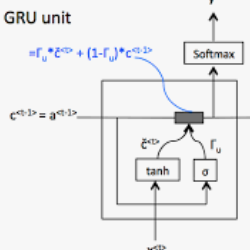
Audio-visual navigation represents a significant area of research in which intelligent agents utilize egocentric visual and auditory perceptions to identify audio targets. Conventional navigation methodologies typically adopt a staged modular design, which involves first executing feature fusion, then utilizing Gated Recurrent Unit (GRU) modules for sequence modeling, and finally making decisions through reinforcement learning. While this modular approach has demonstrated effectiveness, it may also lead to redundant information processing and inconsistencies in information transmission between the various modules during the feature fusion and GRU sequence modeling phases. This paper presents IRCAM-AVN (Iterative Residual Cross-Attention Mechanism for Audiovisual Navigation), an end-to-end framework that integrates multimodal information fusion and sequence modeling within a unified IRCAM module, thereby replacing the traditional separate components for fusion and GRU. This innovative mechanism employs a multi-level residual design that concatenates initial multimodal sequences with processed information sequences. This methodological shift progressively optimizes the feature extraction process while reducing model bias and enhancing the model's stability and generalization capabilities. Empirical results indicate that intelligent agents employing the iterative residual cross-attention mechanism exhibit superior navigation performance.
翻译:暂无翻译