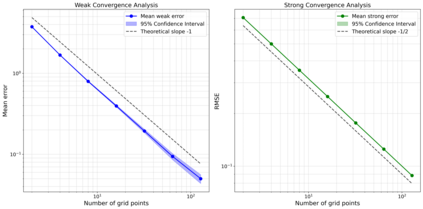
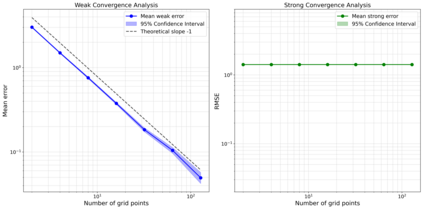
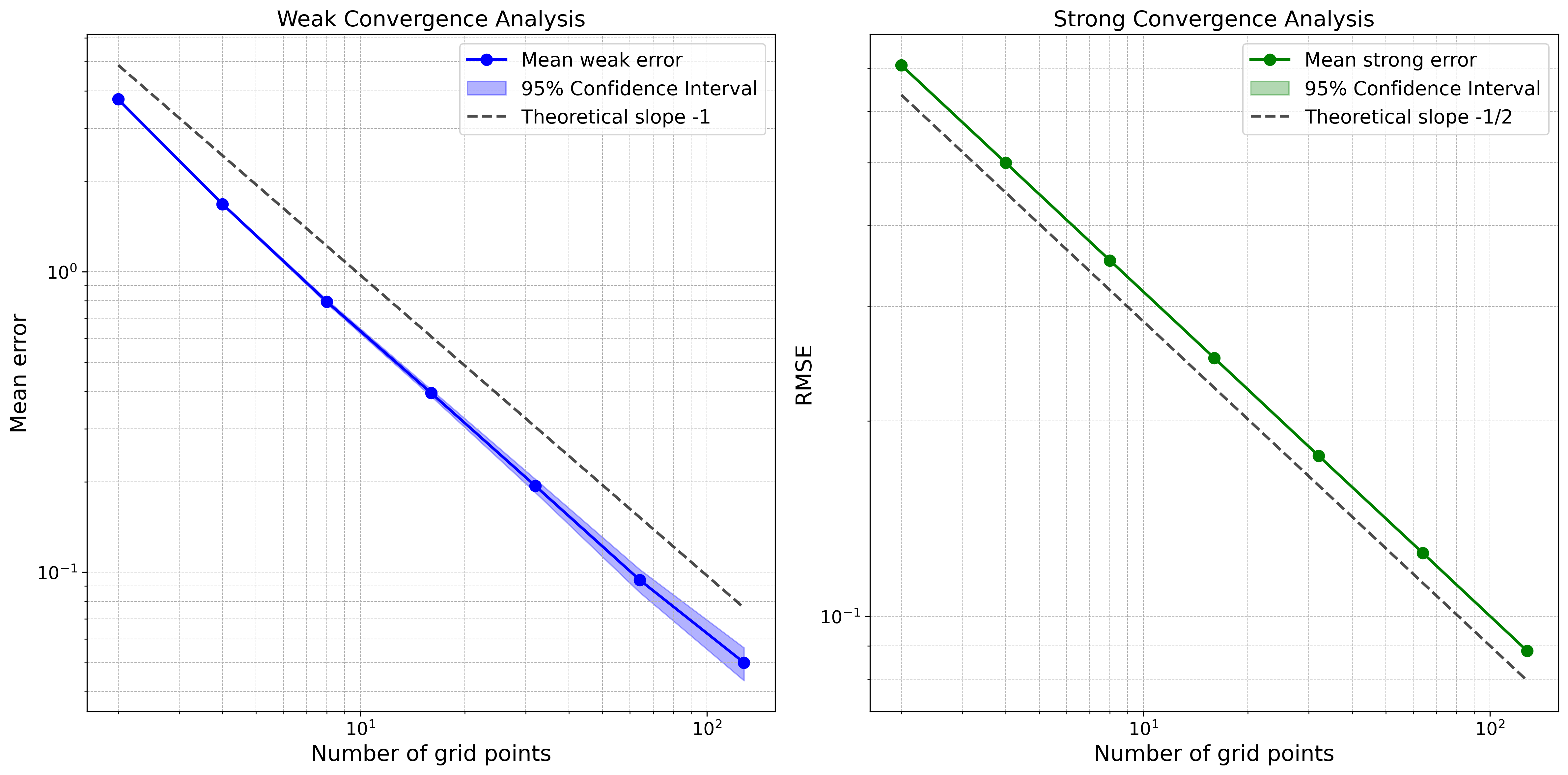
Stochastic policies (also known as relaxed controls) are widely used in continuous-time reinforcement learning algorithms. However, executing a stochastic policy and evaluating its performance in a continuous-time environment remain open challenges. This work introduces and rigorously analyzes a policy execution framework that samples actions from a stochastic policy at discrete time points and implements them as piecewise constant controls. We prove that as the sampling mesh size tends to zero, the controlled state process converges weakly to the dynamics with coefficients aggregated according to the stochastic policy. We explicitly quantify the convergence rate based on the regularity of the coefficients and establish an optimal first-order convergence rate for sufficiently regular coefficients. Additionally, we prove a $1/2$-order weak convergence rate that holds uniformly over the sampling noise with high probability, and establish a $1/2$-order pathwise convergence for each realization of the system noise in the absence of volatility control. Building on these results, we analyze the bias and variance of various policy evaluation and policy gradient estimators based on discrete-time observations. Our results provide theoretical justification for the exploratory stochastic control framework in [H. Wang, T. Zariphopoulou, and X.Y. Zhou, J. Mach. Learn. Res., 21 (2020), pp. 1-34].
翻译:暂无翻译