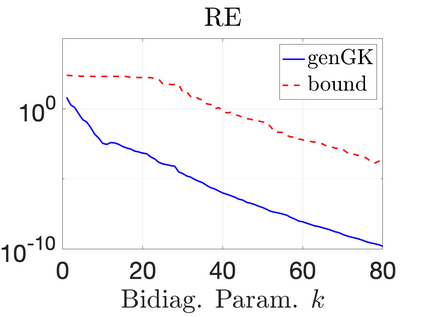
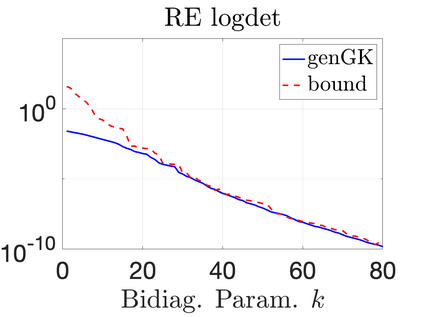
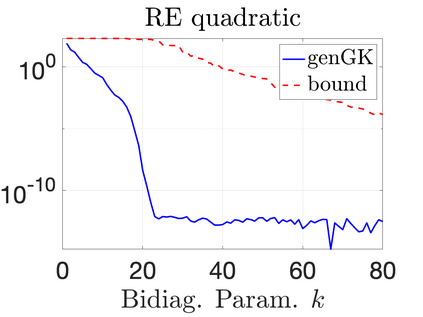
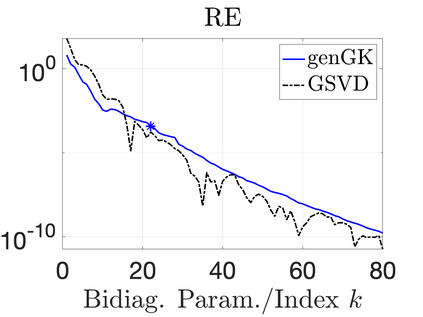
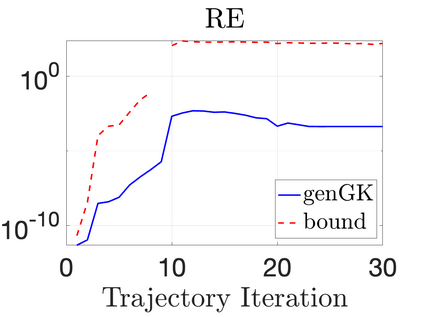
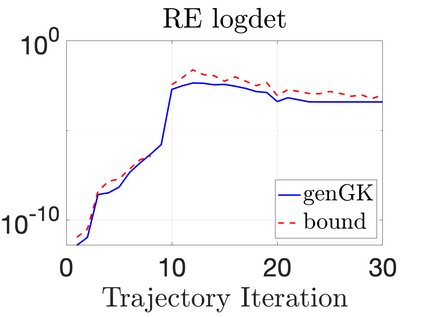
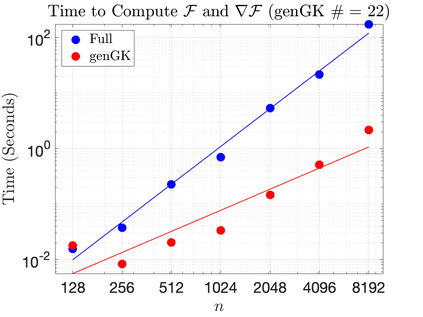
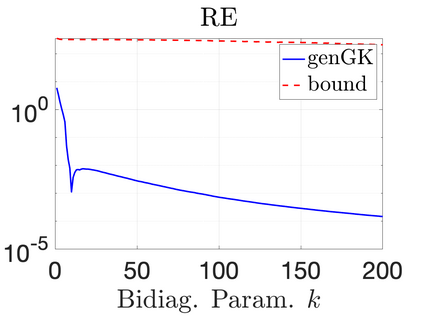
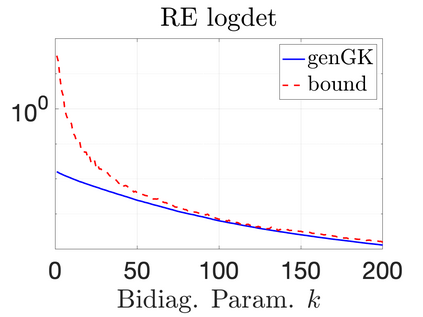
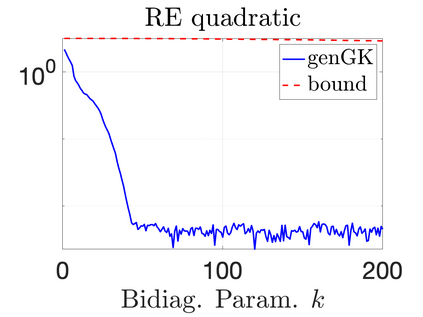
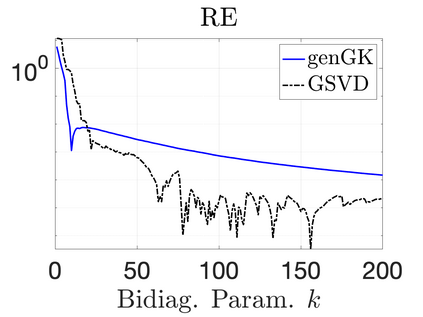
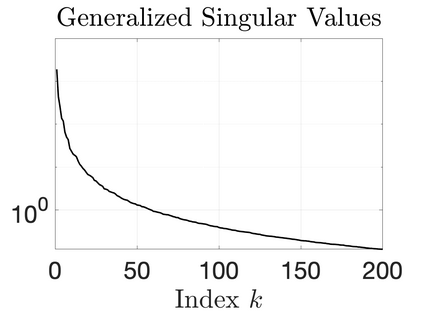
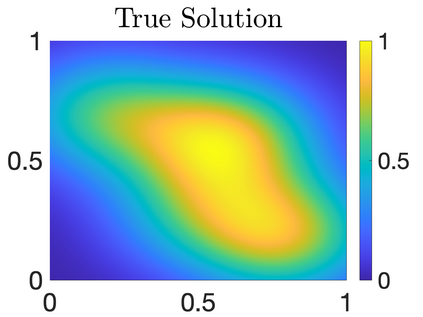
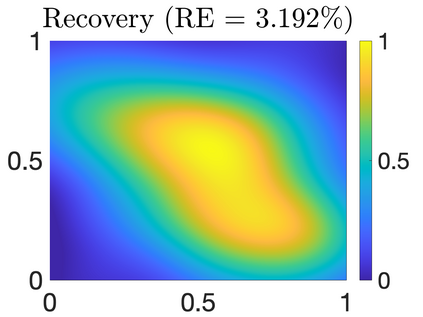
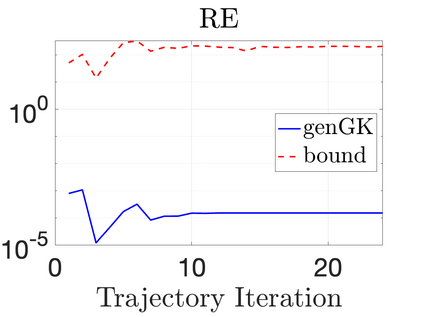
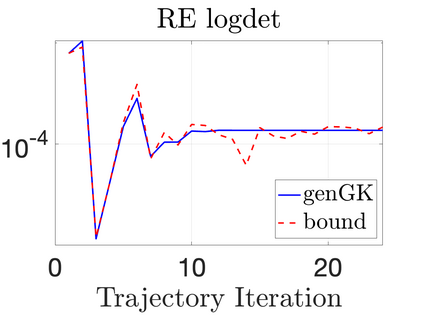
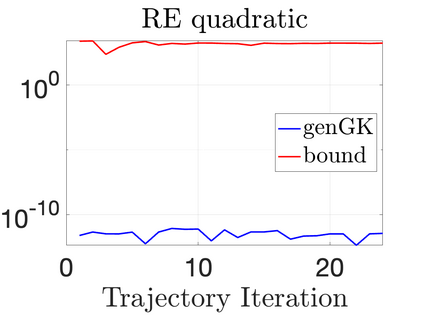
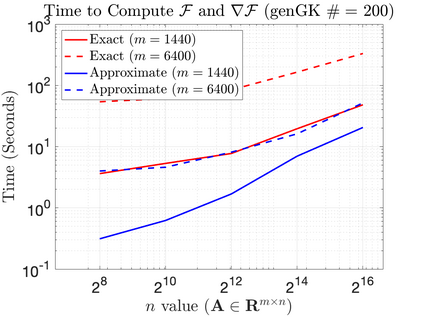
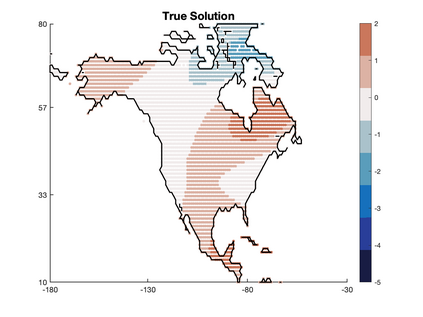
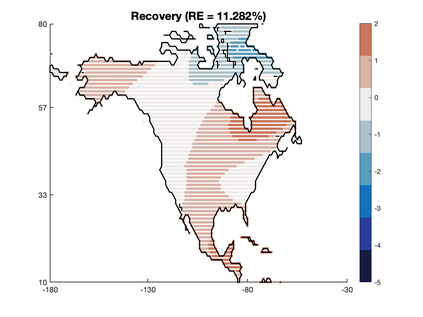
We study Bayesian methods for large-scale linear inverse problems, focusing on the challenging task of hyperparameter estimation. Typical hierarchical Bayesian formulations that follow a Markov Chain Monte Carlo approach are possible for small problems with very few hyperparameters but are not computationally feasible for problems with a very large number of unknown parameters. In this work, we describe an empirical Bayesian (EB) method to estimate hyperparameters that maximize the marginal posterior, i.e., the probability density of the hyperparameters conditioned on the data, and then we use the estimated values to compute the posterior of the inverse parameters. For problems where the computation of the square root and inverse of prior covariance matrices are not feasible, we describe an approach based on the generalized Golub-Kahan bidiagonalization to approximate the marginal posterior and seek hyperparameters that minimize the approximate marginal posterior. Numerical results from seismic and atmospheric tomography demonstrate the accuracy, robustness, and potential benefits of the proposed approach.
翻译:暂无翻译