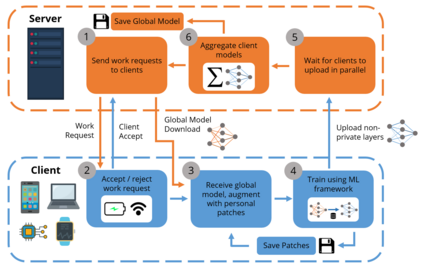
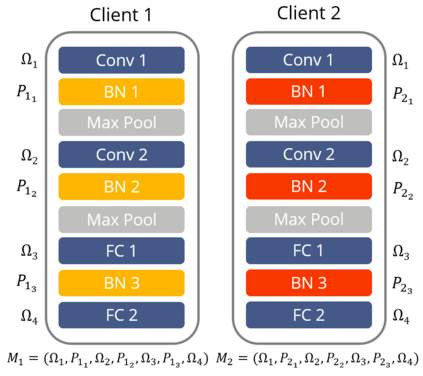
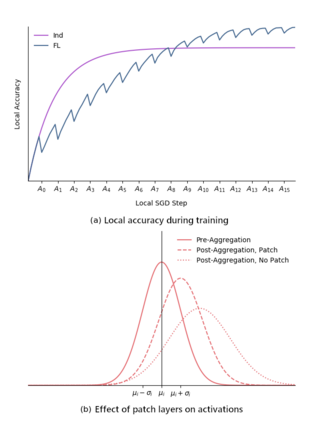
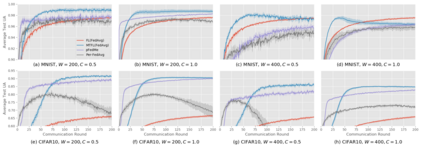
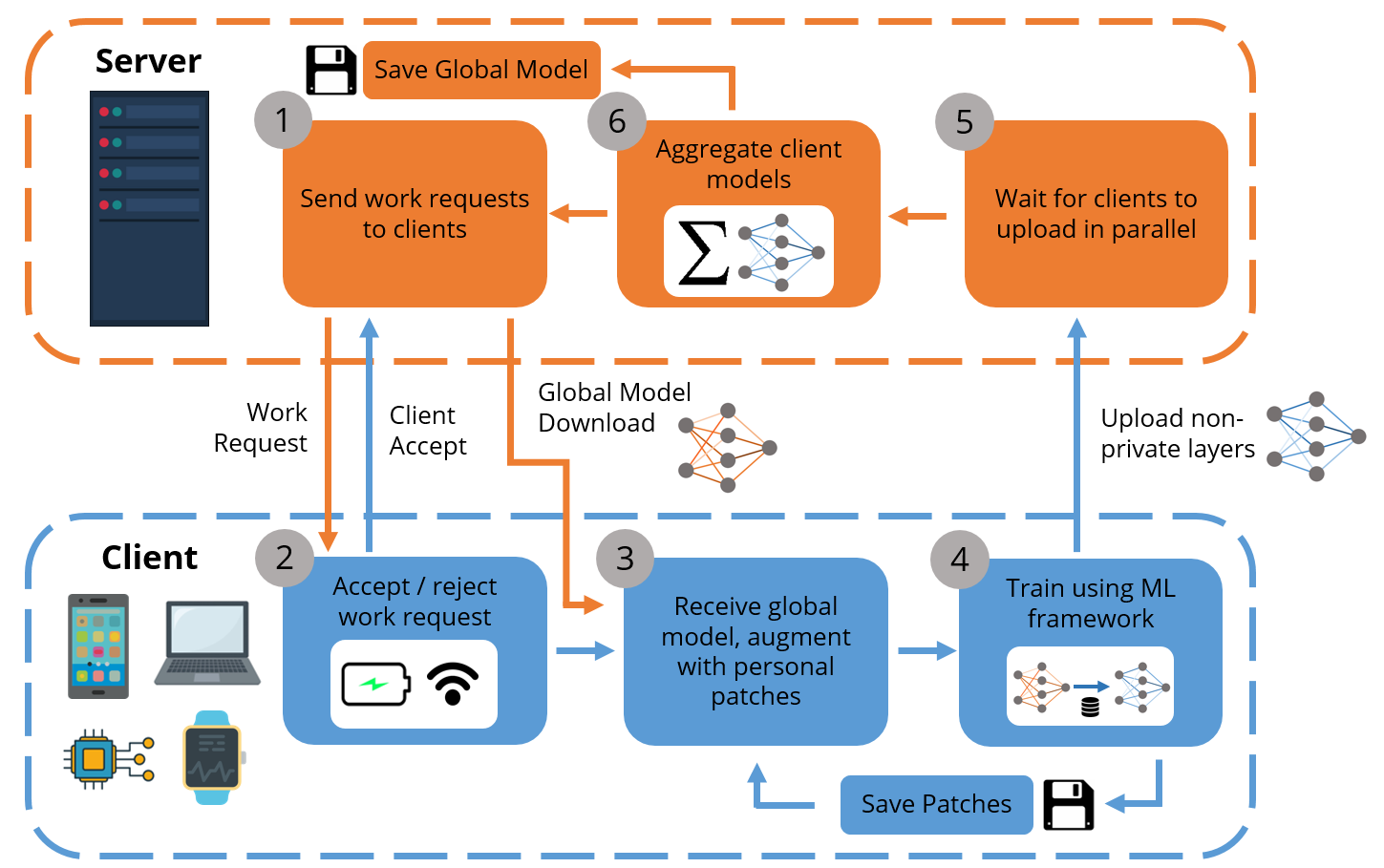
Federated Learning (FL) is an emerging approach for collaboratively training Deep Neural Networks (DNNs) on mobile devices, without private user data leaving the devices. Previous works have shown that non-Independent and Identically Distributed (non-IID) user data harms the convergence speed of the FL algorithms. Furthermore, most existing work on FL measures global-model accuracy, but in many cases, such as user content-recommendation, improving individual User model Accuracy (UA) is the real objective. To address these issues, we propose a Multi-Task FL (MTFL) algorithm that introduces non-federated Batch-Normalization (BN) layers into the federated DNN. MTFL benefits UA and convergence speed by allowing users to train models personalised to their own data. MTFL is compatible with popular iterative FL optimisation algorithms such as Federated Averaging (FedAvg), and we show empirically that a distributed form of Adam optimisation (FedAvg-Adam) benefits convergence speed even further when used as the optimisation strategy within MTFL. Experiments using MNIST and CIFAR10 demonstrate that MTFL is able to significantly reduce the number of rounds required to reach a target UA, by up to $5\times$ when using existing FL optimisation strategies, and with a further $3\times$ improvement when using FedAvg-Adam. We compare MTFL to competing personalised FL algorithms, showing that it is able to achieve the best UA for MNIST and CIFAR10 in all considered scenarios. Finally, we evaluate MTFL with FedAvg-Adam on an edge-computing testbed, showing that its convergence and UA benefits outweigh its overhead.
翻译:联邦学习联合会(FL)是合作培训移动设备深度神经网络(DNN)的新兴方法,没有私人用户数据,也没有留下设备。以前的工作表明,非独立和同发(非IID)用户数据会损害FL算法的趋同速度。此外,大部分关于FL的现有工作衡量全球模型的准确性,但在许多情况下,如用户内容建议,改进个人用户模型Accuila(UA)是真正的目标。为了解决这些问题,我们提议了一个多塔斯克FL(MTFL)算法,在FNN(非IID)中引入非联合的批发(BNB)层。 MTFL(非IID) 用户数据不利于FL(FL) 算法的趋同速度。MTFL(FA) 和FTFL(FA-A(FA)算法)算算法的分布式格式,我们比Adam(FAVAV-ADL(FA-ADL)算法更精确地将个人变异化(FA-A-AdFATFATFATFATFD)算算算算算得更快速化,当使用FATFAL(ML)的货币化战略时,而让FATFAL(FAL)变现其最精化战略更能能能化)变现时,让FAL(FFFT)变现时,而进一步显示FATFL)算算算算算算算算算算算算算算算算算算算算算算算算得更快。