
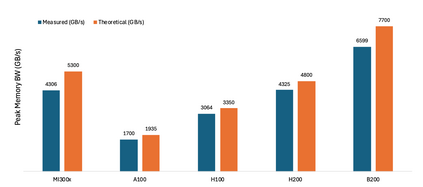
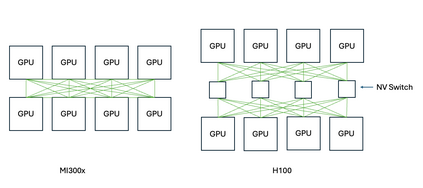
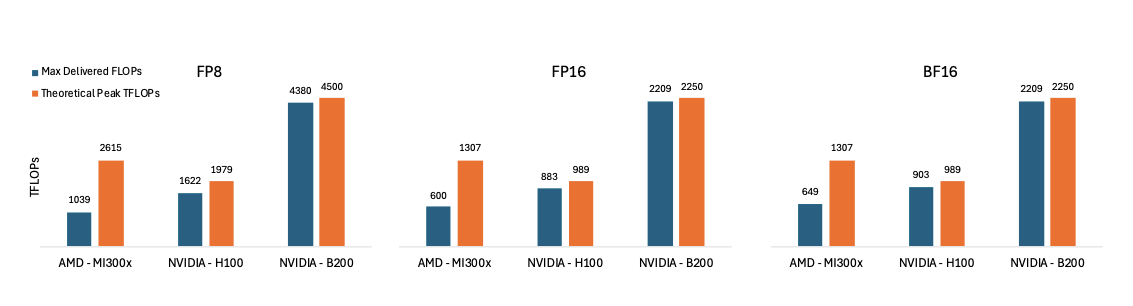
The rapid growth of large language models (LLMs) has driven the need for high-performance, scalable GPU hardware capable of efficiently serving models with hundreds of billions of parameters. While NVIDIA GPUs have traditionally dominated LLM deployments due to their mature CUDA software stack and state-of the-art accelerators, AMD's latest MI300X GPUs offer a compelling alternative, featuring high HBM capacity, matrix cores, and their proprietary interconnect. In this paper, we present a comprehensive evaluation of the AMD MI300X GPUs across key performance domains critical to LLM inference including compute throughput, memory bandwidth, and interconnect communication.
翻译:暂无翻译


相关内容

专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日

相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文