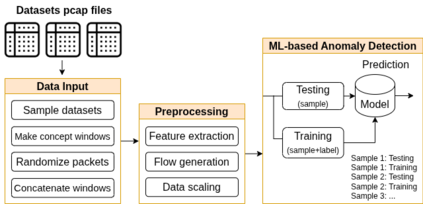
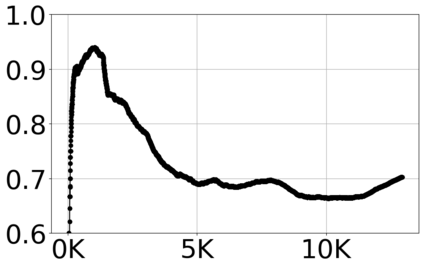
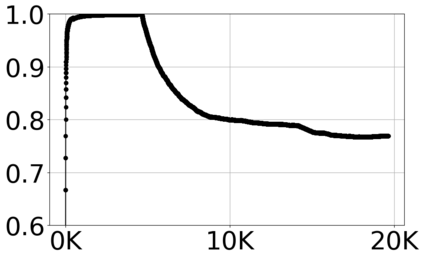
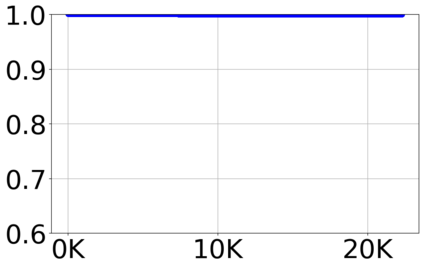
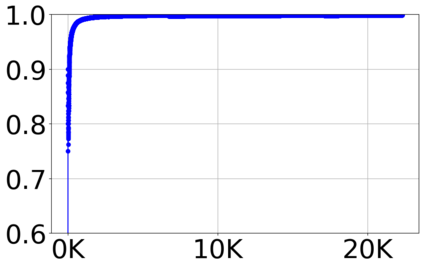
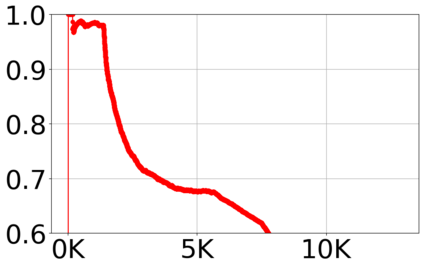
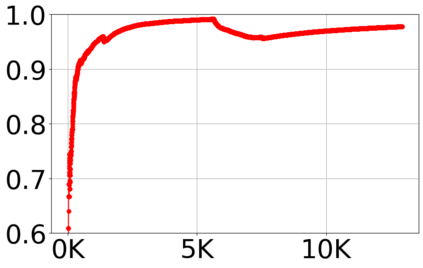
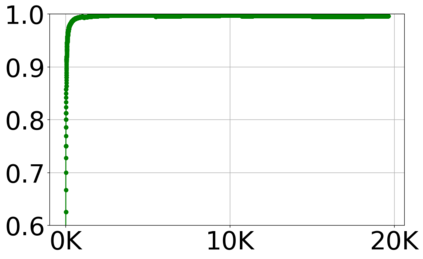
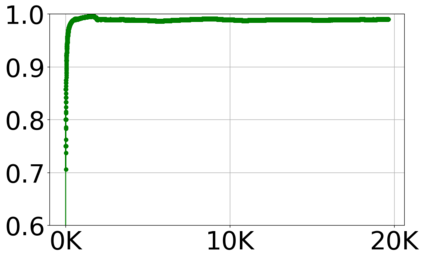
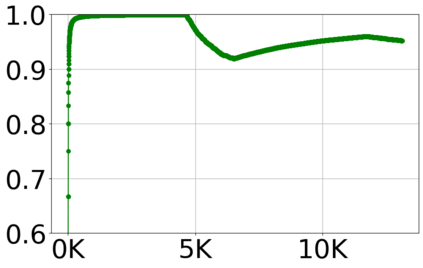
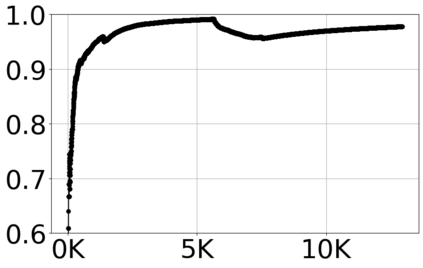
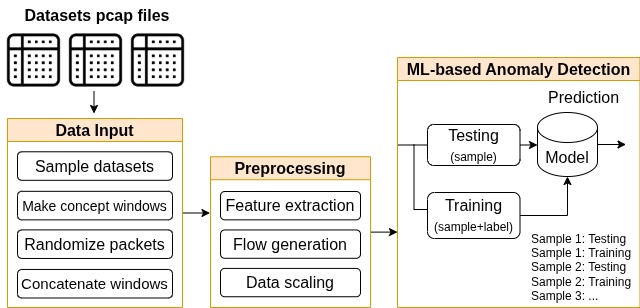
With the growing volume of Internet of Things (IoT) network traffic, machine learning (ML)-based anomaly detection is more relevant than ever. Traditional batch learning models face challenges such as high maintenance and poor adaptability to rapid anomaly changes, known as concept drift. In contrast, streaming learning integrates online and incremental learning, enabling seamless updates and concept drift detection to improve robustness. This study investigates anomaly detection in streaming IoT traffic as binary classification, comparing batch and streaming learning approaches while assessing the limitations of current IoT traffic datasets. We simulated heterogeneous network data streams by carefully mixing existing datasets and streaming the samples one by one. Our results highlight the failure of batch models to handle concept drift, but also reveal persisting limitations of current datasets to expose model limitations due to low traffic heterogeneity. We also investigated the competitiveness of tree-based ML algorithms, well-known in batch anomaly detection, and compared it to non-tree-based ones, confirming the advantages of the former. Adaptive Random Forest achieved F1-score of 0.990 $\pm$ 0.006 at one-third the computational cost of its batch counterpart. Hoeffding Adaptive Tree reached F1-score of 0.910 $\pm$ 0.007, reducing computational cost by four times, making it a viable choice for online applications despite a slight trade-off in stability.
翻译:暂无翻译