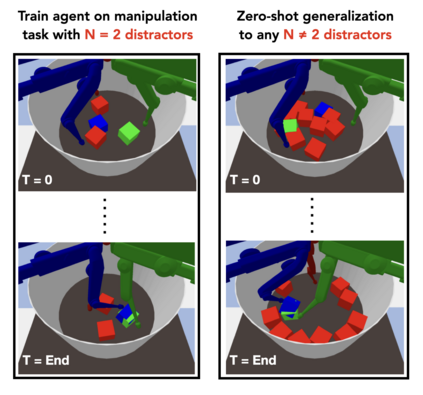
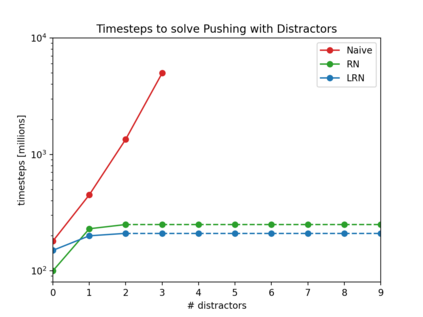
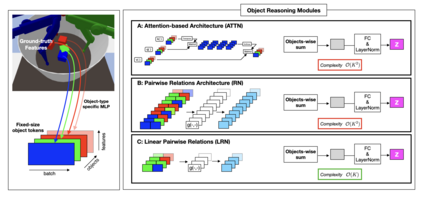
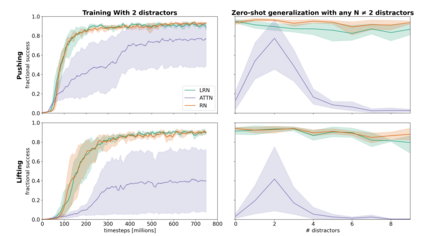
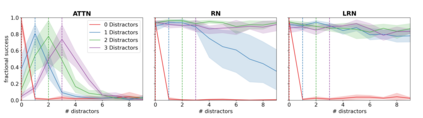
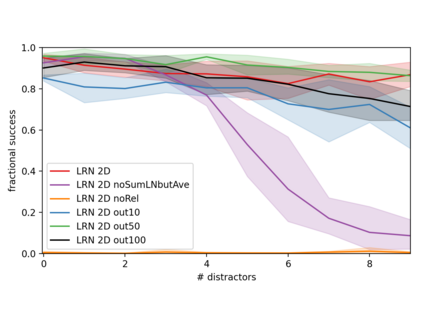
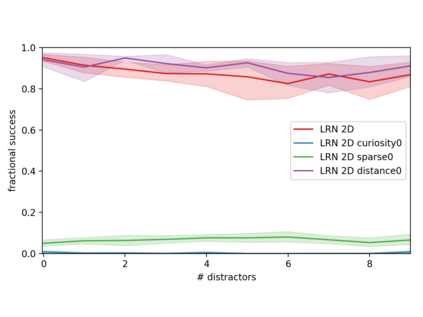
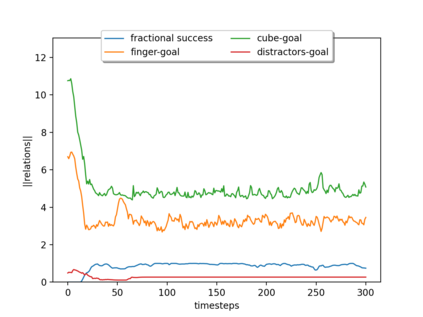
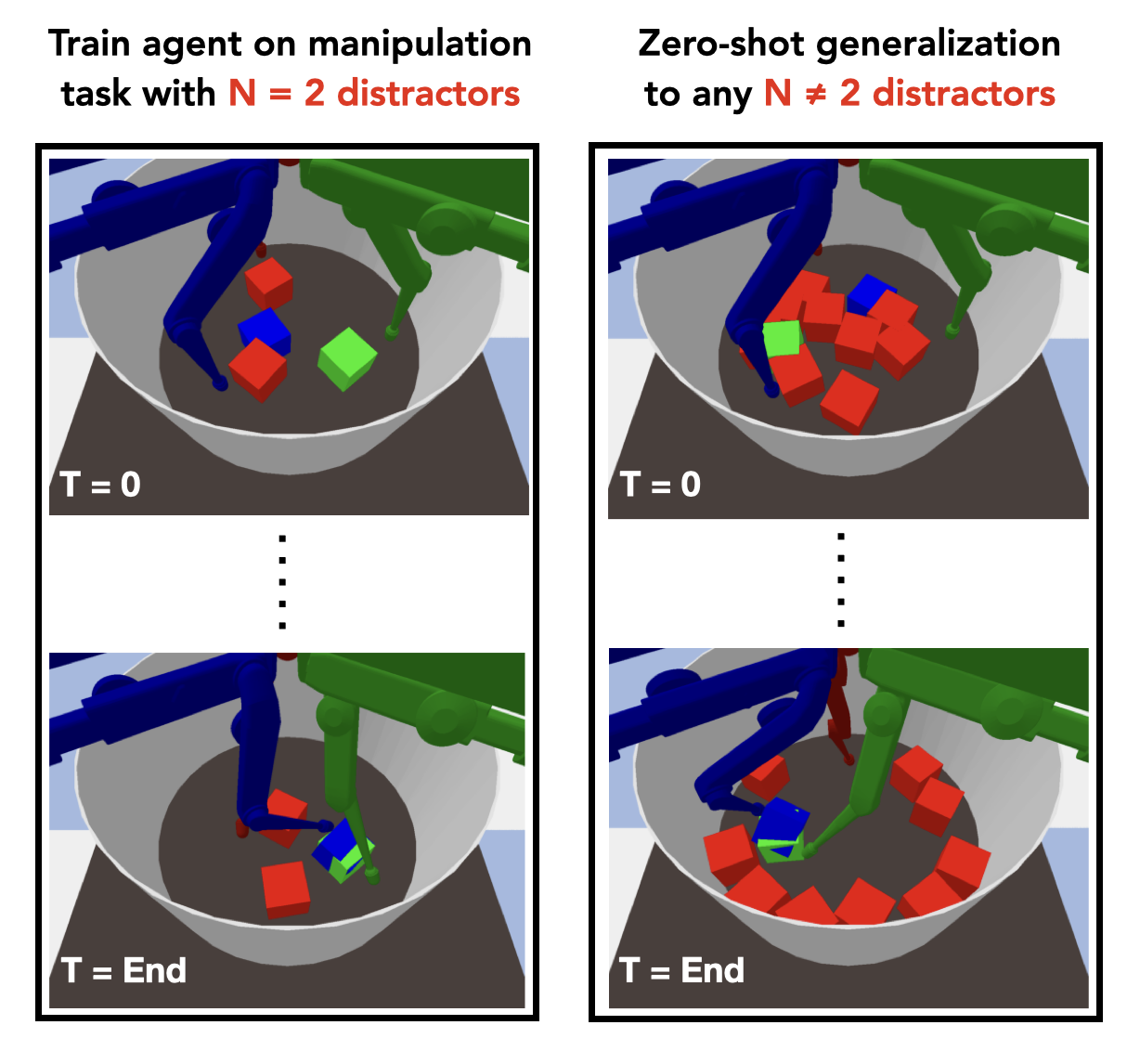
Although reinforcement learning has seen remarkable progress over the last years, solving robust dexterous object-manipulation tasks in multi-object settings remains a challenge. In this paper, we focus on models that can learn manipulation tasks in fixed multi-object settings and extrapolate this skill zero-shot without any drop in performance when the number of objects changes. We consider the generic task of bringing a specific cube out of a set to a goal position. We find that previous approaches, which primarily leverage attention and graph neural network-based architectures, do not generalize their skills when the number of input objects changes while scaling as $K^2$. We propose an alternative plug-and-play module based on relational inductive biases to overcome these limitations. Besides exceeding performances in their training environment, we show that our approach, which scales linearly in $K$, allows agents to extrapolate and generalize zero-shot to any new object number.
翻译:虽然加强学习在过去几年里取得了显著进展,但解决多目标设置中强力的超脱天体管理任务仍是一项挑战。在本文中,我们侧重于能够在固定多目标设置中学习操作任务的模型,并在物体数量变化时不降低性能,就推断出这种技能零弹跳,不出现任何下降。我们考虑将一组特定立方体带到目标位置的一般性任务。我们发现,以往的做法,主要是利用注意力和图形神经网络结构,在输入对象数量在以 $K$2 递增的同时发生变化时,不会将其技能概括化。我们建议了基于关联导引导偏差的替代插件模块,以克服这些限制。我们除了在培训环境中超过性能外,还展示了我们的方法,即用$的线缩放,允许代理人将零弹射外推到任何新的对象数字中。