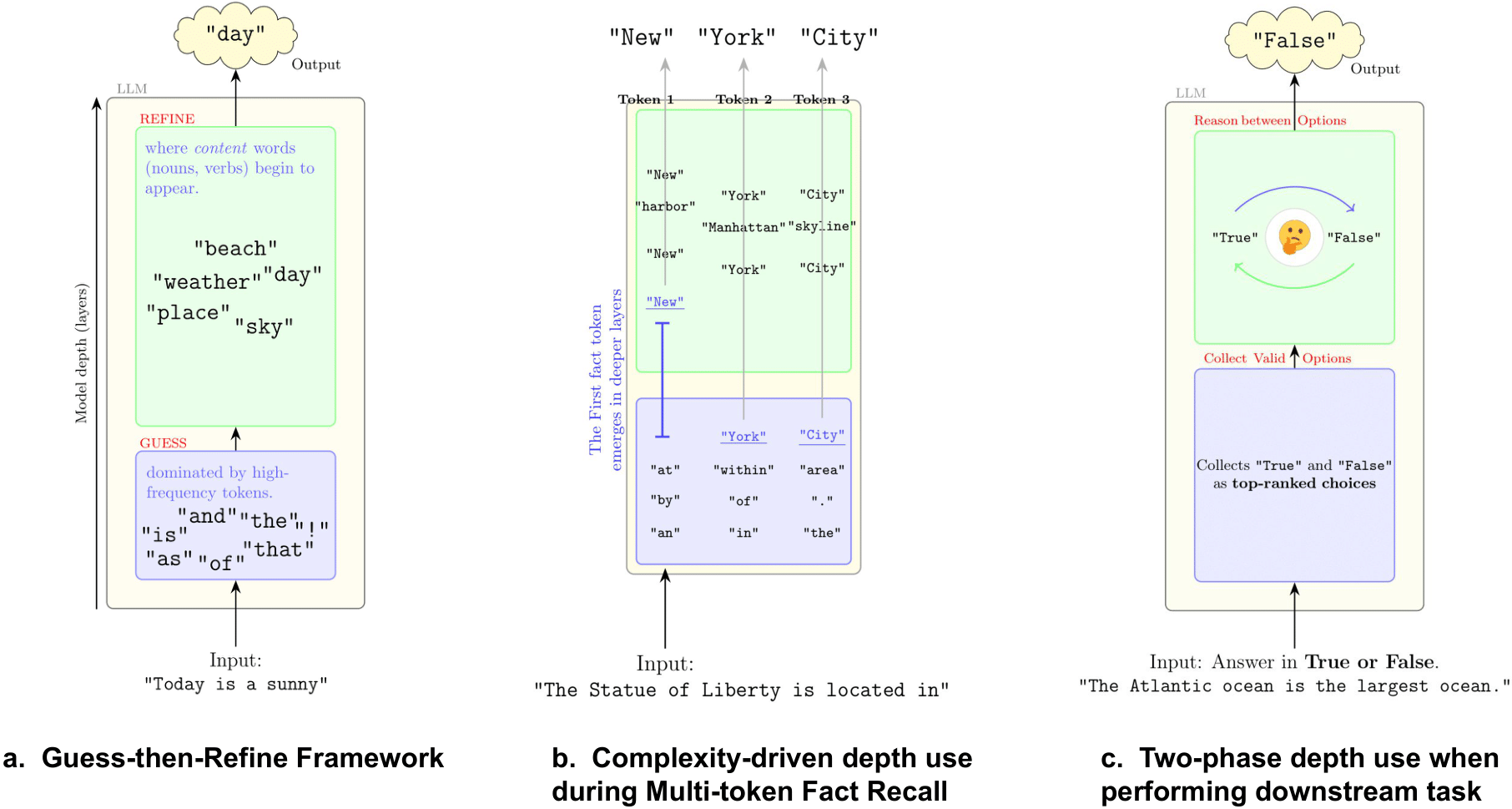
Growing evidence suggests that large language models do not use their depth uniformly, yet we still lack a fine-grained understanding of their layer-wise prediction dynamics. In this paper, we trace the intermediate representations of several open-weight models during inference and reveal a structured and nuanced use of depth. Specifically, we propose a "Guess-then-Refine" framework that explains how LLMs internally structure their computations to make predictions. We first show that the top-ranked predictions in early LLM layers are composed primarily of high-frequency tokens, which act as statistical guesses proposed by the model early on due to the lack of appropriate contextual information. As contextual information develops deeper into the model, these initial guesses get refined into contextually appropriate tokens. Even high-frequency token predictions from early layers get refined >70% of the time, indicating that correct token prediction is not "one-and-done". We then go beyond frequency-based prediction to examine the dynamic usage of layer depth across three case studies. (i) Part-of-speech analysis shows that function words are, on average, the earliest to be predicted correctly. (ii) Fact recall task analysis shows that, in a multi-token answer, the first token requires more computational depth than the rest. (iii) Multiple-choice task analysis shows that the model identifies the format of the response within the first half of the layers, but finalizes its response only toward the end. Together, our results provide a detailed view of depth usage in LLMs, shedding light on the layer-by-layer computations that underlie successful predictions and providing insights for future works to improve computational efficiency in transformer-based models.
翻译:暂无翻译