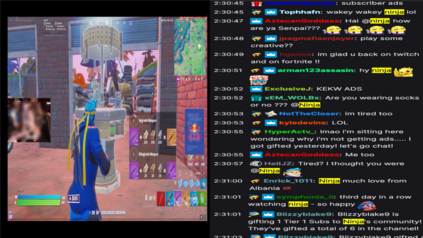
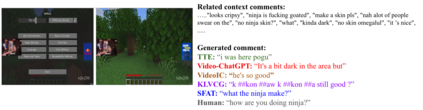
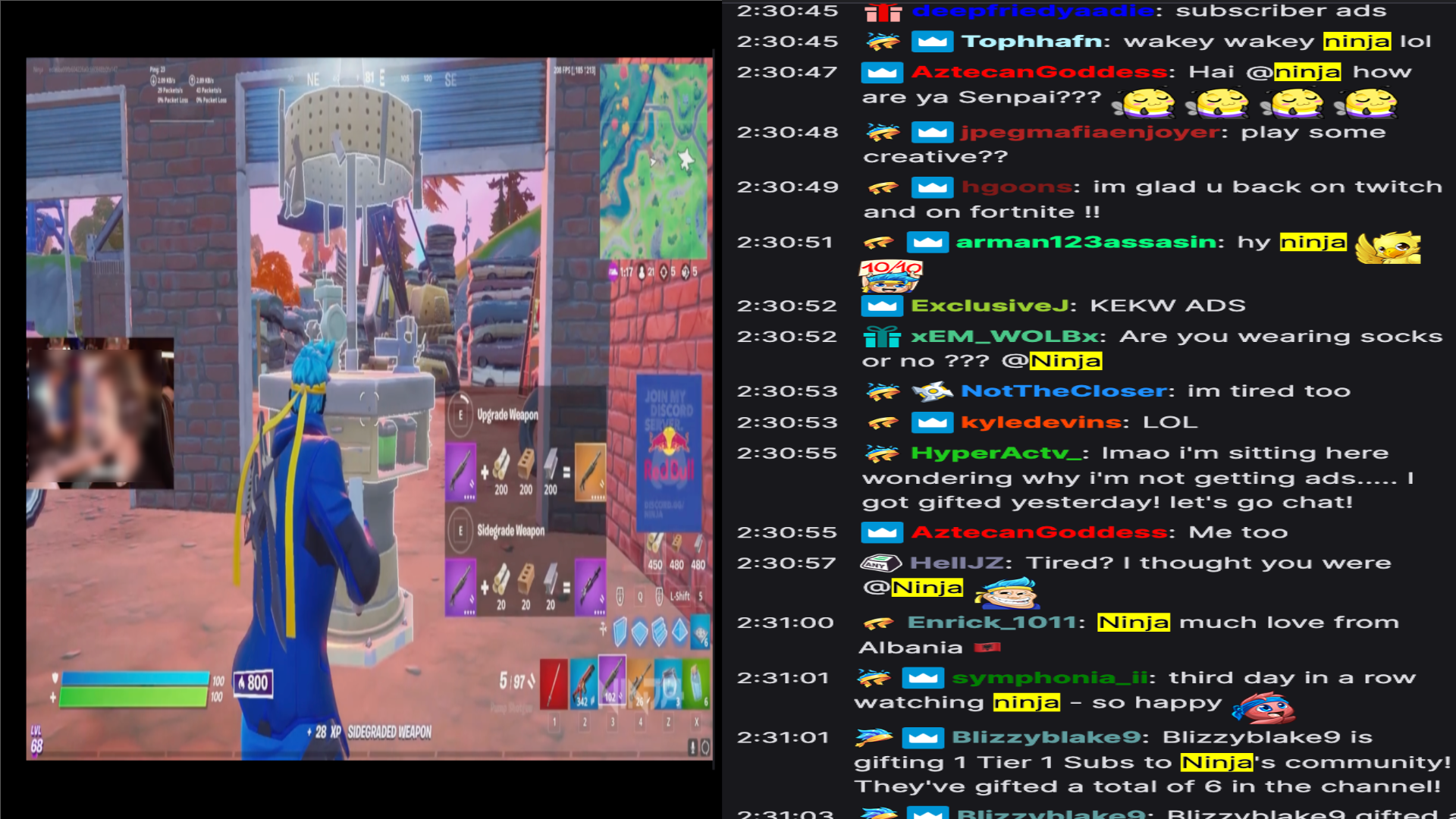
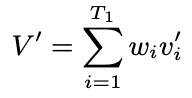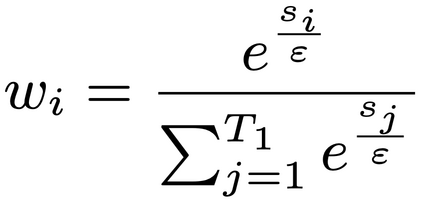Live commenting on video streams has surged in popularity on platforms like Twitch, enhancing viewer engagement through dynamic interactions. However, automatically generating contextually appropriate comments remains a challenging and exciting task. Video streams can contain a vast amount of data and extraneous content. Existing approaches tend to overlook an important aspect of prioritizing video frames that are most relevant to ongoing viewer interactions. This prioritization is crucial for producing contextually appropriate comments. To address this gap, we introduce a novel Semantic Frame Aggregation-based Transformer (SFAT) model for live video comment generation. This method not only leverages CLIP's visual-text multimodal knowledge to generate comments but also assigns weights to video frames based on their semantic relevance to ongoing viewer conversation. It employs an efficient weighted sum of frames technique to emphasize informative frames while focusing less on irrelevant ones. Finally, our comment decoder with a cross-attention mechanism that attends to each modality ensures that the generated comment reflects contextual cues from both chats and video. Furthermore, to address the limitations of existing datasets, which predominantly focus on Chinese-language content with limited video categories, we have constructed a large scale, diverse, multimodal English video comments dataset. Extracted from Twitch, this dataset covers 11 video categories, totaling 438 hours and 3.2 million comments. We demonstrate the effectiveness of our SFAT model by comparing it to existing methods for generating comments from live video and ongoing dialogue contexts.
翻译:暂无翻译