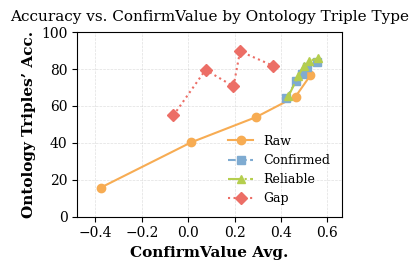
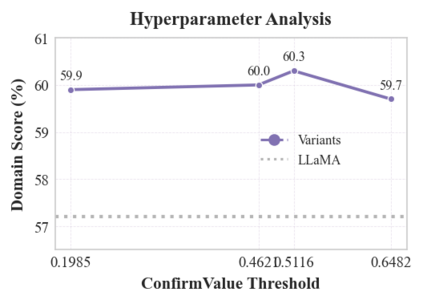
Large language models (LLMs) have demonstrated exceptional capabilities across multiple domains by leveraging massive pre-training and curated fine-tuning data. However, in data-sensitive fields such as healthcare, the lack of high-quality, domain-specific training corpus hinders LLMs' adaptation for specialized applications. Meanwhile, domain experts have distilled domain wisdom into ontology rules, which formalize relationships among concepts and ensure the integrity of knowledge management repositories. Viewing LLMs as implicit repositories of human knowledge, we propose Evontree, a novel framework that leverages a small set of high-quality ontology rules to systematically extract, validate, and enhance domain knowledge within LLMs, without requiring extensive external datasets. Specifically, Evontree extracts domain ontology from raw models, detects inconsistencies using two core ontology rules, and reinforces the refined knowledge via self-distilled fine-tuning. Extensive experiments on medical QA benchmarks with Llama3-8B-Instruct and Med42-v2 demonstrate consistent outperformance over both unmodified models and leading supervised baselines, achieving up to a 3.7% improvement in accuracy. These results confirm the effectiveness, efficiency, and robustness of our approach for low-resource domain adaptation of LLMs.
翻译:暂无翻译