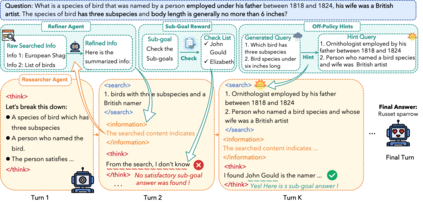
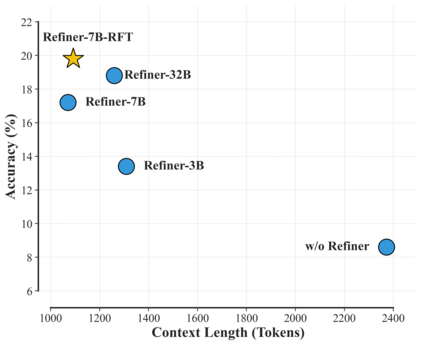
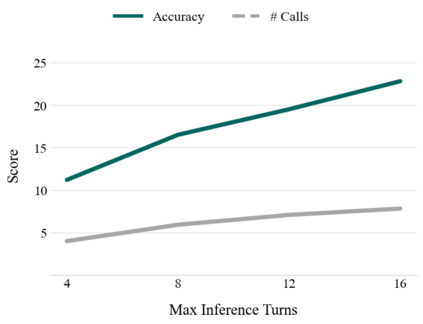
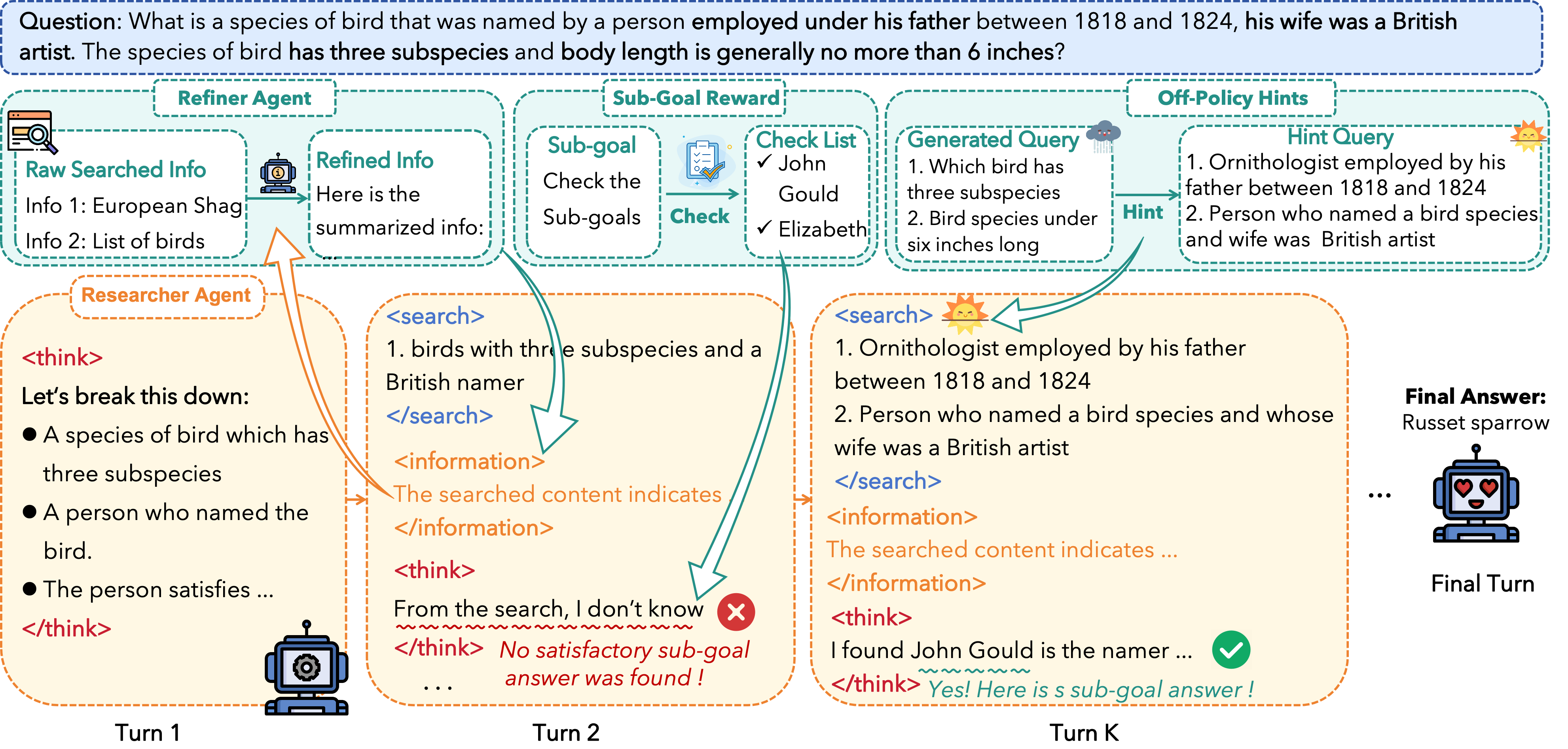
Reinforcement Learning with Verifiable Rewards (RLVR) is a promising approach for enhancing agentic deep search. However, its application is often hindered by low \textbf{Reward Density} in deep search scenarios, where agents expend significant exploratory costs for infrequent and often null final rewards. In this paper, we formalize this challenge as the \textbf{Reward Density Optimization} problem, which aims to improve the reward obtained per unit of exploration cost. This paper introduce \textbf{InfoFlow}, a systematic framework that tackles this problem from three aspects. 1) \textbf{Subproblem decomposition}: breaking down long-range tasks to assign process rewards, thereby providing denser learning signals. 2) \textbf{Failure-guided hints}: injecting corrective guidance into stalled trajectories to increase the probability of successful outcomes. 3) \textbf{Dual-agent refinement}: employing a dual-agent architecture to offload the cognitive burden of deep exploration. A refiner agent synthesizes the search history, which effectively compresses the researcher's perceived trajectory, thereby reducing exploration cost and increasing the overall reward density. We evaluate InfoFlow on multiple agentic search benchmarks, where it significantly outperforms strong baselines, enabling lightweight LLMs to achieve performance comparable to advanced proprietary LLMs.
翻译:暂无翻译