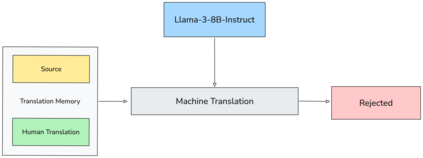
LLMs often require adaptation to domain-specific requirements, a process that can be expensive when relying solely on SFT. We present an empirical study on applying CPO to simulate a post-editing workflow for data-efficient domain adaptation. Our approach synthesizes preference pairs by treating the base model's own raw output as the 'rejected' translation and the human-approved TM entry as the 'chosen' one. This method provides direct feedback on the model's current knowledge, guiding it to align with domain-specific standards. Experiments in English-Brazilian Portuguese and English-Korean show that, by using just 14.7k preference pairs, the model achieves performance close to that of a model trained on 160k+ samples with SFT, demonstrating significant data efficiency. Although we showcase its effectiveness in MT, this application of CPO naturally generalizes to other generative tasks where a model's initial drafts can serve as a contrastive signal against a golden reference.
翻译:暂无翻译