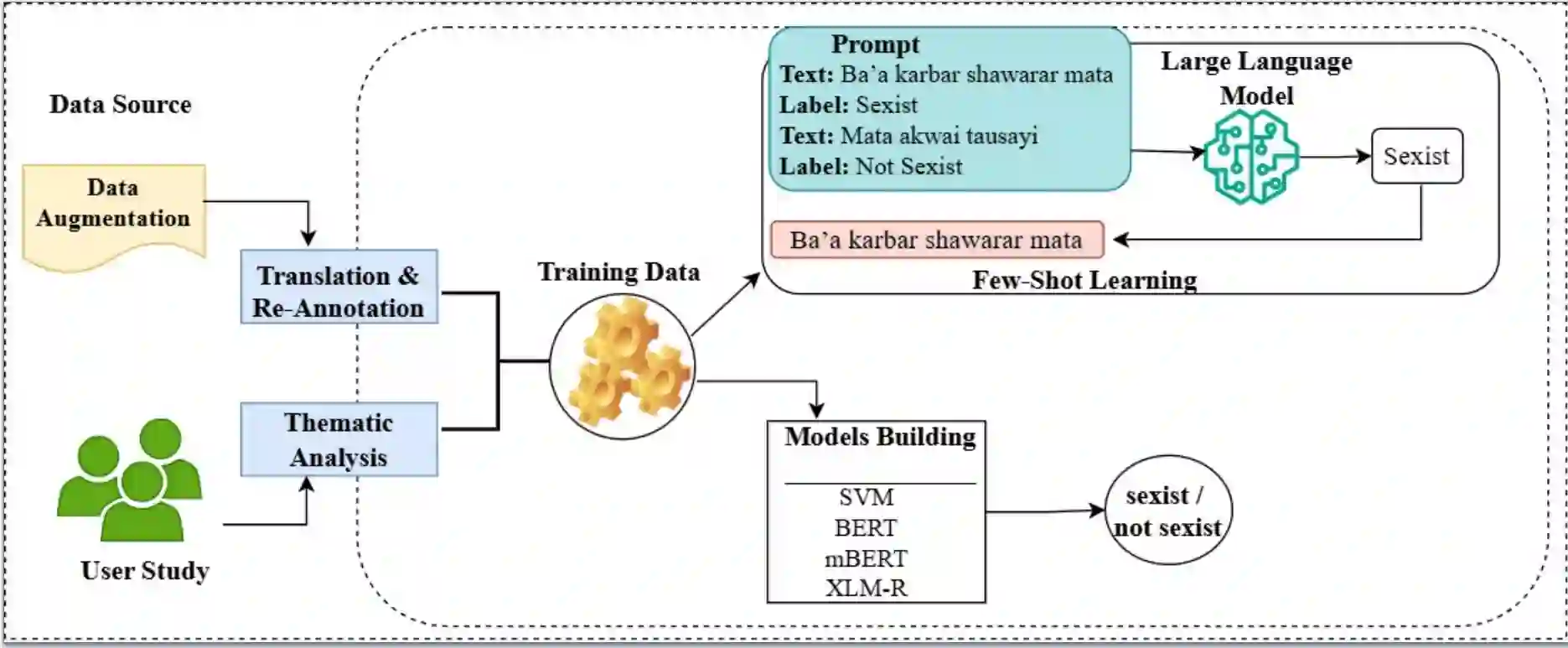
Sexism reinforces gender inequality and social exclusion by perpetuating stereotypes, bias, and discriminatory norms. Noting how online platforms enable various forms of sexism to thrive, there is a growing need for effective sexism detection and mitigation strategies. While computational approaches to sexism detection are widespread in high-resource languages, progress remains limited in low-resource languages where limited linguistic resources and cultural differences affect how sexism is expressed and perceived. This study introduces the first Hausa sexism detection dataset, developed through community engagement, qualitative coding, and data augmentation. For cultural nuances and linguistic representation, we conducted a two-stage user study (n=66) involving native speakers to explore how sexism is defined and articulated in everyday discourse. We further experiment with both traditional machine learning classifiers and pre-trained multilingual language models and evaluating the effectiveness few-shot learning in detecting sexism in Hausa. Our findings highlight challenges in capturing cultural nuance, particularly with clarification-seeking and idiomatic expressions, and reveal a tendency for many false positives in such cases.
翻译:性别歧视通过固化刻板印象、偏见和歧视性规范,加剧了性别不平等与社会排斥。鉴于网络平台助长了多种形式的性别歧视蔓延,对有效的性别歧视检测与缓解策略的需求日益增长。尽管在高资源语言中,性别歧视检测的计算方法已广泛应用,但在低资源语言中进展依然有限——这些语言因资源匮乏及文化差异,影响了性别歧视的表达与感知方式。本研究首次引入了通过社区参与、质性编码与数据增强构建的豪萨语性别歧视检测数据集。为捕捉文化细微差异与语言表征,我们开展了一项两阶段用户研究(n=66),邀请母语者探讨日常话语中性别歧视的定义与表达方式。进一步地,我们实验了传统机器学习分类器与预训练多语言模型,并评估了少样本学习在豪萨语性别歧视检测中的有效性。研究结果凸显了捕捉文化细微差异的挑战,尤其在涉及澄清性询问与惯用表达时,并揭示了此类情况下易产生大量误判的倾向。