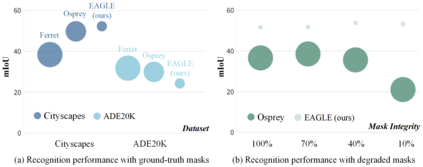
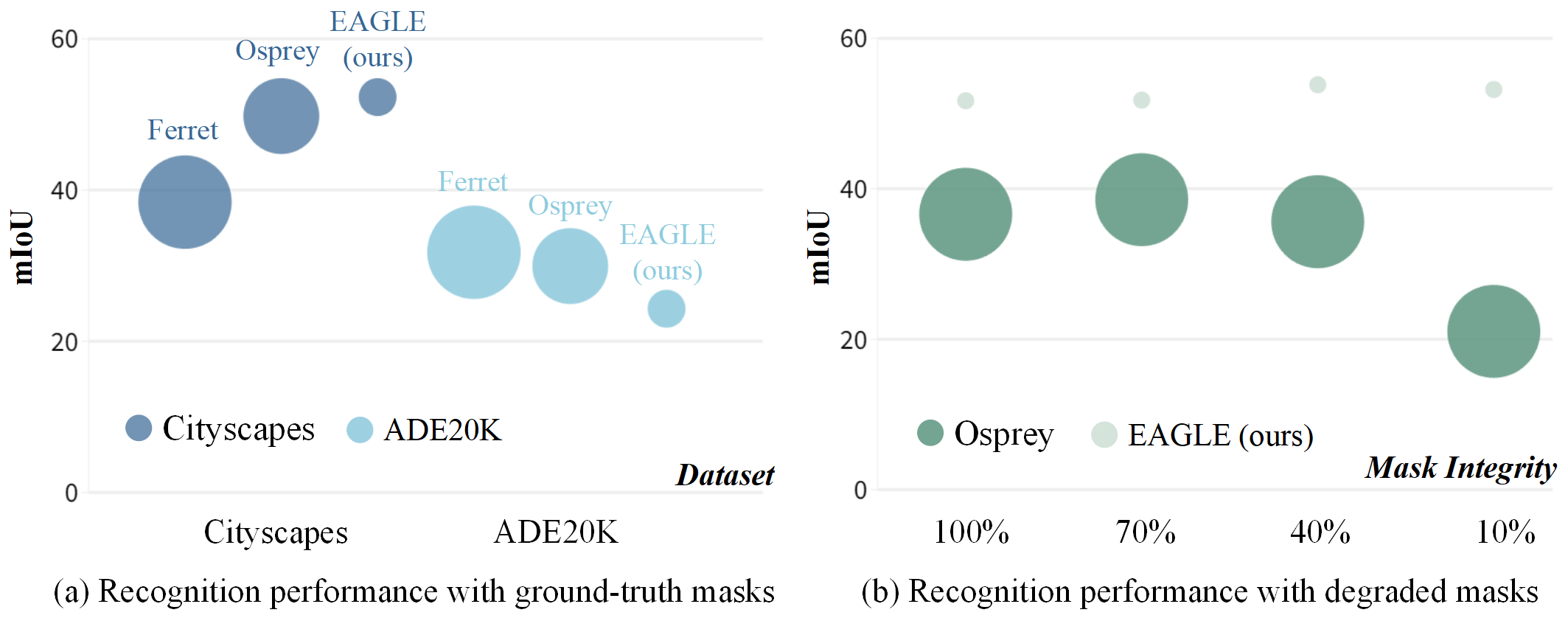
Recently, Multimodal Large Language Models (MLLMs) have sparked great research interests owing to their exceptional content-reasoning and instruction-following capabilities. To effectively instruct an MLLM, in addition to conventional language expressions, the practice of referring to objects by painting with brushes on images has emerged as a prevalent tool (referred to as "referring visual prompts") due to its efficacy in aligning the user's intention with specific image regions. To accommodate the most common referring visual prompts, namely points, boxes, and masks, existing approaches initially utilize specialized feature encoding modules to capture the semantics of the highlighted areas indicated by these prompts. Subsequently, these encoded region features are adapted to MLLMs through fine-tuning on a meticulously curated multimodal instruction dataset. However, such designs suffer from redundancy in architecture. Moreover, they face challenges in effectively generalizing when encountering a diverse range of arbitrary referring visual prompts in real-life scenarios. To address the above issues, we propose EAGLE, a novel MLLM that empowers comprehension of arbitrary referring visual prompts with less training efforts than existing approaches. Specifically, our EAGLE maintains the innate format of the referring visual prompts as colored patches rendered on the given image for conducting the instruction tuning. Our approach embeds referring visual prompts as spatial concepts conveying specific spatial areas comprehensible to the MLLM, with the semantic comprehension of these regions originating from the MLLM itself. Besides, we also propose a Geometry-Agnostic Learning paradigm (GAL) to further disentangle the MLLM's region-level comprehension with the specific formats of referring visual prompts. Extensive experiments are conducted to prove the effectiveness of our proposed method.
翻译:暂无翻译