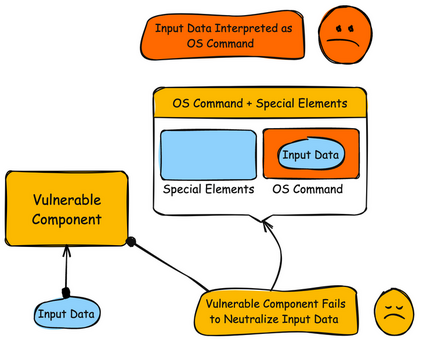
Although Large Language Models (LLMs) show promising solutions to automated code generation, they often produce insecure code that threatens software security. Current approaches (e.g., SafeCoder) to improve secure code generation suffer from limited and imbalanced datasets, reducing their effectiveness and generalizability. In this work, we present Secure-Instruct, a novel framework that automatically synthesizes high-quality vulnerable and secure code examples, generates fine-tuning instructions, and instruction-tunes LLMs to align task description and secure code generation abilities. We evaluate Secure-Instruct on four representative LLMs using two benchmarks: our own CWEBench and the existing CWEval. CWEBench comprises 93 scenarios on 44 CWEs, all without overlap with Secure-Instruct's synthetic instruction-tuning dataset, while CWEval covers 31 CWEs with 119 manually verified security-critical tasks. We find that Secure-Instruct improves not only the security but also the functional correctness of the generated code. On CWEBench, Secure-Instruct substantially improves secure code generation, giving a 14.3% average increase in secure ratio over the pretrained models and outperforms SafeCoder by 7.6%. On CWEval, Secure-Instruct achieves a 14% increase for CodeLlama-7B and 5.8% for Mistral-7B in Func-Sec@1 over pretrained models, and surpasses SafeCoder by 15.8% and 6.8% respectively.
翻译:暂无翻译